
Last updated on 08th Oct 2025| 10361
- Introduction to Hadoop
- Big Data Challenges for Businesses
- Risks and Considerations
- Key Components of Hadoop
- Storing Data with HDFS
- Processing with MapReduce
- Use Cases by Industry
- Real-Time Analytics with Hive/Pig
- Integration with BI Tools
- Cost Efficiency of Hadoop
- Enterprise Adoption Stories
- Conclusion
Introduction to Hadoop
In today’s data-driven world, businesses are inundated with massive volumes of data generated from various sources, including social media, e-commerce platforms, sensors, and enterprise systems. Managing and extracting insights from this massive data commonly referred to as Big Data, requires a robust and scalable solution. In today’s data-driven world, managing vast information efficiently is crucial, and Hadoop big data solutions provide a scalable approach to this challenge. By leveraging distributed storage and processing, Hadoop big data frameworks, often covered in a Data Science course, allow businesses to handle massive volumes of diverse data types with ease. By distributing processing and storage duties among several computers, the Hadoop distributed system is built to manage enormous volumes of data. Apache Hadoop is an open-source framework that enables the distributed processing of large data sets across clusters of computers using simple programming models. Developed by the Apache Software Foundation, Hadoop has revolutionized the way organizations handle, store, and process data.
Big Data Challenges for Businesses
Businesses today face several challenges when it comes to managing big data:
- Volume: Massive amounts of data generated every second.
- Velocity: The speed at which data is produced and needs to be processed.
- Variety: Data comes in various formats structured, semi-structured, and unstructured.
- Veracity: Inconsistencies and uncertainties in data quality.
- Value: Extracting meaningful insights and actionable intelligence from raw data.
Traditional systems and relational databases struggle to cope with these challenges. Hadoop data processing divides tasks among several computers, allowing companies to analyse vast amounts of data effectively. Hadoop data processing makes complicated calculations on large data sets easier with the help of strong technologies like MapReduce, as explored in ‘How IBM InfoSphere Transforms Big Data This distributed Hadoop distributed system is perfect for big data problems because it guarantees scalability and fault tolerance. Businesses that use Hadoop data processing gain access to scalable, reasonably priced solutions that turn unprocessed data into insightful knowledge. The limitations in storage, computational power, and real-time processing demand a more efficient system, which is where Hadoop comes in. Companies that use the Hadoop distributed system may better manage, store, and analyse a variety of datasets with increased dependability and performance.
Do You Want to Learn More About Data Science? Get Info From Our Data Science Course Training Today!
Risks and Considerations
While Hadoop offers numerous benefits, it is not without challenges:
- Complexity : Requires technical expertise to set up and maintain.
- Security: Default security features are minimal; needs additional configuration.
- Latency: Not suitable for low-latency operations or real-time transactions.
- Data Governance: Managing access control and auditing across distributed systems can be tough.
Businesses must weigh these considerations carefully and plan their Hadoop deployments strategically.
Key Components of Hadoop
Hadoop is comprised of several core components that together facilitate efficient big data management:
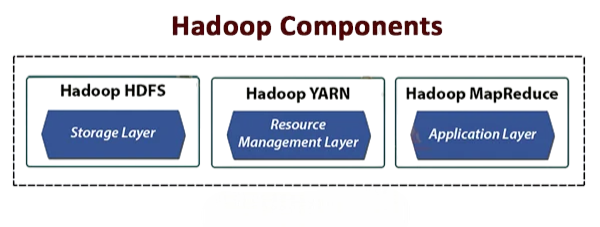
- HDFS (Hadoop Distributed File System) : Designed for storing vast amounts of data reliably by distributing it across multiple nodes.
- MapReduce : A programming model that allows for parallel processing of large data sets by dividing tasks into smaller subtasks, as demonstrated in ‘ 10 Real-Life Big Data Applications
- YARN (Yet Another Resource Negotiator) : Manages computing resources in clusters and schedules users’ applications.
- Common Utilities : Libraries and utilities that support other Hadoop modules.
- Scalability: Easily scale out by adding new nodes.
- Fault Tolerance: Replication ensures data is not lost even if a node fails.
- Cost-Effective: Uses commodity hardware for data storage.
- Map Phase: Takes input data and converts it into a set of key-value pairs.
- Reduce Phase: Merges those key-value pairs to provide the final output.
- Retail: Customer analytics, inventory management, and recommendation engines
- Finance: Fraud detection, risk modeling, and real-time transaction analysis.
- Healthcare: Patient data management, medical image processing, and genomics research.
- Telecom: Network performance monitoring and predictive maintenance.
- Government: Policy analytics, census data processing, and national security.
- Hive: Provides a SQL-like interface to query data stored in HDFS. Ideal for data analysts who are familiar with SQL.
- Pig: Offers a scripting language called Pig Latin for creating MapReduce programs. Preferred for its data flow language style.
- Create dashboards and reports directly from big data sources.
- Perform ad-hoc queries without needing to move data.
- Visualize trends and make data-driven decisions in real-time.
- Open Source : No licensing fees.
- Horizontal Scalability : Add more machines as needed instead of upgrading existing ones.
- Cloud Compatibility : Easily deploy on platforms like AWS, Azure, and GCP.
- Facebook : Uses Hadoop to store and process petabytes of user activity data
- LinkedIn : Utilizes Hadoop for real-time analytics and recommendation systems.
- Netflix: Processes streaming data to provide personalized content recommendations.
- Twitter: Manages billions of tweets and user interactions with Hadoop clusters.
These components work in tandem to allow businesses to store, process, and analyze big data seamlessly.
Would You Like to Know More About Data Science? Sign Up For Our Data Science Course Training Now!
Storing Data with HDFS
HDFS is the backbone of Hadoop’s storage system. Businesses must use effective data analytics in order to extract insightful information from massive datasets. Effective data storage is essential for companies handling massive amounts of data, a concept highlighted in Accelerating Big Data. It divides large data files into blocks (usually 128MB or 256MB in size) and distributes them across multiple nodes in a cluster. Each block is replicated across different nodes to ensure fault tolerance.
Companies can thus store petabytes of data without investing in expensive high-end hardware.

Processing with MapReduce
MapReduce is the data processing engine of Hadoop. It simplifies the process of writing distributed applications. Scalable and dependable data storage solutions that guarantee fault tolerance and simple expansion are offered by Hadoop’s distributed design, as explained in Function of Big Data Advanced data analytics are made possible by Hadoop’s robust tools, which process enormous volumes of data rapidly and effectively.
The computation occurs in two phases:
This model is highly effective for large-scale data processing. For example, a retail company can use MapReduce to analyze customer purchasing patterns by scanning transaction logs and summarizing purchasing behavior. Businesses may make well-informed decisions that spur innovation and growth by utilising scalable platforms for data analytics.
Gain Your Master’s Certification in Data Science Training by Enrolling in Our Big Data Analytics Master Program Training Course Now!
Use Cases by Industry
Each of these sectors handles vast amounts of data daily, and as covered in a Data Science course, Hadoop’s distributed framework makes it manageable and actionable.
Preparing for Data Science Job? Have a Look at Our Blog on Data Science Interview Questions & Answer To Acte Your Interview!
Real-Time Analytics with Hive/Pig
While MapReduce is powerful, it is not always user-friendly for non-programmers. This led to the development of high-level tools like:
These tools allow for real-time querying and analytics on massive datasets, enabling companies to respond quickly to business changes, an essential skill in Big Data Careers highlighted.
Integration with BI Tools
Business Intelligence (BI) tools such as Tableau, QlikView, and Power BI now offer Hadoop connectors that allow direct access to Hadoop-stored data. Businesses can safely store enormous volumes of data while providing quick access for processing and analysis thanks to sophisticated data storage capabilities. This integration empowers business users to:
This bridging of big data and traditional BI opens up a world of possibilities for companies, especially when considering the differences highlighted in Hadoop vs Spark .
Cost Efficiency of Hadoop
One of the major advantages of Hadoop is its cost-effectiveness. Traditional storage systems often require expensive, proprietary hardware. A key feature of Hadoop is MapReduce processing, which divides large-scale data jobs into smaller, more manageable pieces to facilitate effective handling. Hadoop, in contrast, works efficiently on low-cost, commodity hardware. Key points include:
This makes Hadoop a viable solution for startups and large enterprises alike, especially when comparing it to databases like Cassandra vs MongoDB.
Enterprise Adoption Stories
Many global enterprises have successfully adopted Hadoop to transform their data management practices:
These success stories serve as a testament to Hadoop’s scalability, reliability, and performance, highlighting Why Scala Training is Important in this ecosystem.
Conclusion
Hadoop has emerged as a cornerstone technology for managing and analyzing big data. Businesses can execute parallel calculations across distributed systems with MapReduce processing, greatly accelerating data analysis. From retail to healthcare and beyond, organizations are leveraging Hadoop to derive insights from vast and varied data sources.Businesses in a variety of sectors depend on the Hadoop ecosystem, a key topic in any Data Science course, to turn unstructured data into insightful knowledge and promote more intelligent decision-making. MapReduce processing is perfect for industries handling complicated large data workloads because of its scalability and dependability. The Hadoop ecosystem, which includes components like HDFS, MapReduce, Hive, and Pig, helps companies handle data more effectively and economically. However, successful implementation requires careful planning, skilled personnel, and an understanding of Hadoop’s capabilities and limitations.




