
Last updated on 09th Oct 2025| 10468
- What is Apache Spark?
- Key Features and Capabilities
- Spark Architecture Overview
- RDDs and DataFrames
- Spark SQL and Streaming
- Machine Learning with Spark MLlib
- Advantages Over Hadoop MapReduce
- Spark Training and Learning Paths
- Certifications and Resources
- Real-World Use Cases
- Conclusion
What is Apache Spark?
Apache Spark is an open-source, distributed computing system designed for fast and flexible large-scale data processing. Initially developed at the University of California, Berkeley’s AMPLab in 2009 and later donated to the Apache Software Foundation, Spark is renowned for its in-memory computation capabilities, making it significantly faster than traditional disk-based processing systems like Hadoop MapReduce. Spark supports multiple programming languages such as Java, Scala, Python, and R, which broadens its accessibility to a wide range of developers and data scientists. Spark provides an interface for programming entire clusters with implicit data parallelism and fault tolerance. To master these capabilities and build scalable analytics solutions, visit Data Science Training a hands-on course that teaches cluster computing, parallel processing, and real-world data engineering techniques. It supports various high-level tools including Spark SQL for structured data processing, MLlib for machine learning, GraphX for graph processing, and Spark Streaming for real-time stream processing.
Key Features and Capabilities
Apache Spark offers a wide array of features that make it suitable for handling massive datasets and performing advanced analytics. Some of its core capabilities include in-memory computation, fault tolerance, and support for multiple languages. To explore a complementary tool designed for scripting and transforming large-scale data, navigate to What is Apache Pig a practical overview of Pig’s data flow language and its role in simplifying complex ETL tasks within the Hadoop ecosystem.
- In-Memory Computation: Unlike Hadoop MapReduce which writes intermediate results to disk, Spark retains data in memory, drastically improving performance for iterative algorithms.
- Speed: Spark can process data up to 100 times faster than Hadoop MapReduce for certain applications by leveraging its in-memory processing.
- Ease of Use: With APIs in Java, Scala, Python, and R, Spark simplifies development for various use cases, including batch processing, interactive queries, and streaming analytics.
- Advanced Analytics: Spark supports SQL queries, machine learning, graph algorithms, and stream processing within the same application.
- Fault Tolerance: Spark’s Resilient Distributed Datasets (RDDs) ensure fault tolerance by tracking data lineage.
- Lazy Evaluation: Transformations in Spark are lazy, meaning computations are only triggered when actions are invoked, leading to efficient processing.
Interested in Obtaining Your Data Science Certificate? View The Data Science Online Training Offered By ACTE Right Now!
Spark Architecture Overview
Spark follows a master-slave architecture. It consists of the following main components: the driver program, cluster manager, and worker nodes. To complement Spark’s processing power with versatile data integration tools, explore Various Talend Products and their Features a detailed breakdown of Talend’s offerings for ETL, cloud connectivity, real-time data sync, and enterprise-grade orchestration.
- Driver Program: The central coordinator that translates user code into tasks and schedules them across worker nodes.
- Cluster Manager: Allocates resources to applications. Supported managers include Standalone, YARN, Mesos, and Kubernetes.
- Executors: Distributed agents responsible for executing tasks assigned by the driver.
- Tasks: The smallest unit of work in Spark; a job is divided into tasks that run across executors.
Spark jobs are divided into stages, each consisting of a set of tasks based on transformations and actions applied to RDDs. This design allows Spark to optimize execution plans and provide faster performance.
To Explore Data Science in Depth, Check Out Our Comprehensive Data Science Online Training To Gain Insights From Our Experts!
RDDs and DataFrames
Resilient Distributed Datasets (RDDs) are the core abstraction in Spark. They represent an immutable distributed collection of objects that can be processed in parallel. RDDs can be created from Hadoop InputFormats, existing collections, or by transforming other RDDs. To extend these capabilities with enterprise-grade data integration, orchestration, and cloud connectivity, explore Various Talend Products and their Features a comprehensive overview of Talend’s modular tools for managing data pipelines across hybrid environments.
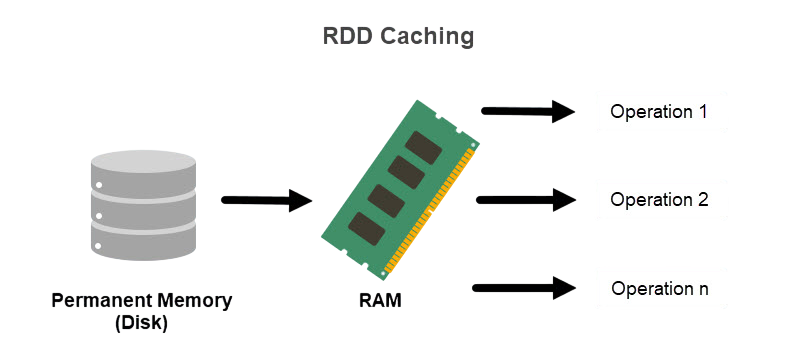
While powerful, RDDs lack optimization capabilities. To address this, DataFrames and Datasets were introduced. To understand how these abstractions improve performance and simplify data operations, visit Data Science Training a hands-on course that covers Spark fundamentals, optimization techniques, and real-world analytics workflows. DataFrames are distributed collections of data organized into named columns, similar to a table in a relational database. They benefit from Spark’s Catalyst optimizer and Tungsten execution engine, resulting in better performance. Datasets provide the benefits of both RDDs and DataFrames, offering type safety and object-oriented programming constructs along with performance optimizations.

Spark SQL and Streaming
Spark SQL enables developers to run SQL queries on structured data. It supports the Hive Query Language (HQL) and integrates with traditional BI tools via JDBC and ODBC. Spark Streaming is a component that enables scalable and fault-tolerant stream processing of live data. It divides streaming data into micro-batches and processes them using Spark’s core engine. Spark Structured Streaming extends this model by providing a more robust API with event-time processing, watermarking, and stateful operations. To handle deeply nested JSON structures often found in streaming pipelines, refer to Elasticsearch Nested Mapping a technical guide that explains how to model, query, and index hierarchical data efficiently within Elasticsearch.
Gain Your Master’s Certification in Data Science Training by Enrolling in Our Data Science Master Program Training Course Now!
Machine Learning with Spark MLlib
MLlib is Spark’s scalable machine learning library. It provides high-level APIs in Java, Scala, and Python and supports a variety of machine learning algorithms: classification, regression, clustering, and collaborative filtering. To see how these capabilities scale in a unified analytics environment, explore What is Azure Databricks a comprehensive guide to Microsoft’s cloud-based platform that seamlessly integrates Apache Spark with enterprise-grade data science, engineering, and machine learning workflows.
- Classification: Logistic Regression, SVMs
- Regression: Linear Regression, Decision Trees
- Clustering: K-means
- Collaborative Filtering: ALS (Alternating Least Squares)
- Dimensionality Reduction: PCA, SVD
MLlib also provides utilities for feature extraction, transformation, and pipeline construction, making it easy to build complete machine learning workflows.
Are You Preparing for Data Science Jobs? Check Out ACTE’s Data Science Interview Questions and Answers to Boost Your Preparation!
Advantages Over Hadoop MapReduce
Spark’s primary advantage over MapReduce lies in its speed. It performs computations in-memory, significantly reducing I/O overhead. While MapReduce is well-suited for batch processing, Spark excels in both batch and real-time scenarios. To understand how such technologies fuel organizational transformation, explore Data-Driven Culture Explained a strategic overview of how data-centric thinking empowers teams, drives innovation, and reshapes decision-making across industries.
Other advantages include:
- Unified Engine: Supports batch, interactive, streaming, and machine learning workloads.
- Ease of Development: Less boilerplate code compared to Java-based MapReduce.
- Iterative Processing: Ideal for algorithms that require multiple passes over the data.
Spark Training and Learning Paths
For professionals looking to master Apache Spark, many online learning platforms provide training options for different skill levels. Coursera has courses like “Big Data Analysis with Scala and Spark.” Udemy offers hands-on programs focused on PySpark, Spark SQL, and MLlib. Learners can also pursue professional certifications through edX, which partners with well-known institutions like Berkeley and Microsoft.
Industry leaders Cloudera and Databricks provide training and certification exams, ensuring quality educational experiences. A typical learning path covers foundational topics like Big Data and Hadoop basics, advancing through key Spark concepts, RDDs, Spark SQL, DataFrames, streaming technologies, and machine learning libraries. By combining theoretical knowledge with project-based learning, aspiring data professionals can build strong Spark skills that meet current industry needs.
Certifications and Resources
Getting certified in Apache Spark enhances credibility and job prospects. Key certifications include Databricks Certified Associate Developer, Cloudera Data Platform Certification, and Hortonworks Spark Developer. To complement these credentials with strong data pipeline and connectivity skills, explore Data Integration Guide a practical resource that outlines tools, strategies, and best practices for unifying data across platforms and formats.
- Databricks Certified Associate Developer for Apache Spark
- Cloudera Spark and Hadoop Developer Certification
Essential resources for preparation:
- Official Spark documentation
- Practice projects and Kaggle competitions
- GitHub repositories and tutorials
- Online communities like Stack Overflow and Reddit
Real-World Use Cases
Apache Spark has become a game-changing data processing tool that drives innovation in various industries with its strong performance and flexibility. In finance, Spark supports complex fraud detection, risk modeling, and real-time market analysis. Healthcare organizations use its features for predicting patient care and processing intricate genomic data. Retailers employ the platform for better customer segmentation and recommendation systems. Telecommunications companies improve network performance by analyzing detailed call data records. To ensure these data-driven strategies remain secure, compliant, and ethically sound, explore Data Governance Explained a strategic guide that outlines policies, roles, and frameworks for managing data integrity across industries. E-commerce platforms take advantage of Spark for dynamic pricing and personalized customer experiences. Industry leaders like Netflix, Uber, and Amazon run large data pipelines using this powerful technology. Importantly, Spark consistently outperforms traditional data processing systems like Hadoop MapReduce.
Conclusion
Apache Spark has revolutionized the way we process big data by providing a fast, flexible, and unified framework. Its ability to support diverse workloads from batch processing to machine learning and real-time analytics makes it a go-to solution for data engineers and scientists worldwide. To gain hands-on experience with these versatile technologies, visit Data Science Training a comprehensive program that equips learners with the skills to design, implement, and optimize data workflows across multiple domains. By understanding its architecture, components, and real-world applications, learners can leverage Spark to build scalable and efficient data pipelines. With the right training and hands-on experience, mastering Apache Spark can open the door to a range of lucrative opportunities in data engineering, analytics, and AI development.




