
Last updated on 07th Oct 2025| 10182
- Introduction: The Cost of Mistakes in Spark
- Mistake #1: Using Too Many Shuffles
- Mistake #2: Not Caching or Persisting When Needed
- Mistake #3: Poor Data Partitioning
- Mistake #4: Writing Code That Breaks Lazy Evaluation
- Mistake #5: Ignoring Resource Configuration and Tuning
- Tips for Optimal Configuration
- Conclusion
Introduction: The Cost of Mistakes in Spark
Apache Spark is celebrated for enabling developers to handle massive datasets in a distributed, fault-tolerant, and memory-efficient way. But this power comes with complexity. Unlike traditional single-node environments, Spark’s behavior depends on cluster configuration, memory management, shuffle operations, and job scheduling. As a result, Top 5 Mistakes even a simple coding misstep can lead to significant slowdowns, unexpected task failures, or resource bottlenecks. When developing Spark applications, especially at scale, understanding the Big Data Training internal execution plan, lazy transformations, and how Spark handles data across partitions is essential. While Spark abstracts away much of the complexity of distributed computing, it’s still crucial to follow best practices and avoid common anti-patterns that could result in poor performance and high infrastructure costs. Apache Spark is a powerful big data processing engine, but small mistakes in code or configuration can lead to serious consequences ranging from performance bottlenecks to system crashes Big Data Drives Small and Medium and unexpected costs. Understanding these pitfalls is essential for building efficient, reliable, and cost-effective data applications with Spark.
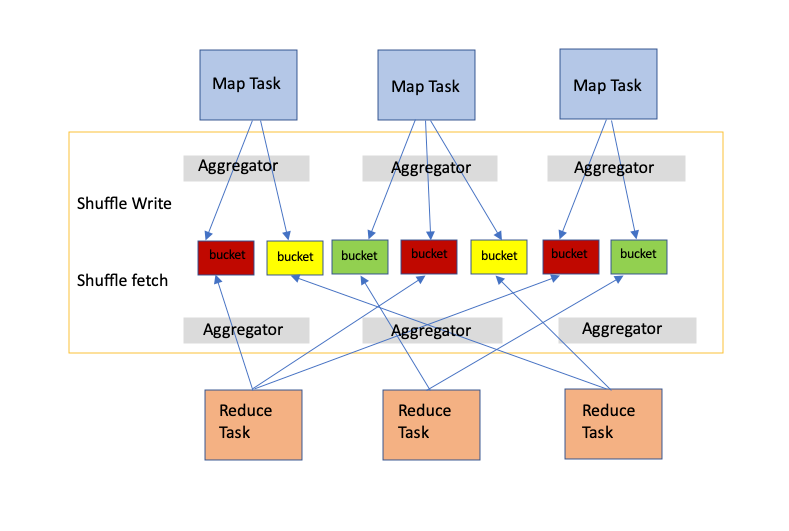
Mistake #1: Using Too Many Shuffles
- Shuffles involve data movement across the cluster, which is expensive in terms of time and resources.
- Excessive shuffles slow down performance and increase job execution time significantly.
- Often caused by operations like groupByKey, distinct, repartition, and wide joins.
- groupByKey is less efficient than alternatives like reduceByKey or aggregateByKey.
- Unnecessary repartition() calls can trigger shuffles without real benefit.
- Shuffles increase memory usage and disk I/O, Big Data Analytics leading to potential out-of-memory errors.
- Can overload the network and reduce cluster efficiency.
- To avoid this, minimize wide transformations and use narrow ones where possible.
- Use partitioning and bucketing strategies to reduce shuffle costs.
- Profile your jobs using Spark UI to identify and optimize shuffles.
Do You Want to Learn More About Big Data Analytics? Get Info From Our Big Data Course Training Today!
Mistake #2: Not Caching or Persisting When Needed
Spark’s lazy evaluation model means that transformations aren’t computed until an action is called. This can lead to the same computation being repeated multiple times if intermediate datasets aren’t cached properly. Failing to persist these intermediates can cause redundant processing, particularly in iterative algorithms or multi-stage pipelines.
Scenario in Practice:
Let’s say you’re building a machine learning pipeline where a preprocessed dataset is used for training, validation, and exploratory statistics. Without caching the preprocessed DataFrame, Data Analytics Tools for Big Data Analysis Spark will recompute the entire transformation chain for each use, wasting CPU cycles and slowing down the workflow.
When to Cache:
- When an RDD or DataFrame is reused in multiple actions or stages.
- During iterative ML algorithms (like K-Means or Gradient Boosting).
- Before expensive aggregations or complex joins.
- During development, to speed up debugging and testing.
- .cache() uses the default storage level (MEMORY_AND_DISK).
- .persist() gives you control over the storage strategy, such as keeping data in memory only, or storing it on disk if memory is insufficient.
Caching vs Persisting:
Monitor the Storage tab in Spark UI to see what’s cached and how it affects job performance.
Would You Like to Know More About Big Data? Sign Up For Our Big Data Analytics Course Training Now!
Mistake #3: Poor Data Partitioning
Efficient partitioning is crucial in Spark. Each partition is processed by one task, and poorly partitioned data leads to skewed workloads Big Data Training where some tasks take much longer to execute. This causes straggler tasks, increases job latency, and reduces the efficiency of the entire cluster.
Symptoms of Bad Partitioning:
- Some partitions have significantly more data than others.
- Out-of-memory errors on executors processing larger partitions.
- Slow task completion despite having many idle resources.
- Use .repartition(n) to increase the number of partitions before heavy transformations or wide joins.
- Use .coalesce(n) to reduce partitions when saving smaller outputs to avoid small file issues.
- Apply .partitionBy() when writing to disk formats like Parquet or ORC for improved I/O performance.
- For key-based operations, use custom partitioners to evenly distribute keys.
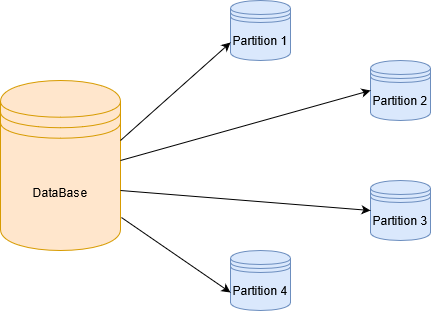
Partitioning Best Practices:
Advanced Tip:
Always evaluate Data Partitioning in combination with data skew analysis. In scenarios like joins, where one key dominates the Big Data is Transforming Retail Industry dataset (e.g., country code = ‘US’ in a global dataset), custom salting techniques or skewed join handling are needed.

Mistake #4: Writing Code That Breaks Lazy Evaluation
- Spark uses lazy evaluation, meaning transformations are not executed until an action (like count(), collect(), or save()) is called.
- Calling actions too early (e.g., collect() inside loops) triggers unnecessary computations and breaks Spark’s optimization pipeline.
- This leads to redundant job executions, increased latency, and wasted cluster resources.
- Repeated actions on the same RDD/DataFrame without Become a Big Data Analyst caching force Spark to recompute the lineage every time.
- Using collect() on large datasets can overwhelm the driver node and cause crashes.
- Breaks query optimization, especially with DataFrames and the Catalyst optimizer.
- To avoid this, minimize actions, especially in iterative code, and cache results when reused.
- Use persist() or cache() to store intermediate results for repeated access.
- Always be aware of when and how actions are triggered in your Spark application.
- Using too many executors with too few cores (leading to task scheduling overhead).
- Over-allocating memory without room for overheads (causing GC issues).
- Leaving default shuffle partitions (spark.sql.shuffle.partitions = 200) in very large or small jobs.
- Allocate Executor Memory with Buffer: Assign around 70–80% of physical memory per executor, leaving headroom for overhead and avoiding out-of-memory errors.
- Tune executor-cores: Set 3–5 cores per executor to strike a balance between parallelism and resource contention.
- Set spark.executor.instances: Configure the number of executors based on the available cluster resources Data Architect Salary and workload demands.
- Adjust spark.sql.shuffle.partitions: Optimize based on data volume and cluster size—generally 2–4× the total number of cores for balanced shuffling.
- Use Data Caching Wisely: Apply cache() or persist() only when reused multiple times to improve performance and avoid unnecessary memory usage.
- Monitor with Spark UI and Metrics Tools: Use Spark UI, Ganglia, Prometheus, or other tools to identify CPU, memory, shuffle, and I/O bottlenecks.
- Continuously Profile and Tune: Analyze job stages, tasks, and execution plans to iteratively tune Spark jobs for better performance over time.
Gain Your Master’s Certification in Big Data Analytics Training by Enrolling in Our Big Data Analytics Master Program Training Course Now!
Mistake #5: Ignoring Resource Configuration and Tuning
Spark jobs must be tuned for the available cluster resources and the specific data processing workload. A frequent mistake is running Spark jobs with default configurations, leading to memory spills, job failures, BFSI Sector Big Data Insights or sub-optimal CPU usage.
Common Misconfigurations:
Preparing for Big Data Analytics Job? Have a Look at Our Blog on Big Data Analytics Interview Questions & Answer To Ace Your Interview!
Tips for Optimal Configuration
Conclusion
Top 5 Mistakes Writing efficient and scalable Spark applications isn’t about memorizing APIs it’s about understanding Spark’s distributed nature, execution model, and system behavior. As data volumes and team sizes grow, poor code can significantly delay insights, frustrate developers, and inflate cloud bills. Avoiding common mistakes like excessive shuffles and breaking lazy evaluation is crucial for optimizing Apache Spark applications. Understanding Spark’s architecture and execution model helps developers write efficient, scalable code that maximizes performance and minimizes resource costs Big Data Training. By carefully managing data movement and leveraging lazy evaluation, teams can ensure faster processing times and more reliable big data workflows. Mastering these best practices empowers engineers to harness the full potential of Spark, delivering cost-effective and high-performing data solutions in today’s demanding analytics environments. The key to mastering Spark lies in profiling your jobs, learning from Spark UI, using data-aware transformations, and planning your cluster use smartly. Avoiding these pitfalls is the first step toward becoming a Spark performance expert and building applications that truly scale.




