
Last updated on 02nd Oct 2025| 10640
- Introduction to Spark Streaming
- Key Concepts (Batch Interval, DStreams)
- Structured Streaming Overview
- Setup and Configuration
- Ingesting Data from Sources
- Transformations and Actions
- Windowed Operations
- Fault Tolerance Mechanisms
- Conclusion
Introduction to Spark Streaming
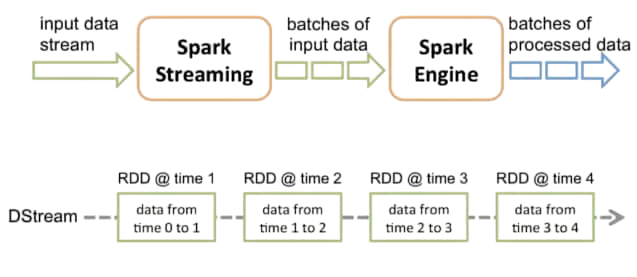
Apache Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, fault-tolerant stream processing of live data streams. Data can be ingested from many sources like Kafka, Flume, and TCP sockets, and processed using complex algorithms expressed with high-level functions like map, reduce, join, and window. Spark Streaming can process real-time data and output it to file systems, databases, and dashboards. Spark Streaming provides a simple programming model similar to batch processing in Spark Data Science Training. It divides the incoming data into micro-batches and processes them using the Spark engine. This approach combines the simplicity of Spark’s APIs with the power of real-time analytics. Apache Spark Streaming is a scalable, high-throughput, and fault-tolerant stream processing system built on top of Apache Spark. It enables real-time data processing by ingesting data from sources like Kafka, Flume, or socket connections and dividing it into small batches. These batches are then processed using Spark’s powerful core engine, allowing developers to apply complex algorithms and transformations on real-time data. Spark Streaming supports operations like map, reduce, join, and window, making it ideal for use cases such as real-time analytics Scala Certification , fraud detection, and monitoring. Its integration with the Spark ecosystem ensures easy deployment and seamless scalability.
Key Concepts (Batch Interval, DStreams)
Two fundamental concepts in Spark Streaming are:
- Discretized Streams (DStreams): DStreams are the basic abstraction in Spark Streaming. A DStream is a continuous sequence of RDDs (Resilient Distributed Datasets), which represent a stream of data divided into small batches. Each RDD in a DStream contains data from a certain interval Spark SQL .
- Batch Interval: This is the duration for which the data is grouped into an RDD. For example, if the batch interval is 2 seconds, Spark collects all data received in 2 seconds into a single RDD.
- Built on Spark SQL Engine: Uses the same APIs as batch processing, making it easy to switch between batch and streaming.
- Event-Time Processing: Supports advanced features like watermarking and windowing based on event time.
- Fault-Tolerant & Scalable: Ensures exactly-once processing semantics and handles large-scale data reliably Apache Pig.
- Continuous Streaming Model: Treats streaming data as an unbounded table, allowing SQL-like operations.
- Data Source Integration: Easily connects to sources like Kafka, File Systems, and sockets, and sinks like HDFS, Kafka, and databases.
- Unified API: Supports Python, Scala, Java, and R with a consistent API for both streaming and batch.
- Download from spark.apache.org.
- Choose a version compatible with Hadoop (if needed).
- Set environment variables like SPARK_HOME and update PATH.
- Install Java (JDK 8 or later) and Scala (if using Scala API).
- spark.sql.shuffle.partitions
- spark.streaming.backpressure.enabled
- spark.sql.streaming.checkpointLocation
- writeStream.option(“checkpointLocation”, “path/to/checkpoint”)
- Kafka: Widely used message broker for real-time data ingestion.
- Flume: Event-based log collector used in big data architectures.
- from pyspark import SparkContext
- from pyspark.streaming import StreamingContext
- sc = SparkContext(“local[2]”, “NetworkWordCount”)
- ssc = StreamingContext(sc, 1)
- lines = ssc.socketTextStream(“localhost”, 9999)
- words = lines.flatMap(lambda line: line.split(” “))
- wordCounts = words.map(lambda word: (word, 1)).reduceByKey(lambda a, b: a + b)
- wordCounts.pprint()
- ssc.start()
- ssc.awaitTermination()
- TCP Socket: For simple streaming of data from a local source.
- Files: Streaming data from a directory where new files are added.
- Custom Receivers: For integrating with other systems.
- map(): Applies a function to each element
- filter(): Filters the data
- reduceByKey(): Aggregates data
- window(): Performs operations over sliding windows Big Data Analytics
- join(): Joins two DStreams
- print(): Prints the first few elements of each RDD
- saveAsTextFiles(): Saves output to files
- foreachRDD(): Custom output logic
DStreams support various operations similar to RDDs such as map, filter, reduce, and more. You can also apply windowed computations, which allow you to perform operations over a sliding window of time.
Do You Want to Learn More About Data Science? Get Info From Our Data Science Course Training Today!
Structured Streaming Overview
Would You Like to Know More About Data Science? Sign Up For Our Data Science Course Training Now!
Setup and Configuration
Install Apache Spark
Set Up Environment
Cluster or Local Mode
Run Spark in local mode for development or connect to YARN, Data Science Training Mesos, or Kubernetes for production.
Dependencies
Add necessary libraries (e.g., Kafka connector) via Maven, SBT, or pip for PySpark: pip install pyspark
Configuration Parameters
Set parameters in spark-defaults.conf, spark-submit, or programmatically:
Checkpointing
Required for fault tolerance and stateful operations:
Logging and Monitoring: Configure log4j.properties for logging. Big Data Career Path Use Spark UI or external tools like Ganglia or Prometheus for monitoring.

Ingesting Data from Sources
Spark Streaming can receive data from various sources Cassandra Keyspace :
Example (Python – reading from socket):
Gain Your Master’s Certification in Data Science Training by Enrolling in Our Big Data Analytics Master Program Training Course Now!
Transformations and Actions
Transformations and Actions create new DStreams from existing ones:
Actions output results or trigger computation:
Transformations are lazily evaluated, just like in RDDs, and actions force the execution of the Spark job.
Preparing for Data Science Job? Have a Look at Our Blog on Data Science Interview Questions & Answer To Acte Your Interview!
Windowed Operations
Windowed operations allow computations over a period rather than a single batch interval. They are useful for scenarios such as counting events in the last 5 minutes every minute. Windowed operations in Structured Streaming allow aggregation of data over specified time windows, enabling time-based analysis of event streams. This is especially useful for use cases like monitoring trends, counting events, or detecting anomalies over time. Spark supports tumbling, sliding, and session windows, each suited for different scenarios Career in Big Data Analytics . Tumbling windows are fixed-size and non-overlapping, while sliding windows can overlap, providing finer-grained insights. Session windows group events based on periods of activity separated by inactivity. To perform windowed operations, events must include a timestamp column, and optional watermarking can be applied to handle late data. These operations make real-time, time-based analytics both powerful and flexible in Spark.
Fault Tolerance Mechanisms
Structured Streaming in Apache Spark provides robust fault tolerance to ensure data is processed reliably, even in the case of failures. The core mechanism is checkpointing, where metadata and state information are periodically saved to a reliable storage (like HDFS or S3). This allows the system to recover from failures by restarting from the last known good state. Write-ahead logs (WAL) are also used to persist input data before processing, ensuring no data loss Data Architect Salary . Spark guarantees exactly-once processing for supported sinks by replaying only unprocessed data during recovery. Additionally, watermarking helps manage late-arriving data, Fault Tolerance Mechanisms, maintaining correctness without indefinitely storing old state. These mechanisms together ensure high availability and data consistency in real-time applications. It’s important to enable checkpointing for stateful transformations and long-running applications.
Conclusion
Apache Spark Streaming bridges the gap between batch and real-time processing with its scalable and fault-tolerant architecture. By transforming incoming data into micro-batches, Spark leverages the power of the core Spark engine while offering support for complex analytics workflows. With Structured Streaming, the Spark ecosystem has evolved further to unify batch and streaming operations under a single API. Developers can now build robust real-time applications with SQL-like queries and DataFrame abstractions Data Science Training. Whether you’re analyzing financial transactions, monitoring system logs, or powering a recommendation engine, Spark Streaming offers the tools and flexibility needed to handle the ever-growing demands of real-time data analytics. With a strong understanding of its core components, configurations, and use cases, you can harness the full potential of Spark Streaming in your data engineering or data science career.




