
Last updated on 06th Oct 2025| 10333
- Introduction
- What is Apache Solr?
- History and Evolution of Apache Solr
- How Apache Solr Works
- Solr Architecture and Components
- Key Features of Apache Solr
- Solr Use Cases in the Real World
- Apache Solr vs Elasticsearch
- Conclusion
Introduction
Search has evolved from being just a web feature to becoming a core infrastructure service for digital platforms. From e-commerce product discovery and document management systems to customer support portals and content-heavy websites, search functionality ensures users can locate relevant information quickly and effectively. Building such intelligent search experiences requires strong analytical foundations, and targeted Data Science Training equips professionals to design relevance algorithms, optimize indexing strategies, and personalize results at scale. But as data grows exponentially, basic search engines fail to deliver the speed, accuracy, and scalability required. This is where enterprise-grade search platforms like Apache Solr come into play. Solr offers a highly reliable, scalable, and fault-tolerant platform that enables developers to build advanced search experiences with minimal complexity.
What is Apache Solr?
Apache Solr (pronounced “solar”) is an open-source, enterprise-class search platform built on top of the Apache Lucene library. It is designed for full-text search, faceted navigation, and real-time indexing of large volumes of data. Solr provides RESTful APIs, advanced querying capabilities, and scalability features, making it ideal for applications that need fast, efficient, and feature-rich search capabilities. To integrate such search platforms with relational databases in big data ecosystems, understanding What Is Apache Sqoop becomes essential enabling seamless data transfers between structured stores and Hadoop-based systems. Solr can handle both structured and unstructured data, offers distributed searching, and integrates easily with data sources ranging from relational databases to NoSQL systems. It powers search for many of the world’s largest websites and applications, including Netflix, DuckDuckGo, and eBay.
Interested in Obtaining Your Data Science Certificate? View The Data Science Online Training Offered By ACTE Right Now!
History and Evolution of Apache Solr
Apache Solr originated at CNET Networks in 2004 as an in-house enterprise search tool. It was open-sourced in 2006 and later joined the Apache Software Foundation. Since then, Solr has undergone numerous enhancements and became a top-level Apache project in 2007. To complement Solr’s search capabilities with real-time data ingestion and processing, Apache Spark Streaming offers a powerful solution enabling continuous analytics on live data streams and enhancing responsiveness across dynamic applications.
Over the years, Solr has evolved to support:
- Distributed search through SolrCloud
- Real-time indexing and search
- Faceted navigation and advanced filtering
- Schema-less document ingestion
- Integration with big data platforms like Hadoop
Solr’s robustness and flexibility have solidified its role as a leading search engine for enterprise applications.
To Explore Data Science in Depth, Check Out Our Comprehensive Data Science Online Training To Gain Insights From Our Experts!
How Apache Solr Works
At a high level, Solr works by ingesting data into an index, which is then used to retrieve documents efficiently based on user queries. To understand how such indexing strategies compare with structured and semi-structured data handling in Hadoop ecosystems, the Apache Hive vs HBase Guide offers valuable insights highlighting the strengths of each tool in query optimization, schema flexibility, and real-time access.
Core Workflow:
- Ingestion (Indexing): Data from various sources is parsed and stored in an inverted index structure. Fields are tokenized, analyzed, and stored in a schema-defined format.
- Querying: Users query Solr using Solr Query Language (SolrQL), a rich and expressive query format.
- Ranking & Scoring: Solr ranks documents based on relevance using TF-IDF, BM25, or custom scoring algorithms.
- Response: The matched documents are returned in JSON/XML formats with highlights, facets, and additional metadata.
Solr also supports near real-time indexing, which means newly ingested documents can be searchable within milliseconds.

Solr Architecture and Components
Solr Architecture is a complex search platform that is designed on a modular architectural framework which makes the flexible and powerful full-text search capabilities possible. The multiple interconnected components that Solr uses at its core are the main reason for the high indexing and querying performance that can be observed in distributed environments. To architect and optimize such systems, professionals rely on advanced Data Science Training gaining the skills to fine-tune search infrastructure, manage distributed queries, and deliver scalable performance across large datasets.
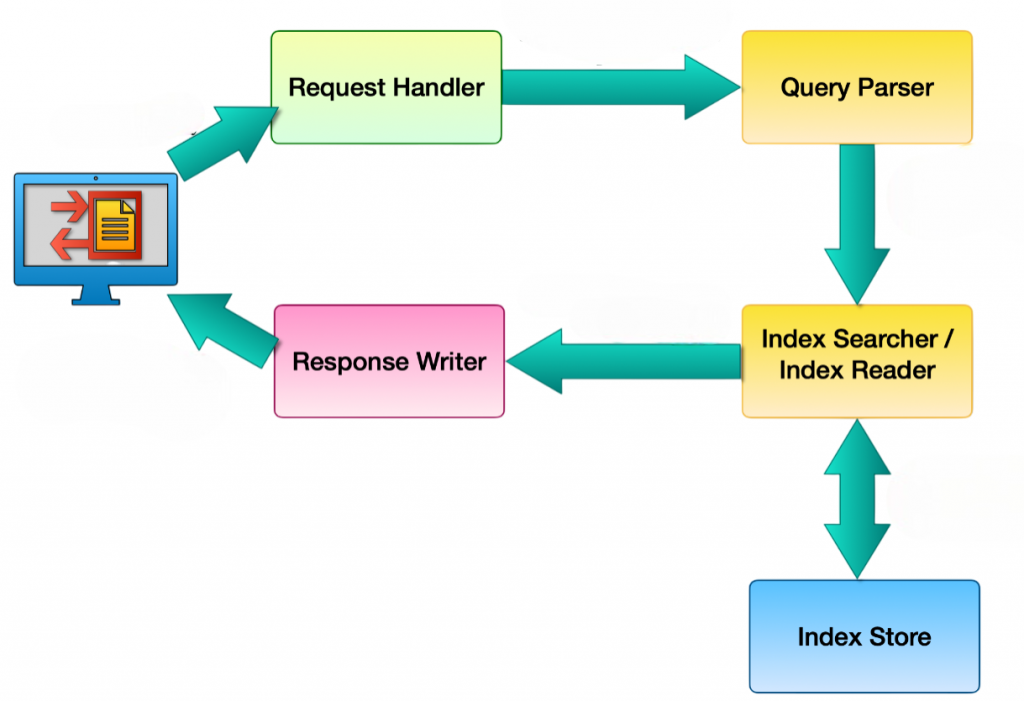
The system architecture is centered on a core index that can have more than one instance in a single server and is defined by an extensive schema that lays down data structures, field types, and properties. Query processing is conducted by request handlers, while analyzers and tokenizers are involved in breaking the text into tokens that can be searched. Besides this, they also apply advanced filters like stemming and case normalization. The groundbreaking inverted index of the platform is the main data structure that links terms to documents, thereby providing ultra-fast search operations.
Gain Your Master’s Certification in Data Science Training by Enrolling in Our Data Science Master Program Training Course Now!
Key Features of Apache Solr
Apache Solr is one of those search platforms that stands out with a) its wide range of features that entice the users and change the information retrieval process and user experience b) its phenomenal search results. The platform through its extensive tokenization, stemming, and synonym support allows users to get more precise and nuanced search results by implementing full-text search with the help of sophisticated text. Developers can take advantage of the modular design that is equipped with functionalities namely real-time indexing, distributed search capabilities via SolrCloud, and custom ranking algorithms which are adjustable to specific domain requirements. To extend these capabilities into streaming analytics and intelligent data pipelines, Apache Spark with These Real-World Projects provides hands-on experience empowering developers to build scalable, domain-specific solutions that integrate search, processing, and decision-making in real time. The platform’s extensive practical applications in geographical searches, multilinguistic support, and comfortable document decoding through the use of Apache Tika which facilitates the extraction of content irrespective of the file format are just a few examples of Solr.
Are You Preparing for Data Science Jobs? Check Out ACTE’s Data Science Interview Questions and Answers to Boost Your Preparation!
Solr Use Cases in the Real World
Apache Solr is used by organizations of all sizes and across industries due to its powerful capabilities and open-source flexibility. When integrating Solr into large-scale data ecosystems, understanding Spark vs MapReduce becomes critical highlighting the differences in processing models, execution speed, and scalability that directly impact how search platforms interact with distributed data pipelines.
Real-World Applications:
- E-Commerce: Enables lightning-fast product search, filter-by-attribute, and personalized ranking.
- Media and Publishing: Powers content discovery, article indexing, and faceted navigation for large archives.
- Healthcare: Helps in searching through patient records, clinical notes, and research literature.
- Government Portals: Makes public data searchable and accessible.
- Enterprise Portals: Indexes documents, emails, and knowledge bases for internal search engines.
- Customer Support: Enhances chatbot and helpdesk responses with real-time search from knowledge bases.
From indexing millions of web pages to enabling real-time log search, Solr provides the backbone of search-centric systems.
Apache Solr vs Elasticsearch
Apache Solr and Elasticsearch are the two leading open-source search engines, both based on Lucene. Choosing between them often depends on project goals, team expertise, and ecosystem preference. For managing distributed coordination across such search platforms, understanding What is Apache Zookeeper is essential it provides the backbone for maintaining configuration consistency, leader election, and fault tolerance in clustered environments.
Solr Strengths:
- Mature Feature Set: More configurable and customizable in many scenarios.
- Advanced Search Features: Stronger support for complex queries, faceting, and relevancy tuning.
- Better in Controlled Environments: Ideal for enterprises with specific architecture control and tuning needs.
- Stable Governance: Managed by the Apache Software Foundation.
Elasticsearch Strengths:
APIs that are developer-friendly and have JSON-native and RESTful architectures which guarantee a simpler onboarding and a smooth integration. We offer end-to-end log analytics use cases by harnessing ELK Stack functionalities, such as Kibana’s dynamic visualization tools and Logstash’s heavy-duty ingestion. Our solution, built with a cloud-native mindset, is fully geared for SaaS and DevOps workflows, facilitating teams to proficiently orchestrate and compute the data landscape. Though Solr and Elasticsearch both offer attractive features, our method emphasizes the adaptability, enabling the organizations to choose the most suitable solution for their particular requirements in search customization and operations.
Conclusion
Apache Solr continues to be a leading solution in enterprise search, offering the reliability, scalability, and feature depth that modern applications demand. Its open-source flexibility, strong community support, and rich set of features make it a competitive alternative to proprietary search engines and commercial SaaS options. To leverage such platforms effectively, professionals benefit from comprehensive Data Science Training building the analytical depth and technical fluency needed to deploy, customize, and scale open-source solutions in real-world environments. Whether you’re building an internal knowledge portal, a consumer-facing e-commerce platform, or a machine-learning-powered search tool, Solr provides the building blocks for creating a fast, intuitive, and scalable search experience. As the search landscape evolves with AI, machine learning, and natural language processing, Solr remains an active, growing platform constantly adapting and ready to meet the next generation of search challenges.




