
Last updated on 08th Oct 2025| 10238
- Introduction: The Role of IBM in the Big Data Ecosystem
- What is IBM InfoSphere?
- Core Components of InfoSphere
- InfoSphere Information Server: The Heart of Data Integration
- InfoSphere BigInsights: Hadoop, the IBM Way
- Governance and Quality in InfoSphere
- Real-Time Processing with InfoSphere Streams
- Security and Compliance Features
- Conclusion
Introduction: The Role of IBM in the Big Data Ecosystem
In the rapidly evolving world of Big Data, few enterprise names carry the weight and legacy of IBM. While open-source platforms like Hadoop and Spark dominate the discussion around scalable data processing, IBM has carved out a space for itself by integrating these technologies into comprehensive, enterprise-grade solutions. Central to this strategy is IBM InfoSphere, a robust data integration and management suite designed to empower organizations with the tools they need to govern, Data Science Training, cleanse, transform, and analyze massive volumes of structured and unstructured data. IBM’s InfoSphere is not just a product, it is a platform that supports the full lifecycle of enterprise data management, helping businesses turn raw data into trusted information for decision-making and innovation. IBM plays a pivotal role in the big data ecosystem by providing advanced tools and platforms that enable organizations to manage, analyze, and secure massive data volumes. Through solutions like InfoSphere, IBM integrates data processing, Hadoop analytics, real-time streaming, and governance, helping businesses unlock actionable insights and maintain compliance in an increasingly data-driven world.
What is IBM InfoSphere?
IBM InfoSphere is a comprehensive suite of data integration, governance, and management tools designed to help organizations harness the power of big data. It enables seamless collection, cleansing, transformation, and delivery of data across complex environments.
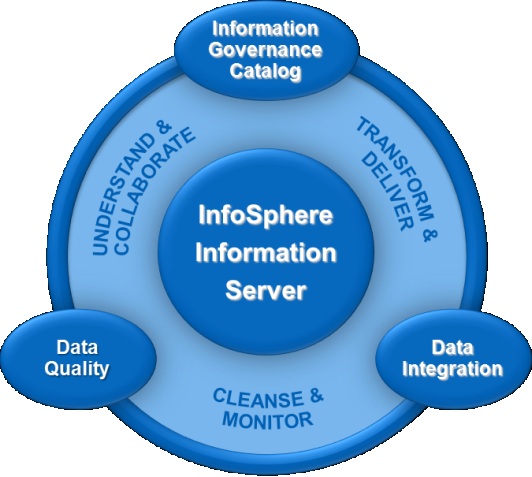
Core components include InfoSphere Information Server for data integration, InfoSphere BigInsights for Hadoop-based analytics, and InfoSphere Streams for real-time data processing Apache Hive vs HBase Guide . InfoSphere supports data quality, metadata management, and security, ensuring trusted and compliant data use. By providing scalable and flexible solutions, IBM InfoSphere helps businesses turn raw data into valuable insights, driving smarter decision-making in today’s data-driven landscape
Interested in Obtaining Your Data Science Certificate? View The Data Science Online Training Offered By ACTE Right Now!
Core Components of InfoSphere
IBM InfoSphere consists of several key components, each addressing different stages of the data lifecycle:
- InfoSphere Information Server: For data integration and ETL.
- InfoSphere BigInsights: IBM’s Hadoop-based analytics platform.
- InfoSphere Streams: For real-time, continuous data processing.
- InfoSphere Optim: For data archiving and lifecycle management Elasticsearch Nested Mapping .
- InfoSphere Master Data Management (MDM): For creating a single view of enterprise data.
- InfoSphere Governance Catalog: For metadata management and data governance.
These modules are built to work seamlessly with each other and with other IBM solutions such as Db2, Cognos, and Watson, creating an end-to-end data ecosystem.
To Explore Data Science in Depth, Check Out Our Comprehensive Data Science Online Training To Gain Insights From Our Experts!
The Role of Parallel Processing in Hadoop
- Enables scalability: Parallel processing allows Hadoop to split large datasets into smaller chunks processed simultaneously across multiple nodes.
- Improves speed: By processing data in parallel, Hadoop significantly reduces the time required for big data computations Data Science Training.
- MapReduce framework: Uses parallel execution of map and reduce tasks to handle distributed data efficiently.
- Fault tolerance: Parallel tasks run independently, so failures can be isolated and retried without affecting the entire job.
- Resource utilization: Maximizes cluster resource usage by distributing workload evenly across nodes.
- Supports large-scale analytics: Essential for handling massive datasets in industries like finance, healthcare, and social media.

InfoSphere BigInsights: Hadoop, the IBM Way
InfoSphere BigInsights is IBM’s answer to scalable, distributed data processing using Apache Hadoop. What makes BigInsights different is its enterprise-friendly enhancements: Integration with traditional IBM systems (like DB2)
- Built-in support for text analytics, machine learning, and SQL on Hadoop
- Graphical interfaces and developer-friendly tools
- Enterprise-grade security and workload management
BigInsights allows businesses to leverage open-source Hadoop while benefiting from the support, governance, and performance BFSI Sector Big Data Insights improvements IBM offers. It bridges the gap between innovation and reliability, Core Components of InfoSphere making Hadoop more accessible to enterprise users.
Gain Your Master’s Certification in Data Science Training by Enrolling in Our Data Science Master Program Training Course Now!
Governance and Quality in InfoSphere
As data becomes central to strategic decision-making, data governance is no Governance and data quality are core pillars of IBM InfoSphere, ensuring that organizations can trust and effectively manage their data. InfoSphere provides robust data governance capabilities through tools like the InfoSphere Information Governance Catalog, which helps users discover, classify, and manage metadata across the enterprise An ETL Audit Process . This promotes transparency, compliance, and accountability in data usage. For data quality, InfoSphere includes features that profile, cleanse, match, and monitor data, enabling organizations to identify and correct inconsistencies or errors.
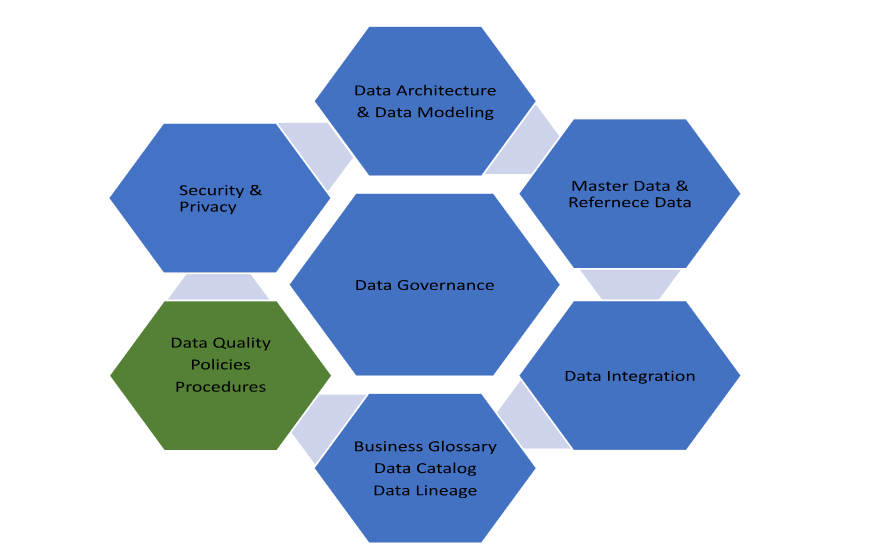
These functions help maintain accurate, consistent, and complete datasets across systems. By integrating governance and quality into its data pipeline, InfoSphere not only ensures regulatory compliance but also enhances the reliability of analytics and business decisions. The platform supports collaboration between business and IT teams, establishing clear data ownership and stewardship. Overall, InfoSphere empowers organizations to transform raw, untrusted data into a reliable asset that drives operational efficiency and strategic growth.
Are You Preparing for Data Science Jobs? Check Out ACTE’s Data Science Interview Questions and Answers to Boost Your Preparation!
Real-Time Processing with InfoSphere Streams
While Hadoop and BigInsights focus on batch processing, InfoSphere Streams is designed for real-time analytics. It enables:
- Continuous ingestion and processing of data from sensors, logs, and social media
- Low-latency processing for applications like fraud detection, Apache Spark Certification network monitoring, or IoT
- Integration with Spark and Hadoop for hybrid workloads
Streams brings the velocity dimension of Big Data into sharp focus, making InfoSphere suitable for use cases where time-sensitive decisions are essential.
Security and Compliance Features
IBM takes a comprehensive approach to data security, embedding features throughout the InfoSphere platform:
- Role-based access control (RBAC) across all modules
- Data masking and encryption for sensitive information Data Analytics Tools for Big Data Analysis
- Audit trails and activity monitoring
- Integration with IBM Guardium for advanced data security and compliance auditing
These features make InfoSphere well-suited for industries such as banking, insurance, and healthcare, where data privacy and regulatory compliance are mission-critical.
Conclusion
IBM InfoSphere stands out as a comprehensive, enterprise grade Big Data platform that supports every phase of data management from integration and governance to analytics and compliance. While it may require significant investment and expertise to implement, its scalability, reliability,Big Data Ecosystem and broad toolset make it ideal for large organizations with complex data environments. If your business values trusted, highquality data and operates under strict regulatory frameworks, IBM InfoSphere is more than a tool it’s a strategic data foundation.Data Science Training To sum up, IBM InfoSphere is a strong and all inclusive platform for handling the challenges of big data. InfoSphere enables businesses to transform massive volumes of unprocessed data into reliable, useful insights with its integrated solutions for data integration, governance, quality, real time processing, and Hadoop based analytics. Platforms like InfoSphere are crucial for guaranteeing that data is not only available but also accurate, safe, and well-governed, as organizations depend more and more on it to inform their decisions. Organizations may maintain their competitiveness, compliance, and innovation in the modern world by implementing InfoSphere.




