
Last updated on 07th Oct 2025| 9995
- Introduction: Why Hadoop Skills Matter in Today’s Data World
- Core Understanding of Big Data Fundamentals
- Proficiency in Hadoop Architecture and Components
- HDFS Expertise: The Storage Backbone
- Mastery of MapReduce Programming
- Knowledge of Hadoop Ecosystem Tools
- Programming Languages for Hadoop Professionals
- Data Ingestion and Workflow Orchestration
- Soft Skills for Success in Hadoop Careers
- Conclusion
Introduction: Why Hadoop Skills Matter in Today’s Data World
In today’s data-driven world, organizations generate and consume massive volumes of information every second. Traditional data processing tools can no longer handle the scale, speed, or complexity of this data. That’s where Hadoop comes in. Apache Hadoop is an open-source framework that enables distributed storage and processing of big data across clusters of computers. Its ability to manage structured, semi-structured, Big Data Training and unstructured data makes it a vital tool in modern data architecture. Hadoop skills are increasingly in demand as businesses across industries finance, healthcare, e-commerce, and more leverage big data to gain insights, drive innovation, and improve efficiency. Professionals who understand Hadoop’s core components HDFS, MapReduce, YARN, and tools like Hive and Spark are well-positioned for high-impact roles in tech and analytics. As big data continues to grow, mastering Hadoop is not just an asset it’s a necessity for anyone looking to thrive in the evolving data landscape.
Core Understanding of Big Data Fundamentals
Before diving into Hadoop-specific tools,Data Architect Salary in India a professional must grasp the foundational concepts of Big Data. This includes understanding the 4 Vs:
- Volume – The scale of data being handled
- Velocity – The speed at which data is generated and processed
- Variety – The different formats (structured, semi-structured, unstructured)
- Veracity – The trustworthiness and quality of data
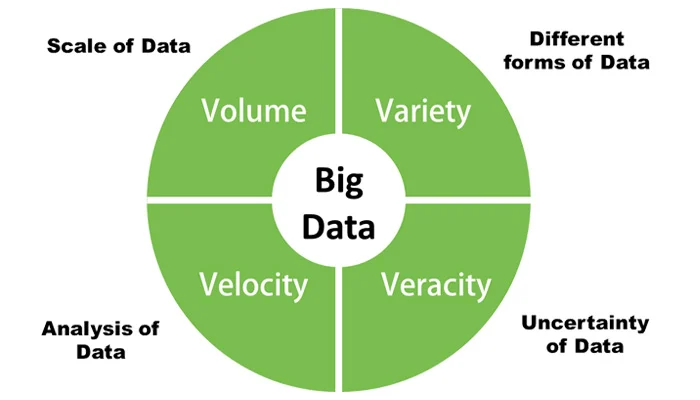
This conceptual base allows Hadoop professionals to identify use cases where Hadoop is the right fit and make design decisions accordingly. Whether it’s choosing batch over real-time processing or opting for columnar storage formats, Big Data Career Path understanding Big Data helps steer architectural clarity.
Do You Want to Learn More About Big Data Analytics? Get Info From Our Big Data Course Training Today!
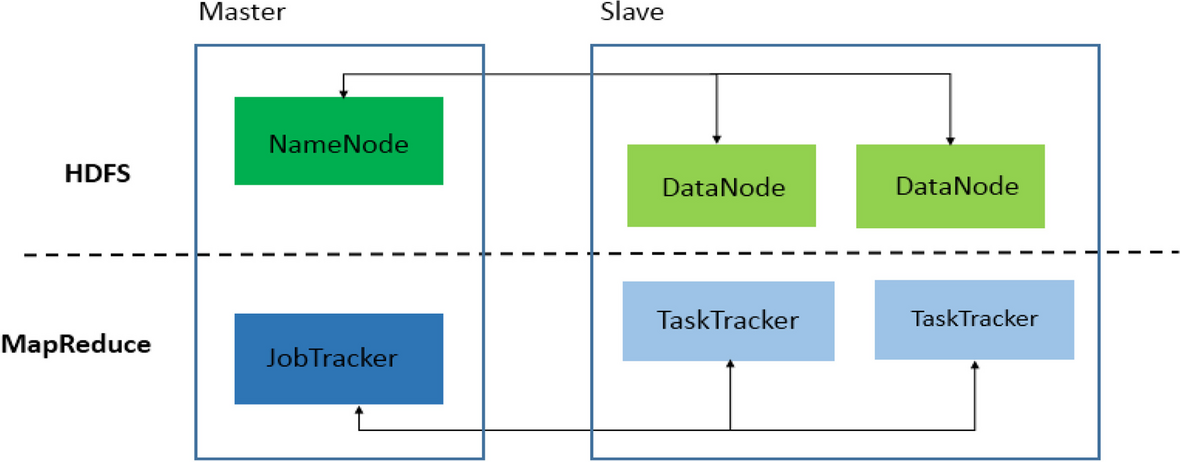
Proficiency in Hadoop Architecture and Components
A Hadoop professional must have a strong grasp of the Hadoop ecosystem’s architecture. This includes understanding how different components interact and how data flows through them Cassandra Keyspace.
Key Concepts to Master:
- HDFS (Hadoop Distributed File System) – For storing large datasets across clusters
- MapReduce – For processing data in a distributed, fault-tolerant manner
- YARN (Yet Another Resource Negotiator) – For resource allocation and job scheduling
- Zookeeper – For coordination and maintaining configuration across distributed nodes
Understanding these internals helps professionals optimize resource usage, improve system stability, and design more efficient workflows.
Would You Like to Know More About Big Data? Sign Up For Our Big Data Analytics Course Training Now!
HDFS Expertise: The Storage Backbone
The Hadoop Distributed File System (HDFS) is the foundational storage layer of the Hadoop ecosystem, designed to store and manage massive volumes of data across distributed clusters. Its architecture allows data to be split into large blocks and stored redundantly across multiple nodes, ensuring both scalability and fault tolerance. Mastery of HDFS is essential for big data professionals, as it underpins the performance, reliability, Data Governance and efficiency of the entire data pipeline. HDFS experts understand how to configure storage parameters, manage replication factors, monitor file system health, and optimize data placement for performance. They ensure seamless integration with other Hadoop components like MapReduce, Hive, and Spark, enabling efficient data processing and analysis. In a world where data grows exponentially, HDFS provides the robust storage infrastructure needed to support high-throughput, data-intensive applications. Professionals with deep HDFS knowledge play a critical role in building resilient big data platforms that power real-time decision-making and analytics.

Mastery of MapReduce Programming
MapReduce is the core programming model for processing large-scale data within the Hadoop ecosystem. It enables distributed, parallel processing by breaking tasks into two main phases: Map, which filters and sorts data, and Reduce, which aggregates results. Mastering MapReduce is essential for big data engineers and developers, as it forms the backbone of many large-scale data processing workflows. With strong MapReduce skills, professionals can write efficient, Big Data Training fault-tolerant code capable of handling terabytes or even petabytes of data. They learn to optimize job execution, manage resource allocation, and reduce data shuffling to enhance performance.
Understanding how to chain multiple MapReduce jobs and integrate them with HDFS and other Hadoop tools is also crucial. While newer tools like Apache Spark have gained popularity, MapReduce remains fundamental in many enterprise systems Big Data Can Help You Do Wonders. Those who master it gain deep insights into distributed computing, enabling them to build scalable solutions for data transformation, analysis, and reporting.
Gain Your Master’s Certification in Big Data Analytics Training by Enrolling in Our Big Data Analytics Master Program Training Course Now!
Knowledge of Hadoop Ecosystem Tools
The Hadoop ecosystem has grown far beyond just HDFS and MapReduce. A Hadoop professional is expected to be familiar with multiple tools that expand functionality Data Integration . Essential Tools to Know:
- Apache Hive – SQL-like querying for large datasets
- Apache Pig – Data transformation using Pig Latin
- Apache HBase – NoSQL database built on HDFS for real-time access
- Apache Sqoop – Data transfer between Hadoop and RDBMS
- Apache Flume – Ingesting event logs into HDFS
- Apache Oozie – Scheduling and managing Hadoop jobs
- Apache Zookeeper – Distributed coordination and configuration
- Apache Ambari – Cluster provisioning and monitoring
Understanding when and how to use these tools gives professionals an edge when designing end-to-end data pipelines and building scalable data platforms.
Preparing for Big Data Analytics Job? Have a Look at Our Blog on Big Data Analytics Interview Questions & Answer To Ace Your Interview!
Programming Languages for Hadoop Professionals
Programming is at the core of all Hadoop development and data engineering activities. Therefore, proficiency in relevant languages is crucial.
Must-Know Languages:
- Java – Primary language for writing MapReduce programs and interacting with Hadoop APIs
- Python – Widely used for scripting and data manipulation; works well with PySpark
- SQL – Data-Driven Culture Essential for querying data via Hive and integrating with BI tools
- Shell scripting – For automating workflows, managing files, and executing batch jobs
Knowing these languages allows professionals to work flexibly across Hadoop tools and handle both scripting and development tasks.
Data Ingestion and Workflow Orchestration
Data ingestion and workflow orchestration are critical components of any big data architecture. Data ingestion refers to the process of collecting and importing data from various sources such as databases, APIs, sensors, or logs into a centralized system like Hadoop for storage and analysis. Efficient ingestion ensures that data is available in real-time or batch mode, depending on business needs. Tools like Apache Flume, Sqoop, and Kafka are commonly used for this purpose. Workflow orchestration, on the other hand, involves automating and managing the sequence of data processing tasks. It ensures that data pipelines run reliably Big Data Analysis , dependencies are handled, and jobs are monitored for success or failure. Tools like Apache Oozie, Airflow, and NiFi help coordinate complex workflows across the big data ecosystem. Mastering both data ingestion and orchestration allows engineers to build robust, scalable pipelines that ensure data flows smoothly from source to insight supporting real-time analytics and informed decision-making.
Conclusion
The Hadoop ecosystem may have changed since its early days, but it still forms the foundation of many large-scale data processing platforms in both legacy and modern environments. Organizations continue to rely on Hadoop-based solutions to process massive data volumes efficiently, and they require professionals with a well-rounded, evolving skill set. Whether you aim to become a Hadoop Developer, Data Engineer, or Big Data Architect, mastering the skills outlined above will help you thrive in high-demand, high-paying roles Big Data Training. By focusing on both core technologies and the extended ecosystem and balancing that with strong communication and problem-solving abilities you position yourself at the forefront of the Big Data revolution. In today’s data-centric world, mastering Hadoop and its ecosystem is essential for professionals aiming to thrive in big data roles. From understanding HDFS and MapReduce to managing data ingestion and orchestrating complex workflows, each skill contributes to building scalable, reliable data solutions. As organizations increasingly rely on data to drive innovation and efficiency, the demand for Hadoop expertise continues to grow across industries.




