
Last updated on 03rd Oct 2025| 9932
- Career in Software Testing
- Need for Upskilling
- Why Hadoop Testing?
- Course Outline and Labs
- Gaining Hands-On Exposure
- Understanding Hadoop Ecosystem
- Preparing for Job Interviews
- Getting Certified
- Conclusion
Career in Software Testing
Somashekhar Hatti began his career in software testing over a decade ago, working with conventional automation and manual testing tools in enterprise IT projects. With a solid background in quality assurance, he was responsible for ensuring the functionality and stability of applications before deployment. For years, he contributed significantly to product reliability in sectors such as retail, banking, and insurance. However, with the rapid growth of data across industries and the increasing reliance on data-driven systems, Somashekhar started noticing a shift in industry expectations. Traditional testing skills, though still essential Data Analytics Training, were no longer sufficient to meet the growing demand in the digital era. Big Data, Hadoop ecosystems, and data-centric applications were entering mainstream projects and that meant testing also needed to evolve. Somashekhar Hatti’s success story showcases how Hadoop Testing training can open new career paths in software testing. With a background in traditional software testing, Somashekhar embraced Hadoop Testing to specialize in big data environments. The training equipped him with skills to test Hadoop ecosystems, including data validation, performance testing, and automation. Hands-on projects and real-world scenarios boosted his confidence and practical knowledge. After completing the course, Somashekhar successfully secured a role as a Big Data Tester Elasticsearch Nested Mapping , blending his software testing expertise with new Hadoop skills. His journey highlights the growing demand for specialized testing professionals in the big data field.
Need for Upskilling
- Technology Evolution: Rapid advancements in technology require continuous learning to stay relevant.
- Competitive Job Market: Upskilling increases employability and helps professionals stand out.
- Industry Demand: Emerging fields like Big Data, AI, and cloud computing need updated skills.
- Career Growth: New skills open doors to higher roles, Cassandra Keyspace better pay, and diverse opportunities.
- Adaptability: Upskilling helps professionals adapt to changing job roles and business needs.
- Improved Productivity: Learning new tools and techniques enhances efficiency and problem-solving.
- Future-Proofing: Staying current reduces the risk of job obsolescence due to automation or shifts in demand.
- Introduction to Big Data and Hadoop Ecosystem
- Hadoop Architecture and Components (HDFS, MapReduce, YARN)
- Hadoop Installation and Configuration
- Data Ingestion using Flume and Sqoop
- Introduction to Hive and Pig for Data Querying
- Working with HBase (NoSQL Database)
- Big Data Analysis Introduction to Apache Spark and its Integration with Hadoop
- Setting up a Single Node and Multi-Node Hadoop Cluster
- Writing and Executing MapReduce Programs
- Data Import using Sqoop from Relational Database.
- Data Collection using Flume from Streaming Sources
- Querying Data with Hive and Pig Scripts
- Implementing Real-Time Data Storage with HBase
- Running Spark Jobs for Fast Data Processing
- HDFS (Hadoop Distributed File System): Stores large data sets across multiple machines with fault tolerance.
- MapReduce: A programming model for processing large data sets in parallel across a cluster.
- YARN (Yet Another Resource Negotiator): Manages and schedules resources for various applications in the cluster.
- Hive: Data warehouse infrastructure for querying and managing large datasets using SQL-like language.
- Pig: Various Talend Products and their Features A scripting platform for analyzing large data sets with a simple scripting language (Pig Latin).
- HBase: A NoSQL database for real-time read/write access to large datasets.
- Sqoop: Tool for transferring data between Hadoop and relational databases.
- Flume: Service for collecting, aggregating, and moving large amounts of streaming data into Hadoop.
- Spark: Fast, in-memory data processing engine compatible with Hadoop data.
- Oozie: Workflow scheduler system to manage Hadoop jobs.
- “How do you validate data transformation logic in a Hive query?”
- “What are the key steps in testing a Hadoop ETL pipeline?”
- “How would you automate a test scenario in Hadoop?”
Interested in Obtaining Your Data Analyst Certificate? View The Data Analytics Online Training Offered By ACTE Right Now!
Why Hadoop Testing?
Hadoop Testing has become increasingly important as organizations rely more heavily on big data platforms to manage and analyze vast amounts of information. Hadoop ecosystems are complex, comprising multiple components like HDFS (Hadoop Distributed File System), MapReduce, YARN, Hive, and others. Each plays a critical role in storing, processing, and managing data, making it essential to test these components thoroughly to ensure seamless operation. One key reason for Hadoop Testing is to maintain data accuracy and integrity. Since businesses make decisions based on this data Apache Hive vs HBase, any errors or inconsistencies can lead to significant losses. Testing validates that data is correctly ingested, transformed, and stored without corruption or loss. Performance testing is also vital. Hadoop clusters must efficiently handle increasing volumes of data while maintaining quick processing speeds. Testing identifies bottlenecks and helps optimize resource allocation, ensuring scalability as data grows. Another important aspect is fault tolerance. Hadoop is designed to handle node failures without affecting overall performance. Testing verifies that the system recovers smoothly from such failures, maintaining reliability.
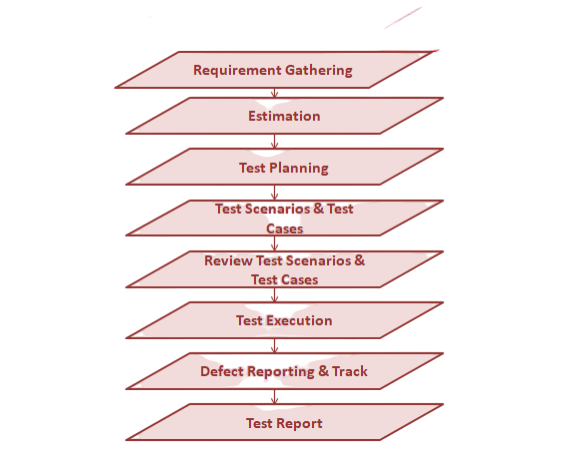
Given the large data volumes and complex workflows, automation in Hadoop Testing is crucial. Automated tests speed up validation and reduce manual errors, allowing for continuous integration and delivery. Overall, Hadoop Testing ensures the platform operates reliably, delivering trustworthy insights critical for business success.
To Explore Data Analyst in Depth, Check Out Our Comprehensive Data Analytics Online Training To Gain Insights From Our Experts!
Course Outline and Labs
Somashekhar enrolled in a reputed online Hadoop Testing Training program, designed specifically for QA professionals like him. The course began with the basics of Big Data and the Hadoop ecosystem and gradually moved toward practical Hadoop testing techniques.
Course Outline
Labs
Each module included hands-on labs, assignments, and use cases. The program provided a virtual lab environment with pre-configured Hadoop clusters so that learners could practice in a real-world setup Data Architect Salary in India .

Gaining Hands-On Exposure
One of the defining aspects of the training was the emphasis on hands-on experience. Somashekhar worked on simulated real-world projects, including a telecom company’s customer churn analysis and a banking sector fraud detection pipeline. These projects helped him understand how to approach big data testing from a practical perspective. He learned how to write Hive queries to validate data transformations, Data Analytics Training how to use Shell scripts to simulate data ingestion, and how to monitor Hadoop jobs for failures. He even developed test scripts to validate that the output of MapReduce jobs matched the expected results. By practicing in this hands-on manner, Somashekhar gained the confidence to handle real-time scenarios in production-like environments. Gaining practical experience is essential to becoming proficient with Hadoop and Big Data technologies. Students’ comprehension is strengthened when they apply academic ideas to real-world situations through practical experience.
People gain tool proficiency and problem-solving abilities by working on real-world projects, configuring Hadoop clusters, and processing data. Gaining practical experience with programs like MapReduce, Hive, and Spark boosts one’s confidence while tackling big data problems. By mimicking real-time procedures and data environments, it also gets students ready for industrial expectations Azure Databricks. In the end, practical experience closes the knowledge gap and increases a candidate’s appeal to employers.
Gain Your Master’s Certification in Data Analyst Training by Enrolling in Our Data Analyst Master Program Training Course Now!
Understanding Hadoop Ecosystem
Are You Preparing for Data Analyst Jobs? Check Out ACTE’s Data Analyst Interview Questions and Answers to Boost Your Preparation!
Preparing for Job Interviews
With technical knowledge in place, Somashekhar began preparing for job interviews in Big Data QA roles. The training program provided mock interviews Data Governance , resume reviews, and case-based discussions. He was trained on how to answer questions like:
Through multiple rounds of feedback and practice, he refined his articulation, structured his answers better, and improved his confidence.
Conclusion
Somashekhar’s success story is an inspiration to other QA professionals considering a move into Big Data. His journey highlights how proactive learning, hands-on practice, and structured guidance can lead to meaningful career advancement. Today, he continues to grow in his role, learning tools like Apache Spark,Data Analytics Training Airflow, and Kafka for advanced data testing scenarios. He actively mentors juniors and contributes to online QA communities. His advice to beginners: “Don’t be afraid of the word ‘Big’ in Big Data. Start small, stay consistent, and focus on understanding the ‘why’ behind each tool and process. The opportunities are endless if you commit to learning.”




