
Last updated on 02nd Oct 2025| 9966
- Importance of Real-Time Analytics
- Spark’s Key Strengths
- Speed and Fault Tolerance
- Scalability and Resource Management
- Integration with Streaming Sources
- Use Cases Across Industries
- Cost and Performance Balance
- Comparisons with Other Tools
- Conclusion
Importance of Real-Time Analytics
Real-time analytics is the process of analyzing data as it is created or ingested into a system. This capability is crucial for a wide variety of industries. For instance, e-commerce platforms need to analyze customer interactions immediately to recommend products. Financial institutions need real-time fraud detection systems. Logistics companies rely on up-to-the-second tracking data to manage supply chains. Apache Spark has become a pivotal technology in the domain of big data and real-time analytics Data Science Training . Built for speed, ease of use, and sophisticated analytics, Spark has established itself as a dominant force in processing large-scale data, particularly for real-time use cases. In today’s fast-paced digital ecosystem, businesses rely on up-to-the-second insights, and Spark’s robust infrastructure makes it the go-to platform for real-time data processing. This article delves into the various reasons why Spark will continue to dominate real-time analytics. Given the need for immediacy and accuracy, real-time analytics has moved from being a luxury to a necessity, and Spark fulfills this requirement with its rich ecosystem and architecture.
Spark’s Key Strengths
Apache Spark is designed to be fast and general-purpose. Unlike traditional MapReduce frameworks, Spark keeps intermediate data in memory, making it significantly faster for iterative algorithms and streaming workloads. Here are some of the key strengths of Spark:
- In-Memory Processing: Keeps data in memory for faster processing compared to disk-based systems like Hadoop MapReduce.
- Ease of Use: Offers APIs in Python, Java, Scala, and R, and includes high-level libraries like Spark SQL, MLlib, GraphX, and Spark Streaming Data Architect Salary .
- Unified Engine: Processes batch, streaming, and interactive queries in one engine.
- Scalability: Easily scales from a single server to thousands of nodes.
- Integration: Works seamlessly with Hadoop, Kafka, Flume, and many other tools.
These features make Spark ideal for companies that need real-time insights without building multiple parallel systems for batch and stream processing.
Do You Want to Learn More About Data Science? Get Info From Our Data Science Course Training Today!
Speed and Fault Tolerance
Spark’s speed advantage is primarily due to its in-memory computation. When running iterative algorithms or data pipelines, Spark performs up to 100x faster than Hadoop MapReduce. Its Directed Acyclic Graph (DAG) execution engine optimizes task scheduling, resource allocation, and fault recovery. Fault tolerance in Spark is handled using lineage information. If a node fails, Spark can recompute lost data using lineage information rather than relying on disk replication. This recovery method makes it both efficient and reliable, key attributes for real-time systems. Apache Spark Streaming is designed to deliver both high-speed data processing Data Science Training and robust fault tolerance, making it ideal for real-time applications. Its micro-batch architecture enables rapid processing of data streams in near real-time, ensuring low latency while maintaining high throughput. At the same time, Spark ensures fault tolerance through features like checkpointing, write-ahead logs (WAL), and replayable data sources, allowing the system to recover seamlessly from node or application failures. Combined, these capabilities allow Spark Streaming to handle large-scale, real-time workloads reliably and efficiently, even in the face of unexpected system interruptions.
Would You Like to Know More About Data Science? Sign Up For Our Data Science Course Training Now!
Scalability and Resource Management
- Horizontal Scalability: Easily scale across multiple nodes in a cluster using Spark’s distributed architecture.
- Dynamic Resource Allocation: Automatically adjusts executor resources based on workload to optimize performance.
- Cluster Managers Support: Works with YARN, Mesos, and Kubernetes for flexible and efficient resource management.
- Load Balancing: Evenly distributes tasks across executors to prevent bottlenecks Apache Spark Certification.
- Backpressure Mechanism: Dynamically controls data ingestion rate to prevent overwhelming the system during high load.
- Parallelism Control: Tune parallelism settings (spark.default.parallelism, spark.streaming.concurrentJobs) to match data volume and processing needs.

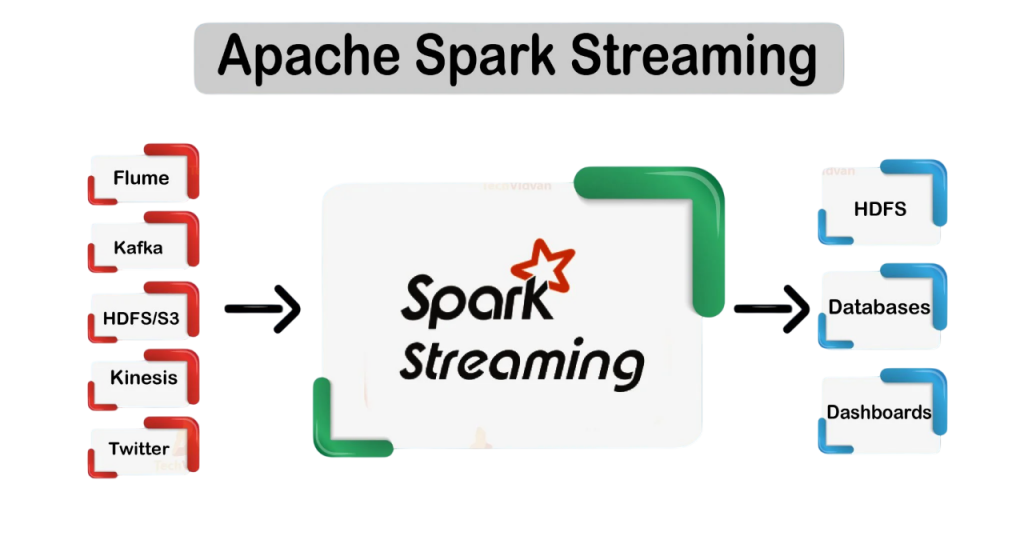
Integration with Streaming Sources
- Apache Kafka: Natively supported for high-throughput, low-latency data ingestion from distributed message queues.
- File Systems: Supports streaming from HDFS, S3, and local file systems by monitoring directories for new files Scala Certification .
- Socket Streams: Useful for testing or simple use cases by reading text data from TCP sockets.
- Apache Flume: Can integrate with Flume for log aggregation and event collection pipelines.
- Rate Source: Built-in synthetic data source for testing streaming pipelines.
- Custom Sources: Developers can implement custom receivers using Spark’s DataSource API for specialized use cases.
- Scalable Architecture: Scale up or down based on workload to optimize infrastructure costs.
- Efficient Resource Utilization: Dynamic resource allocation ensures you’re only using what you need.
- Batch Interval Tuning: Adjust micro-batch intervals to balance latency and resource consumption.
- Cluster Manager Choice: Deploy on YARN, Apache Pig Kubernetes, or Mesos based on cost and operational needs.
- Cloud Integration: Compatible with cloud services (e.g., AWS, Azure, GCP) for cost-effective, on-demand scaling.
- Caching and Persistence: Reduce redundant computations to improve performance without increasing costs.Cost and Performance Balance
- Monitoring and Optimization: Use Spark UI and external tools to track performance and fine-tune resources accordingly.
- Hadoop MapReduce: Spark is much faster due to in-memory processing.
- Apache Storm: Storm is purely for stream processing, while Spark supports both batch and stream.
- Apache Flink: Flink is close in real-time performance, but Spark has broader adoption and a more extensive community.
Gain Your Master’s Certification in Data Science Training by Enrolling in Our Big Data Analytics Master Program Training Course Now!
Use Cases Across Industries
Apache Spark Streaming is widely used across various industries for real-time data processing and analytics. In finance, it powers fraud detection systems by analyzing transaction patterns as they occur. E-commerce and retail companies use it to provide personalized recommendations and monitor customer behavior in real time. In the telecommunications sector, Spark Streaming helps monitor network traffic, detect anomalies, and ensure service reliability. Healthcare organizations leverage it for processing live health data from wearable devices Apache Spark Certification and supporting real-time diagnostics. In manufacturing, it enables predictive maintenance by analyzing sensor data from equipment. Across industries, Scalability and Resource Management, Spark Streaming delivers the speed and reliability required to turn real-time data into immediate business value.
Preparing for Data Science Job? Have a Look at Our Blog on Data Science Interview Questions & Answer To Acte Your Interview!
Cost and Performance Balance
Comparisons with Other Tools
When compared to other big data tools like Apache Flink, Storm, and Hadoop, Spark maintains a strong position:
Spark’s flexibility to support different types of workloads from a single engine gives it a competitive edge.
Conclusion
Apache Spark continues to evolve with the changing needs of big data and real-time analytics. Its speed, scalability, and flexibility make it uniquely positioned to handle complex data pipelines and real-time applications efficiently. With growing community support, a strong ecosystem, and robust industry adoption, Spark is expected to remain the dominant platform for real-time data analytics in the foreseeable future Data Science Training . Whether it’s fraud detection in finance, Integration with Streaming Sources, recommendation engines in e-commerce, or sensor analytics in manufacturing, Spark is delivering high-value insights when they matter most. As businesses continue to prioritize data-driven decision-making, the demand for real-time capabilities will only increase and Spark will be right at the center of that evolution.




