
Last updated on 06th Oct 2025| 10540
- Introduction
- What is Apache HBase?
- The Evolution: Why HBase was Needed
- Apache HBase Architecture
- HBase Data Model Explained
- Key Features of HBase
- Use Cases of Apache HBase
- Integration of HBase with Hadoop Ecosystem
- Conclusion
Introduction
As digital ecosystems continue to expand, the volume, velocity, and variety of data are growing beyond the capabilities of traditional relational database systems. Businesses generate terabytes to petabytes of data daily through logs, clickstreams, sensor data, social media, and transactions. This surge has compelled enterprises to explore storage solutions that can scale seamlessly, offer real-time access, and maintain performance at massive volumes. To navigate this data explosion effectively, professionals need robust Data Science Training empowering them to design intelligent systems, optimize data pipelines, and extract actionable insights from complex, high-velocity datasets. In this context, Apache HBase emerges as a high-performance, column-oriented NoSQL database designed to store and process huge, sparse datasets in a distributed environment.
What is Apache HBase?
Apache HBase is a distributed, scalable, and non-relational (NoSQL) database modeled after Google’s Bigtable and written in Java. It is built on top of the Hadoop Distributed File System (HDFS) and provides real-time read/write access to data. Unlike traditional RDBMSs, HBase doesn’t rely on fixed schemas and isn’t suitable for transactional applications, but it excels when handling large volumes of unstructured or semi-structured data. To orchestrate and manage such workloads efficiently across distributed clusters, Apache Hadoop YARN plays a pivotal role acting as the resource manager that coordinates compute tasks, optimizes scheduling, and ensures scalability across diverse data processing engines. HBase is ideal for use cases where data grows fast, is sparsely populated, and requires high throughput. It is tightly integrated with the Hadoop ecosystem and supports features like MapReduce for batch processing, Apache Hive for SQL-like queries, and Apache Phoenix for enhanced query capabilities. HBase is particularly valuable for time-series data, logs, and applications that require random, real-time access to very large datasets.
Interested in Obtaining Your Data Science Certificate? View The Data Science Online Training Offered By ACTE Right Now!
The Evolution: Why HBase was Needed
Traditional relational databases were designed decades ago when data was small and structured. With the growth of the internet and cloud computing, new requirements arose demanding scalable, distributed systems capable of handling massive, diverse datasets. To meet these demands, understanding How to install Apache Spark becomes a foundational step, enabling developers to build high-performance data pipelines and unlock real-time analytics across modern infrastructures.
- Schema flexibility: Modern applications deal with data in various formats that don’t fit neatly into tables.
- Horizontal scalability: RDBMSs scale vertically (adding more power to a single machine), which is costly and has limits.
- High throughput: Applications like social networks and IoT platforms generate millions of read/write operations per second.
- Latency-sensitive access: Some applications need real-time access to a portion of huge datasets without scanning everything.
HBase addresses these needs by supporting billions of rows and millions of columns, distributed across commodity hardware. It provides random, real-time read/write access and integrates well with big data architectures.
To Explore Data Science in Depth, Check Out Our Comprehensive Data Science Online Training To Gain Insights From Our Experts!
Apache HBase Architecture
Apache HBase Architecture follows a master-slave architecture, comprising several components that together manage the storage and processing of data efficiently. To understand how such systems scale across distributed environments, exploring What Is MapReduce is essential it introduces the programming model that underpins parallel data processing, fault tolerance, and task distribution in Hadoop ecosystems.
Main Components:
- HMaster: The master node that coordinates region servers, handles schema changes, and balances the load across the cluster.
- Region Server: Handles read/write requests, manages regions (subsets of tables), and communicates with HDFS for storage.
- Region: A subset of a table containing a range of rows. Regions are the unit of distribution and scalability.
- HFile: The actual file format that stores HBase data on HDFS. Optimized for fast reads.
- MemStore: An in-memory write buffer where data is temporarily stored before being flushed to disk.
- ZooKeeper: Manages coordination, leader election, and cluster metadata. Ensures high availability.
When a client sends a request, it contacts ZooKeeper to locate the correct region server, then interacts directly with that server. Writes go to the Write-Ahead Log (WAL) and MemStore, while reads are served from BlockCache or HFiles.

HBase Data Model Explained
HBase is a NoSQL database that is powerful and has a data model which is notably different from the one used in traditional relational databases. Essentially, HBase acts on data through flexible, schema-less tables where each uniquely identified row thus allowing each row to have dynamic column structures. In addition to that, column families are the logical groupings that not only allow different storage but also provide a way for column qualifiers to give even more specific data. Versioning that is quite advanced can be found at every data point or cell by the combination of row key, column family, qualifier, and timestamp. To fully grasp these structural intricacies, targeted Data Science Training is invaluable equipping learners with the knowledge to navigate NoSQL architectures and optimize data modeling for scalable analytics. Consequently, the design is one that multiple data versions can be stored at the same time thus HBase becomes very beneficial in handling sparse and semi-structured datasets as seen in cases where traditional relational databases. Moreover, HBase’ architecture is less confined to structures as it offers great flexibility in which rows can have different columns and complex, growing data models that can cleanly accommodate new data requirements can be supported.
Gain Your Master’s Certification in Data Science Training by Enrolling in Our Data Science Master Program Training Course Now!
Key Features of HBase
Apache HBase is a robust database solution that allows it to stand out in the big data environment, maintaining excellent performance and scalability across distributed computing environments. Using its groundbreaking design, HBase gives companies the ability to store billions of rows and have millions of columns while still providing user-friendly, real-time, column-based access to the complex data.
The platform’s schema-on-read flexibility lets schema evolve with the data, which is further supported by automatic sharding that distributes the data in region servers in a very efficient way. Therefore, combining native integration with various Hadoop ecosystem instruments such as HDFS, Hive, and MapReduce, HBase is able to offer strong consistency as well as advanced optimization features like versioning, Bloom filters, and data compression. There are many such combinations of features that make HBase a very attractive platform for heavy-duty enterprise use-cases when the need for high-speed data processing, fault-tolerance, and a storage solution that is adaptable and can effortlessly deal with changing analytical requirements arise.
Are You Preparing for Data Science Jobs? Check Out ACTE’s Data Science Interview Questions and Answers to Boost Your Preparation!
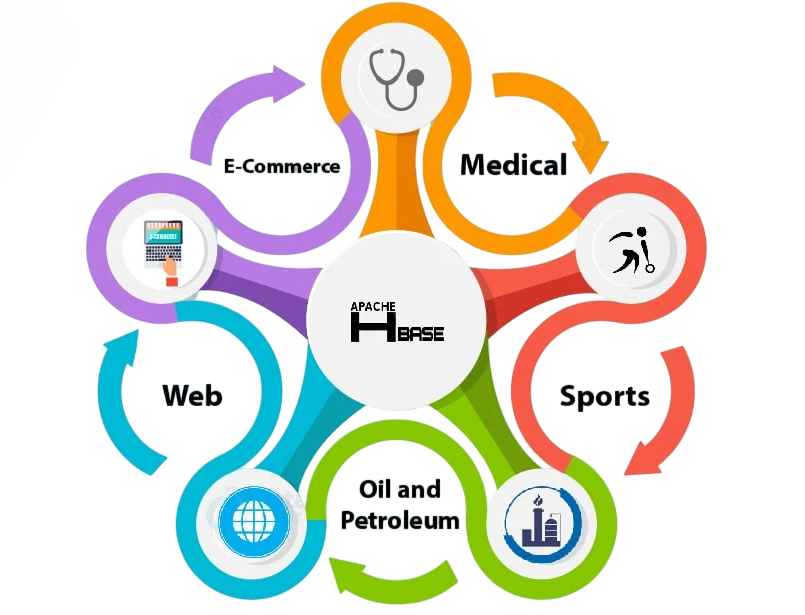
Use Cases of Apache HBase
Apache HBase powers mission-critical applications across industries that demand high throughput and real-time data access. To complement this with scalable stream processing and low-latency analytics, Exploring Spark’s Real-Time Parallel capabilities becomes essential enabling developers to build responsive data pipelines that integrate seamlessly with HBase for dynamic decision-making.
Common Use Cases:
- Time-Series Data: Store and retrieve time-stamped sensor or financial data efficiently.
- Real-Time Analytics: Build dashboards that reflect live transactional or behavioral data.
- Content Management: Large-scale storage for document metadata, images, or media.
- User Profile Stores: Maintain dynamically evolving data for millions of users.
- Message Queues: Use HBase to implement scalable, persistent queues with tracking.
- Search Engines: Backend data storage for index metadata and clickstream data.
Industry Examples:
- Facebook: Uses HBase for real-time messaging infrastructure.
- Yahoo!: Uses HBase to support content indexing and personalization services.
- Adobe: Manages cloud services metadata in HBase.
- eBay: Handles product recommendations and search results using HBase.
These examples illustrate how HBase addresses the unique challenges of high-scale, low-latency data environments.
Integration of HBase with Hadoop Ecosystem
Apache HBase doesn’t work in isolation; it is a core component of the Hadoop ecosystem and integrates well with other big data tools. To understand how structured data is queried and managed within this ecosystem, exploring What is Apache Hive becomes essential offering insights into Hive’s SQL-like interface, schema flexibility, and its role in simplifying data analysis over large datasets.
- HDFS: All HBase data is stored in HDFS, ensuring scalability and fault tolerance.
- MapReduce: Enables batch processing of HBase tables.
- Apache Hive: Supports SQL-like querying on HBase tables.
- Apache Phoenix: Adds JDBC support and full SQL over HBase.
- Apache Pig: Can read/write HBase tables for data transformations.
- Apache Flume & Sqoop: Used for ingesting data into HBase from logs or RDBMSs.
- Apache Spark: Spark can read/write HBase tables using connectors for ML and real-time processing.
- ZooKeeper: Coordinates HBase clusters and manages distributed metadata.
This deep integration allows HBase to be a flexible backend for various data workflows, from real-time ingestion to machine learning.
Conclusion
Apache HBase is an essential technology in the toolkit of organizations grappling with large-scale, real-time, non-relational data challenges. Its ability to handle petabyte-scale datasets, provide real-time reads and writes, and integrate with the broader Hadoop ecosystem makes it a go-to solution for many big data applications. As more businesses move toward event-driven architectures, IoT, and machine learning, the demand for systems like HBase will only increase. While newer NoSQL databases like Cassandra, MongoDB, or Google Bigtable offer alternatives, HBase continues to hold a strong position due to its tight Hadoop integration, reliable consistency model, and open-source support. To work effectively with such technologies, comprehensive Data Science Training is essential equipping professionals with the skills to architect scalable solutions and analyze complex datasets in real time. For organizations seeking a scalable, fault-tolerant, and performant data store for large volumes of semi-structured data, Apache HBase remains a compelling choice.




