
Last updated on 08th Dec 2021| 5029
Apache Spark comes in a compressed tar/zip files hence installation on windows is not much of a deal as you just need to download and untar the file.
- Introduction of Apache Spark
- Prerequisites
- Install Apache Spark on Windows
- Conclusion
- Apache Spark is an open-supply framework that approaches big volumes of movement information from a couple of sources. Spark is utilized in allotted computing with system gaining knowledge of applications, information analytics, and graph-parallel processing.
- This manual will display you a way to deployation Apache Spark on Windows 10 and take a look at the installation.
Introduction of Apache Spark
- A device walking Windows 10.
- A person account with administrator privileges (required to put in software, alter record permissions, and alter device PATH) Command Prompt or Powershell.
- A device to extract .tar files, including 7-Zip.
Prerequisites
Install Apache Spark on Windows
Installing Apache Spark on Windows 10 might also additionally appear complex to beginner users, however this easy academic will have you ever up and running. If you have already got Java eight and Python three installed, you could pass the primary steps:-
1. Step 1: Install Java eight. Apache Spark calls for Java eight.
2. Step 2: Install Python.
3. Step 3: Download Apache Spark.
4. Step 4: Verify Spark Software File.
5. Step 5: Install Apache Spark.
6. Step 6: Add winutils.exe File.
7. Step 7: Configure Environment Variables.
8. Step 8: Launch Spark.
- If Java is hooked up, it’ll reply with the subsequent output:
- Windows CLI output for Java model. Your model can be different. The 2d digit is the Java model – on this case, Java 8.
- If you don’t have Java hooked up:
- Open a browser window, and navigate to https://java.com/en/down load/.
- Click the Java Download button and store the report to a place of your choice.
- Once the down load finishes double-click on the report to put in Java.
- To set up the Python bundle manager, navigate to https://www.python.org/ to your net browser.
- Mouse over the Download menu alternative and click on Python three.eight.three. three.eight.three is the modern-day model on the time of writing the article.
- Once the down load finishes, run the file.
- Near the lowest of the primary setup conversation container, take a look at off Add Python three.eight to PATH. Leave the opposite container checked.
- Next, click on Customize set up.
- You can go away all containers checked at this step, or you may uncheck the alternatives you do now no longer want.
- Click Next.
- Select the container Install for all customers and go away different containers as they are.
- Under Customize set up location, click on Browse and navigate to the C drive. Add a brand new folder and call it Python.
- Select that folder and click on OK.
- Click Install, and permit the set up complete.
- When the set up completes, click on the Disable direction duration restrict alternative at the lowest after which click on Close.
- If you’ve got got a command spark off open, restart it. Verify the set up through checking the model of Python:
- The output must print Python three.eight.three.
- Open a browser and navigate to https://spark.apache.org/downloads.html.
- Under the Download Apache Spark heading, there are drop-down menus. Use the contemporary non-preview version.
- In our case, in Choose a Spark launch drop-down menu choose 2.4.5 (Feb 05 2020).
- In the second one drop-down Choose a package deal type, go away the choice Pre-constructed for Apache Hadoop 2.7.
- Click the spark-2.4.5-bin-hadoop2.7.tgz link.
- A web page with a listing of mirrors masses wherein you may see specific servers to down load from. Pick any from the listing and keep the document for your Downloads folder.
- Verify the integrity of your down load with the aid of using checking the checksum of the report. This guarantees you’re operating with unaltered, uncorrupted software.
- Navigate again to the Spark Download web page and open the Checksum link, ideally in a brand new tab.
- Next, open a command line and input the subsequent command: certutil -hashfile c:usersusernameDownloadsspark-2.4.5-bin-hadoop2.7.tgz SHA512
- Change the username on your username. The gadget presentations a protracted alphanumeric code, along side the message Certutil: -hashfile finished successfully.
- Compare the code to the only you opened in a brand new browser tab. If they match, your down load report is uncorrupted.
- Installing Apache Spark entails extracting the downloaded report to the preferred location.
- Create a brand new folder named Spark withinside the root of your C: drive. From a command line, input the following:
- In Explorer, discover the Spark report you downloaded.
- Right-click on the report and extract it to C:Spark the usage of the device you’ve got got for your system (e.g., 7-Zip).
- Now, your C:Spark folder has a brand new folder spark-2.4.5-bin-hadoop2.7 with the important documents inside.
- Navigate to this URL https://github.com/cdarlint/winutils and within the bin folder, find winutils.exe, and click on it.
- Find the Download button at the proper facet to down load the document.
- Now, create new folders Hadoop and bin on C: the use of Windows Explorer or the Command Prompt.
- Copy the winutils.exe document from the Downloads folder to C:hadoopbin.
- Click Start and sort surroundings.
- Select the end result categorised Edit the machine surroundings variables.
- A System Properties conversation field appears. In the lower-proper corner, click on Environment Variables after which click on New withinside the subsequent window.
- For Variable Name kind SPARK_HOME.
- For Variable Value kind C:Sparkspark-2.4.5-bin-hadoop2.7 and click on OK. If you modified the folder route, use that one instead.
- In the pinnacle field, click on the Path entry, then click on Edit. Be cautious with enhancing the machine route. Avoid deleting any entries already at the list.
- You must see a field with entries at the left. On the proper, click on New.
- The machine highlights a brand new line. Enter the route to the Spark folder C:Sparkspark-2.4.5-bin-hadoop2.7bin. We endorse using %SPARK_HOME%bin to keep away from feasible troubles with the route.
- Repeat this method for Hadoop and Java.
- For Hadoop, the variable call is HADOOP_HOME and for the price use the route of the folder you created earlier: C:hadoop. Add C:hadoopbin to the Path variable field, however we endorse using %HADOOP_HOME%bin.
- For Java, the variable call is JAVA_HOME and for the price use the route in your Java JDK directory (in our case it’s C:Program FilesJavajdk1.8.0_251).
- Click OK to shut all open windows.
- To begin Spark, enter:
- The device have to show numerous traces indicating the reputation of the application. You might also additionally get a Java pop-up. Select Allow get entry to to continue.
- Finally, the Spark brand appears, and the set off shows the Scala shell.
- Open an internet browser and navigate to http://localhost:4040/.
- You can update localhost with the call of your device.
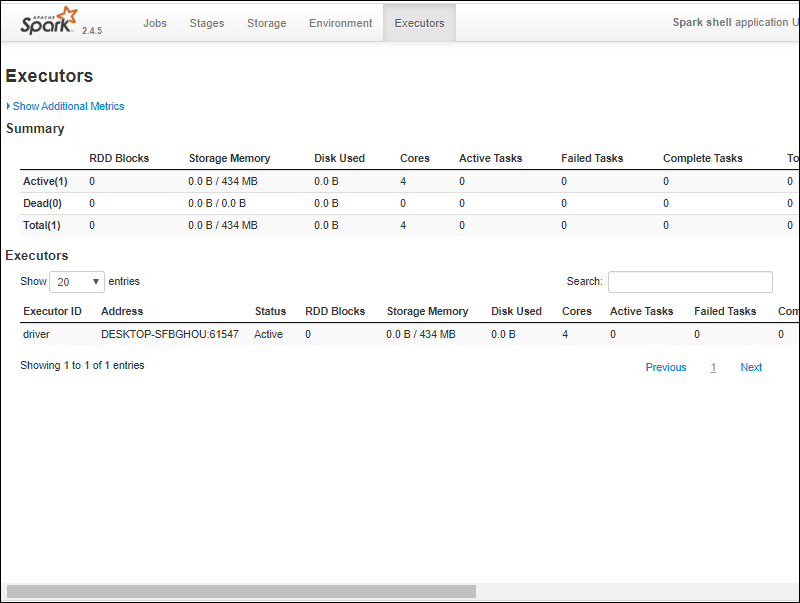
- You have to see an Apache Spark shell Web UI. The instance beneath indicates the Executors page.
- To go out Spark and near the Scala shell, press ctrl-d withinside the command-set off window.
Step 1: Install Java 8
Apache Spark calls for Java 8. You can test to peer if Java is hooked up the use of the command prompt.Open the command line with the aid of using clicking Start > kind cmd > click on Command Prompt.Type the subsequent command withinside the command prompt:-

Learn Advanced Apache Spark Certification Training Course to Build Your Skills
Weekday / Weekend BatchesSee Batch DetailsStep 2: Install Python
Step 3: Download Apache Spark
Step 4: Verify Spark Software File
Step 5: Install Apache Spark
Step 6: Add winutils.exe File
Download the winutils.exe document for the underlying Hadoop model for the Spark set up you downloaded:-
Step 7: Configure Environment Variables
Configuring surroundings variables in Windows provides the Spark and Hadoop places in your machine PATH. It permits you to run the Spark shell at once from a command spark off window:-
Step 8: Launch Spark
Open a brand new command-set off window the usage of the right-click on and Run as administrator:-
Conclusion
You need to now have a operating set up of Apache Spark on Windows 10 with all dependencies installed. Get began out jogging an example of Spark to your Windows environment.Our inspiration is to additionally analyze greater approximately what Spark DataFrame is, the features, and the way to use Spark DataFrame whilst gathering data.




