
Last updated on 10th Oct 2025| 10393
- The Evolution of Databases
- Why Cassandra is Revolutionary
- Architecture and Data Distribution Model
- CAP Theorem in Cassandra
- Replication Strategies
- High Availability and Fault Tolerance
- Hands-On Implementation
- Use Cases Across Industries
- Conclusion
The Evolution of Databases
Data storage and management have come a long way from traditional flat files and relational database management systems (RDBMS). The digital explosion over the past two decades has introduced complexities in volume, velocity, and variety of data ushering in a demand for systems that could scale dynamically. While RDBMS systems served well for structured data with well-defined schemas, they began to fall short when enterprises needed flexibility, high availability, and real-time processing. This need led to the birth of NoSQL databases, each designed to overcome specific limitations of relational models Data Science Training. Among these, Apache Cassandra emerged as a leader offering a decentralized, highly available, Modern Databases and fault-tolerant approach to managing massive datasets. Understanding Cassandra today is essential for any professional aspiring to solve real-world data problems in modern computing. Databases have evolved from traditional relational models to flexible, scalable NoSQL systems. Early databases focused on structured data and consistency, while modern systems prioritize performance, Evolution of Modern Database, availability, and scalability. This evolution supports big data, real-time processing, and global applications meeting the complex demands of today’s dynamic, data-driven environments.
Why Cassandra is Revolutionary
Cassandra stands out among modern databases due to its masterless architecture, linear scalability, and built-in replication. Originally developed at Facebook and later open-sourced under the Apache Foundation, Cassandra is purpose-built to handle real-time, write-intensive workloads with ease. Unlike traditional databases that have a single point of failure or performance bottlenecks, Cassandra’s peer-to-peer What is Splunk Rex structure ensures that every node is equal. This enables true horizontal scalability and resilience across multiple data centers. Furthermore, Cassandra supports schema-free design, allowing organizations to quickly adapt to changing data structures without extensive reengineering.
Interested in Obtaining Your Data Science Certificate? View The Data Science Online Training Offered By ACTE Right Now!
Architecture and Data Distribution Model
At the core of Cassandra’s architecture is a ring-based distributed system. Each node in the Cassandra cluster is responsible for a portion of the data, defined using consistent hashing. Data is distributed using a partitioner, and multiple copies (replicas) of the data are stored on different nodes to ensure durability and fault tolerance.
Key architectural highlights:
- Peer-to-peer communication: All nodes are equal; there’s no master-slave hierarchy.
- Gossip protocol: Nodes exchange state information periodically for cluster awareness Elasticsearch Nested Mapping .
- Snitch: Helps determine data center and rack placement for replication.
- SSTables and memtables: Mechanisms to handle data writes and flush to disk efficiently.
This architecture ensures Cassandra can easily handle hundreds of terabytes of data while maintaining high write throughput and low latency.
To Explore Data Science in Depth, Check Out Our Comprehensive Data Science Online Training To Gain Insights From Our Experts!
CAP Theorem in Cassandra
TheCAP Theorem in Cassandra Consistency, Availability, and Partition Tolerance is fundamental in distributed system design. Cassandra is designed to prioritize Availability and Partition Tolerance while offering tunable consistency. The CAP theorem states that a distributed database can only guarantee two out of three properties: Consistency, Availability, and Partition Tolerance. Apache Cassandra prioritizes Availability and Partition Tolerance, making it highly resilient to network failures Data Science Training and ensuring continuous uptime.
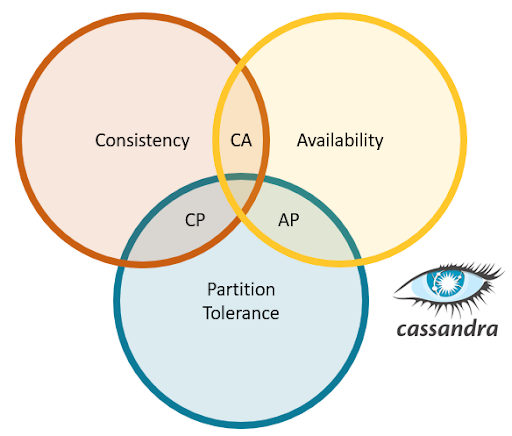
Instead of immediate consistency, Cassandra offers eventual consistency, allowing data to be replicated asynchronously across multiple nodes. This design ensures that even if some nodes are unreachable, the system remains operational and responsive. By tuning consistency levels, users can balance between strong consistency and high availability based on their application’s needs. This flexibility allows applications to meet various SLA (Service Level Agreement) requirements, whether for banking systems needing strong consistency or social platforms where availability is paramount.

Replication Strategies
Replication is a cornerstone of Cassandra’s fault tolerance. When data is written, it is replicated across multiple nodes based on the defined replication factor and strategy. Cassandra uses replication strategies to copy data across multiple nodes, ensuring fault tolerance and high availability. The two main strategies are SimpleStrategy and NetworkTopologyStrategy. SimpleStrategy is ideal for single data center setups Apache Hive vs HBase Guide , distributing replicas across nodes in a ring. NetworkTopologyStrategy is suited for multiple data centers, allowing configuration of replica counts per data center to improve resilience and reduce latency. Replication ensures that if one node fails, data is still accessible from other replicas. This approach supports Cassandra’s distributed nature, enabling continuous uptime and durability of data across different environments. Cassandra supports rack-aware and data-center-aware replication, helping organizations meet disaster recovery goals and regional data compliance standards. Its hinted handoff and read repair mechanisms ensure eventual consistency and data healing over time.
Gain Your Master’s Certification in Data Science Training by Enrolling in Our Data Science Master Program Training Course Now!
High Availability and Fault Tolerance
Cassandra’s architecture is natively fault-tolerant. Since all nodes can handle requests, and data is replicated across them, there is no single point of failure. If a node fails, others seamlessly continue to serve data.
Key availability features:
- Anti-entropy repairs: Regular processes that sync data between replicas.
- Read repair: Fixes inconsistencies during read operations.
- Hinted handoff: Ensures writes are eventually applied even if some nodes are temporarily unavailable.
These features, combined with automatic load balancing and rolling upgrades, make Cassandra a production-grade solution for always-on applications Data Architect Salary .
Hands-On Implementation
Cassandra training goes beyond theory, focusing on real-world, hands-on implementation. Professionals learn to:
- Install and configure Cassandra on local or cloud environments.
- Create keyspaces, tables, and indexes.
- Perform CRUD operations using Cassandra Query Language (CQL) Scala Certification .
- Monitor performance with tools like nodetool and third-party integrations.
- Set up multi-node clusters and configure replication strategies.
Hands-on labs also cover backup and recovery, cluster scaling, and simulating node failures to test fault tolerance. Practical exposure prepares professionals to manage Cassandra systems confidently in production environments.
Are You Preparing for Data Science Jobs? Check Out ACTE’s Data Science Interview Questions and Answers to Boost Your Preparation!
Use Cases Across Industries
Cassandra’s adoption spans diverse industries due to its ability to handle massive volumes of distributed data with low latency. Prominent use cases include:- Finance: Real-time fraud detection, transaction logs, and compliance reporting.
- E-commerce: Product catalogs, shopping carts, inventory management.
- Telecommunications: Call data records, network usage statistics Spark SQL .
- Healthcare: Patient records, IoT device monitoring.
- IoT: Time-series data ingestion from millions of sensors.
- Social Media: Feed generation, messaging, and user preferences.
Companies like Netflix, Uber, Instagram, and Spotify use Cassandra to power their backend systems that demand both speed and reliability.
Conclusion
Apache Cassandra represents a revolution in modern data management. It’s built for scale, resilience, and real-time performance traits that today’s data-driven businesses demand. With data growing exponentially and systems becoming increasingly distributed, professionals who understand and can manage CAP Theorem in Cassandra are in a powerful position to contribute to the future of technology. Cassandra training empowers learners with the practical and theoretical knowledge required to build robust Data Science Training high-performing data systems. Whether you’re a developer, database admin, or data architect, Modern Databases, Cassandra offers a skillset that is both future-proof and in high demand. Now is the time to embrace this data revolution Evolution of Modern Database. Master Cassandra and change how the world processes information.




