Last updated on 18th Jan 2022| 3923
- What is AWS Data Pipeline?
- Getting to AWS Data Pipeline
- Pursue AWS
- For what reason do we want an Data Pipeline?
- What is the uses of AWS Data Pipeline?
- AWS Data Pipeline – Idea
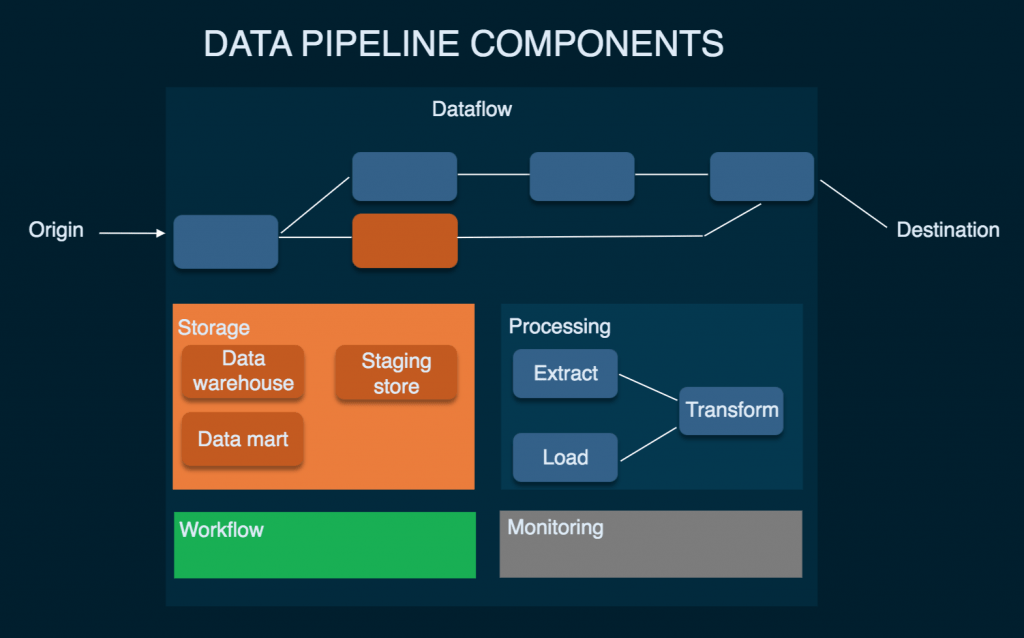
- Parts of AWS Data Pipeline
- What are the essentials for setting up an AWS Data pipeline?
- The most effective method to Make an AWS Data Pipeline
- Guidelines to screen the running AWS Data Pipeline
- Conclusion
- A pipeline definition indicates the business rationale of your Data to the board. For more Data, see Pipeline Definition Record Language structure. A pipeline timetables and runs assignments by making Amazon EC2 occurrences to play out the characterized work exercises. You transfer your pipeline definition to the pipeline and afterward actuate the pipeline. You can alter the pipeline definition for a running pipeline and actuate the pipeline again for it to produce results. You can deactivate the pipeline, adjust an Data source, and afterward enact the pipeline once more. At the point when you are done with your pipeline, you can erase it.
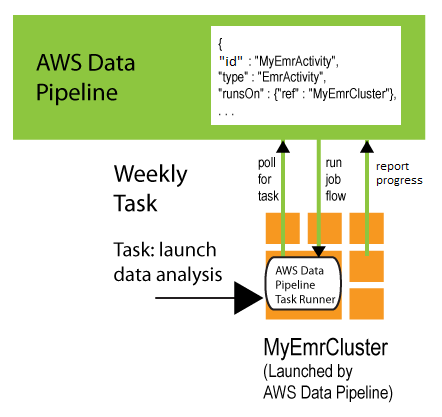
- Task Sprinter surveys for errands and afterward plays out those undertakings. For instance, Errand Sprinter could duplicate log records to Amazon S3 and send off Amazon EMR bunches. Task Sprinter is introduced and runs naturally on assets made by your pipeline definitions. You can compose a custom assignment sprinter application, or you can utilize the Errand Sprinter application that is given by AWS Data Pipeline. For more Data, see Undertaking Sprinters.
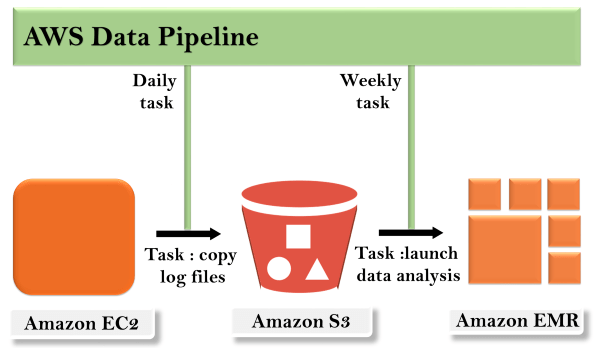
- For instance, you can utilize AWS Data Pipeline to chronicle your web server’s logs to Amazon Basic Stockpiling Administration (Amazon S3) every day and afterward run a week-by-week Amazon EMR (Amazon EMR) group over those logs to produce traffic reports. AWS Data Pipeline plans the day-by-day assignments to duplicate Data and the week after week errand to send off the Amazon EMR group. AWS Data Pipeline likewise guarantees that Amazon EMR trusts that the last day’s Data will be transferred to Amazon S3 before it starts its examination, regardless of whether there is an unanticipated postponement in transferring the logs.
- Assuming that you have an AWS account as of now, jump to the following assignment. On the off chance that you don’t have an AWS account, utilize the accompanying technique to make one.
- To make an AWS account
- Open https://portal.aws.amazon.com/charging/Data exchange.
- Adhere to the web-based directions.
- Some portion of the sign-up methodology includes getting a call and entering a confirmation code on the telephone keypad.
- Make IAM Jobs for AWS Data Pipeline and Pipeline Assets
- AWS Data Pipeline requires IAM jobs that decide the authorizations to perform activities and access AWS assets. The pipeline job decides the consents that AWS Data Pipeline has, and an asset job decides the authorizations that applications running on pipeline assets, for example, EC2 cases, have. You indicate these jobs when you make a pipeline. Regardless of whether you indicate a custom job and utilize the default jobs DataPipelineDefaultRole and DataPipelineDefaultResourceRole, you should initially make the jobs and append authorizations arrangements. For more Data, see IAM Jobs for AWS Data Pipeline.
What is AWS Data Pipeline?
AWS Data Pipeline is a web administration that you can use to robotize the development and change of Data. With AWS Data Pipeline, you can characterize Data-driven work processes, so that errands can be reliant upon the fruitful finish of past assignments. You characterize the boundaries of your Data changes and AWS Data Pipeline implements the rationale that you’ve set up.
The accompanying parts of AWS Data Pipeline cooperate to deal with your Data:
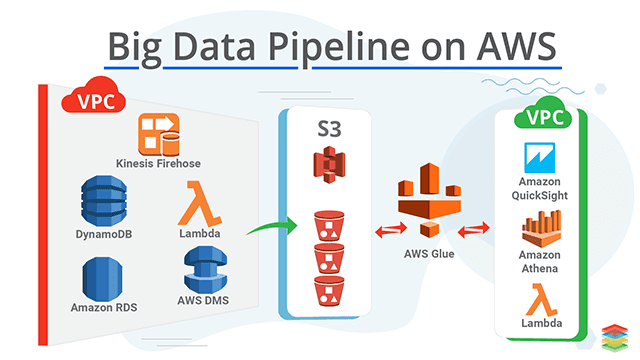
Getting to AWS Data Pipeline:
You can make, access, and deal with your pipelines utilizing any of the accompanying connection points:
AWS The executive’s Control center Gives a web interface that you can use to get to AWS Data Pipeline.
AWS Order Line Connection point (AWS CLI)- Gives orders to a wide arrangement of AWS administrations, including AWS Data Pipeline, and is upheld on Windows, macOS, and Linux. For more Data about introducing the AWS CLI, see AWS Order Line Point of interaction. For a rundown of orders for AWS Data Pipeline, see Data pipeline.
AWS SDKs – Gives language-explicit APIs and deals with large numbers of the association subtleties, for example, ascertaining marks, taking care of solicitation retries, and blunder taking care of. For more Data, see AWS SDKs.
Inquiry Programming interface Gives low-level APIs that you call utilizing HTTPS demands. Utilizing the Question Programming interface is the most immediate method for getting to AWS Data Pipeline, however, it necessitates that your application handles low-level subtleties, for example, creating the hash to sign the solicitation, and mistake taking care of. For more Data, see the AWS Data Pipeline Programming Interface Reference.
Pursue AWS:
At the point when you pursue Amazon Web Administrations (AWS), your AWS account is consequently pursued all administrations in AWS, including AWS Data Pipeline. You are charged distinctly for the administrations that you use. For more Data about AWS Data Pipeline utilization rates, see AWS Data Pipeline.

Learn Advanced AWS Database Certification Training Course to Build Your Skills
Weekday / Weekend BatchesSee Batch DetailsPermit IAM Directors (Clients and Gatherings) to Perform Essential Activities. To work with a pipeline, an IAM head (a client or gathering) in your record should be permitted to perform required AWS Data Pipeline activities and activities for different administrations as characterized by your pipeline.
To work on authorizations, the AWSDataPipeline_FullAccess oversaw approach is accessible for you to append to IAM directors. This oversaw approach permits the head to play out all activities that a client requires and the iam: PassRole activity on the default jobs utilized with AWS Data Pipeline when a custom job isn’t determined.
We strongly suggest that you cautiously assess this oversaw approach and limit consents just to those that your clients require. On the off chance that fundamental, utilize this strategy as a beginning stage, and eliminate authorizations to make a more prohibitive inline consents strategy that you can join to IAM administrators. For more Data and model authorizations arrangements, see an arrangement explanation like the accompanying model should be remembered for an approach connected to any IAM head that utilizes the pipeline. This assertion permits the IAM head to play out the PassRole activity on the jobs that a pipeline employments. On the off chance that you don’t utilize default jobs, supplant MyPipelineRole and MyResourceRole with the custom jobs that you make.
- {
- “Variant”: “2012-10-17”,
- “Articulation”: [
- {
- “Activity”: “iam:PassRole”,
- “Impact”: “Permit”,
- “Asset”: [
- “arn:aws:iam::*:role/MyPipelineRole”,
- “arn:aws:iam::*:role/MyResourceRole”
- ]
- }
- ]
- }
- The accompanying method shows how to make an IAM bunch, connect the AWSDataPipeline_FullAccess oversaw approach to the gathering, and afterward add clients to the gathering. You can involve this methodology for any inline strategy
- To make a client bunch DataPipelineDevelopers and join the AWSDataPipeline_FullAccess strategy
- Open the IAM console at https://console.aws.amazon.com/iam/.
- In the route sheet, pick Gatherings, Make New Gathering.
- Enter a Gathering Name, for instance, DataPipelineDevelopers, and afterward pick the Following stage.
- Enter AWSDataPipeline_FullAccess for Channel and afterward select it from the rundown.
- Pick the Following stage and afterward pick Make Gathering.
- To add clients to the gathering:
- Select the gathering you made from the rundown of gatherings.
- Pick Gathering Activities, Add Clients to Gathering.
- Select the clients you need to add from the rundown and afterward pick Add Clients to Gathering.
- Data managed by an organization might be natural as well. To deal with this Data, an organization needs to invest more energy and cash. Instances of such Data are exchange chronicles, Data from log documents, segment Data, and so on These lead to a lot of Data, which gets hard to make due.
- Not every one of the Data got or sent is of a similar document design, which prompts further difficulties. Data can be unstructured/viable. Its change is a tedious and testing process.
- To store Data is one more testing factor for an organization as the firm necessities to burn through cash on having its Data distribution center and an extra room that supports cloud use. Amazon Social Data set Assistance [RDS] and Amazon S3 are some enormous cloud-based extra rooms.
- The most urgent difficulty looked by organizations is the cash and time that they need to spend on keeping up with, putting away, handling, and changing these huge main parts of Data
- One can keep away from these difficulties when involving AWS Data Pipeline as it helps gather Data from different AWS administrations and spot it in a solitary area, similar to a center point. At the point when every one of the Data is put away in one spot, it turns out to be not difficult to deal with, keep up with, and share it routinely.
- Before you settle on a choice, here’s a definite report about AWS Data Pipeline, its utilization, benefits, engineering, parts, works, and its technique for working.
- With the assistance of AWS Data Pipeline, you can:
- Guarantee the accessibility of essential assets.
- Make jobs that arrange convoluted Data handling.
- Move the Data to any of the AWS administrations.
- Give the necessary stops/breaks for each errand.
- Deal with any related errands viably.
- Create a framework to inform any disappointments during the interaction.
- Move and change Data that is secured on-premises Data storehouses.
- Get the unstructured Data dissected and can move it to Redshift to make a couple of little questions.
- Shift even the log records from AWS Log to Amazon Redshift.
- Ensure Data through AWS’s Debacle Recuperation conventions, where the fundamental Data can be reestablished from the reinforcements.
- All in all, AWS Data Pipeline is utilized when one necessity a characterized course of Data sources and Data sharing for handling Data, according to the prerequisite of the clients. It’s an easy-to-understand administration that is profoundly utilized in the current business world.
- There are predefined sets of directions and codes which permit the client just to type the capacity’s name, and the assignment will occur. Through this, a pipeline can be made effortlessly.
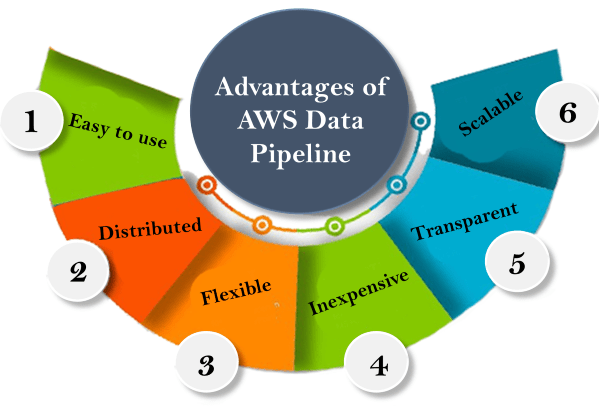
- AWS Data Pipeline can be utilized free of charge. Indeed, even its ‘Expert rendition’ is of less expense, which makes it reasonable for some and both of all shapes and sizes clients.
- If your capacity falls flat in the center/assuming a mistake happens, AWS Data Pipeline will get that specific movement retried consequently. With its disappointment warnings and quick reinforcement Data, it is not difficult to continue to attempt various capacities. This component makes AWS Data Pipeline more dependable.
- AWS Data Pipeline permits its clients to set their functioning terms rather than utilizing just the predefined set of capacities currently present in the application. This trademark guarantees adaptability for the clients and a compelling means to investigate and handle Data.
- Because of the adaptability of the AWS Data Pipeline, it is versatile to circulate work to many machines and cycle many documents.
- A point-by-point record of your full execution logs will be shipped off Amazon S3, making it more straightforward and predictable. You can likewise get to your business rationale’s assets for improving and investigating it, at whatever point important.
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
- The name, its put-away area, and its Data source’s configuration are recorded and are classified as “Data Hubs.” RedshiftDataNode, DynamoDBDataNode, S3DataNode, and SqlDataNode are completely upheld by AWS Data Pipeline.
- At the point when the SQL Questions are put to activity on the Data sets, they will quite often change the Data wellspring of the Data, called “Exercises”.
- At the point when the Exercises are planned, they are designated “Timetables.”
- To have an activity/movement acted in the AWS Data Pipeline, the client needs to meet the prerequisites/’Preconditions’. This activity must be done before booking the Exercises.
- The EMR bunch and Amazon EC2 are called ‘Assets’ since they are essential for the working of the AWS Data Pipeline.
- Any announcement concerning your AWS Data Pipeline is shipped off you through utilizing a caution or notice, and these are called ‘Activities. ‘
- The parts associated with building up correspondence between the client’s Data Pipeline and the AWS Administrations are in this classification.
- Examples allude to the gathering of pipeline parts which has the guidelines for playing out a specific undertaking.
- Endeavors manage the ‘retry’ choice that an AWS Data Pipeline offers to its clients if there should be an occurrence of a bombed activity.
- Aside from these, there are specific articles that AWS Data Pipeline uses, and they are:
- The “ShellCommandActivity” is utilized to identify mistakes from the Data log records.
- The info log document is put away in the S3 container, which is available in the “S3DataNode” input object.
- For the result, the “S3DataNode” object contains the necessary S3 can.
- AWS Data Pipeline employments “Ec2 Asset” to execute a movement. On the off chance that the document size is enormous, you can utilize an EMR bunch.
- Yes the name recommends, AWS Data Pipeline deals with meeting the preconditions before beginning a movement as opposed to trusting that the client will get it done.
- DynamoDBDataExists
- DynamoDBTableExists
- S3KeyExists and
- S3PrefixNotEmpty
- These are the different frameworks overseen preconditions.
- You can utilize ‘runsOn’/’workerGroup’ applications to indicate the preconditions you need to have before running a capacity in the AWS Data Pipeline. Notwithstanding, you can determine a ‘workgroup’ when you play out an action that meets the precondition set by you.
- Exists and
- ShellCommandPrecondition
- These 2 are the various sorts of Client oversaw preconditions.
- Errand to be Finished Before Utilizing AWS Data Pipeline:
- NOTE: Ensure you get done with these responsibilities before you begin making an AWS Data Pipeline.
- Having an AWS account is obligatory to benefit the administrations given by AWS, including AWS Data Pipeline. Adhere to the underneath guidelines to make an AWS account.
- Go to https://cutt.ly/dyDpNKC from any of your internet browsers.
- There’ll be a rundown of directions shown on your screen which should be followed.
- The last advance is to get a call with a confirmation code that should be entered on the telephone keypad.
- Draft the Required IAM Jobs [CLI or Programming interface Only]:
- IAM Jobs are significant for AWS Data Pipeline as they enroll the activities and assets the Pipeline can get to, and no one but they can be utilized. On the off chance that you are now acquainted with these, make a point to refresh your current form of IAM jobs. In any case, if you are new to these, make the IAM jobs physically.
- Open https://cutt.ly/XyDaxis in your internet browser.
- Select Jobs and snap “Make New Job.”
- Enter the job’s name as by the same token “DataPipelineDefaultRole” or “DataPipelineDefaultResourceRole”.
- To decide the job’s sort go to “Select Job Type.” Press SELECT from the “AWS Data Pipeline” for the IAM’s default job and the IAM’s Asset job, press SELECT from the “Amazon EC2 Job for Data Pipeline”.
- From the “Connect Strategy” page, you ought to choose “AWSDataPipelineRole” for the default job and “AmazonEC2RoleforDataPipelineRole” for the asset job and afterward press Subsequent stage.
- At long last, click Make Job structure on the “Audit” page.
- Guarantee that the “Activity”:” I am: PassRole” consent is predefined to both DataPipelineDefaultRole and DataPipelineDefaultResourceRole and to any custom jobs needed for getting to AWS Data Pipeline. You can likewise make a joint gathering with every one of the AWS Data Pipeline clients and give an oversaw strategy called “AWSDataPipeline_FullAccess,” which will allow the “Activity”:” I am: PassRole” authorization to every one of its clients absent a lot of postponement and exertion.
- Make Custom IAM Jobs and Make an Inline Strategy with the IAM Consents:
- As a substitute for the assignment referenced above, you can make two sorts of custom jobs for AWS Data Pipeline with an inline strategy that has the IAM consent for both jobs. The main kind of custom job ought to be like “DataPipelineDefaultRole” and ought to be utilized for utilizing Amazon EMR groups. The subsequent kind should uphold Amazon EC2 in AWS Data Pipeline and can be indistinguishable from that of “DataPipelineDefaultResourceRole.” Presently, create the inline strategy with the “Activity”:” I am: PassRole” for the CUSTOM_ROLE.
- You can make an AWS Data Pipeline either through a layout or through the control center physically.
- Go to http://console.aws.amazon.com/and open the AWS Data Pipeline console.
- Pick the required ‘area’ from the ‘route bar.’ In any event, when the locale is not the same as that of the area, it doesn’t make any difference.
- On the off chance that if the area you chose is new, the control center will show a ‘presentation’ where you should press ‘Begin now.’ However assuming the locale you chose is old, the control center will see the rundown of pipelines you have around there and start another pipeline, select ‘Make new pipeline.’
- Enter your Pipeline name in the ‘Name’ section and add the portrayal of your Pipeline in the Depiction segment.
- To decide the source, pick “Construct utilizing a layout” from which you ought to choose “Beginning utilizing ShellCommandActivity.”
- The ‘Boundaries’ section will open at this point. You should simply have the default upsides of both ‘S3 input envelope’ and ‘Shell order to run’ continue as before. Presently press the symbol that appears to be an envelope close to the ‘S3 yield organizer’, pick the cans and organizers you want, and afterward press SELECT.
- For planning the AWS Data Pipeline, you can either leave the default esteems, which makes the Pipeline run for at regular intervals in 60 minutes. Any other way, you can pick “Run once on pipeline actuation” to have this performed consequently.
- Under the section of ‘Pipeline Arrangement,’ you want not to transform anything, however, you can have the ‘logging’ either empowered or handicapped. The structure under the ‘S3 area for logs’ segment, pick any of your organizers/pails and press SELECT.
- Make a point to set the IAM jobs to ‘Default’ under the ‘Security/Access’ section.
- After guaranteeing everything is correct, click activate. If you need to add new preconditions or modify the existing Pipeline, select ‘Edit in Architect’.
- Congratulations! You have successfully created an AWS Data Pipeline.
- You can see/screen the working of AWS Data Pipeline on the ‘Execution subtleties’ page, which will consequently be shown on your screen after you begin running your Pipeline.
- Presently press UPDATE/F5 to invigorate and get the current announcements. In the event of no presently running ‘runs’, check on the off chance that the booked beginning is covered by ‘Start (in UTC)’ and the finish of the Pipeline by ‘End (in UTC)’ after which you can squeeze UPDATE.
- At the point when ‘Completed’ shows up as the situation with each article, it implies that the Pipeline did the booked jobs.
- On the off chance that there are inadequate assignments ready to go, go to its ‘Settings’ and attempt to investigate it.
- Open the Amazon S3 console and go to your ‘can/envelope’.
- There’ll be four subfolders with a name as “output.txt” and will be available just when the Pipeline runs for like clockwork in 60 minutes.
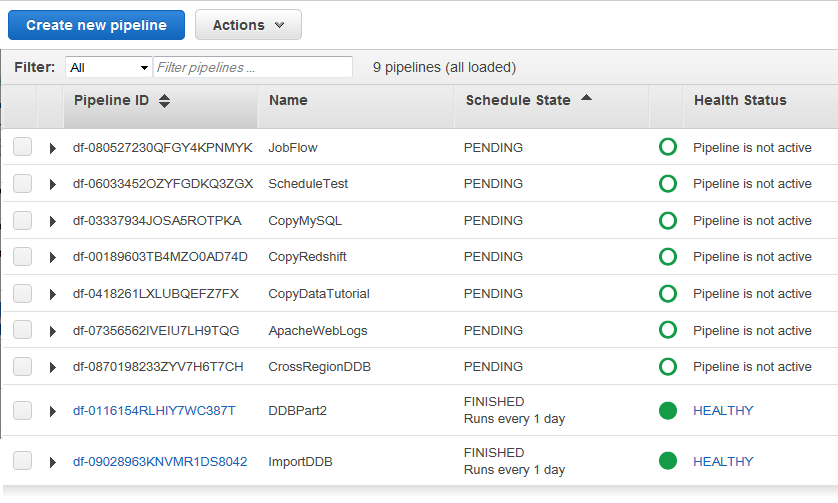
- Go to the ‘Rundown Pipelines’ page.
- Pick the Pipeline you need to erase.
- Press Activities and afterward click Erase.
- An affirmation discourse box will be shown. You should press Erase to erase the Pipeline.
- These are the various advances engaged with making, checking, and erasing an AWS Data Pipeline.
For what reason do we want an Data Pipeline?
The essential utilization of an Data Pipeline is to have a coordinated approach to dealing with business Data, which will lessen the time and cash spent on doing likewise. Organizations face many difficulties with regards to taking care of Data for a huge scope, and the following are a couple of their concerns:
What is the uses of AWS Data Pipeline?
Amazon Web Administration [AWS] Data Pipeline is assistance that can be utilized to deal with, change, and move Data, particularly business Data. This help can be computerized, and the Data-driven work processes can be set, to keep away from botches and long tedious working hours.
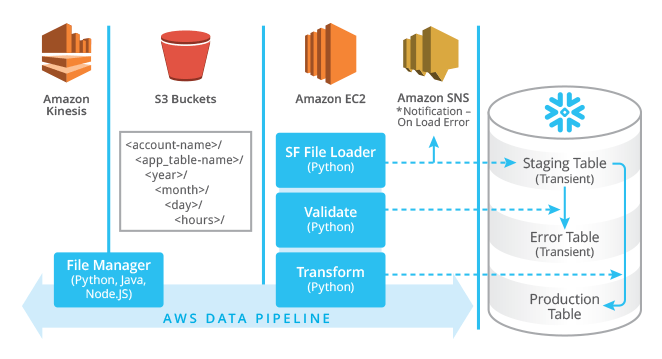
AWS Data Pipeline – Idea
AWS Data Pipeline manages an Data pipeline with 3 different Data spaces like Redshift, Amazon S3, and DynamoDB. The Data gathered from these three Data valves is shipped off the Data Pipeline. At the point when the Data arrives at the Data Pipeline, they are broken down and handled. The end-product of the handled Data is moved to the resulting valve, which can either be Amazon S3/Redshift/Amazon Redshift. This focus statement is the essential idea driving AWS Data Pipeline. However, is this web administration successful and sufficiently productive? We should discover its advantages and significance.
Advantages of Data Pipeline:
There are six huge advantages of AWS Data Pipeline, and they are:
Parts of AWS Data Pipeline:
Four principle parts remember different ideas that assist for the working of AWS Data Pipeline.

Get JOB Oriented AWS Database Training for Beginners By MNC Experts
Pipeline Definition: This arrangement with the principles and methodology engaged with imparting business rationale with the Data Pipeline. This definition has the accompanying Data:
Pipeline: There are three fundamental parts for a Pipeline, and they are:
Task Sprinter: As the name recommends, this application centers around surveying different undertakings, present in the Data Pipeline to perform/run them.
Precondition: This alludes to a bunch of explanations that characterize explicit conditions that must be met before a specific movement or activity happens in the AWS Data Pipeline.
What are the essentials for setting up an AWS Data pipeline?
A precondition alludes to a bunch of predefined conditions that should be met/be valid before running a movement in the AWS Data Pipeline. The two sorts of such requirements are:
Framework oversaw preconditions:
Client oversaw preconditions:
Make a Sign-up:
Required ‘Passrole’ Consent and Strategy for Predefined IAM Jobs:
The most effective method to Make an AWS Data Pipeline:
Guidelines to screen the running AWS Data Pipeline:
How might I see the created yield?
How might I erase a pipeline?
Conclusion:
AWS Data Pipeline is a web server that offers types of assistance to gather, screen, store, break down, change, and move Data on cloud-based stages. By utilizing this Pipeline, one will in general decrease their cash invested and the energy consumed in managing broad Data. With many organizations advancing and developing at a fast speed consistently, the requirement for AWS Data Pipeline is additionally expanding. Be a specialist in AWS Data Pipeline and art a fruitful vocation for yourself in this serious, advanced business world.