
Last updated on 12th Jul 2020| 1648
Big Data
Big Data refers to the datasets too large and complex for traditional systems to store and process. The major problems faced by Big Data majorly falls under three Vs. They are volume, velocity, and variety.
Do you know – Every minute we send 204 million emails, generate 1.8 million Facebook likes, send 278 thousand Tweets, and up-load 200,000 photos to Facebook.
Volume:
The data is getting generated in order of Tera to petabytes. The largest contributor of data is social media. For instance, Facebook generates 500 TB of data every day. Twitter generates 8TB of data daily.
Velocity:
Every enterprise has its own requirement of the time frame within which they have process data. Many use cases like credit card fraud detection have only a few seconds to process the data in real-time and detect fraud. Hence there is a need of framework which is capable of high-speed data computations.
Hadoop
Hadoop is the solution to above Big Data problems. It is the technology to store massive datasets on a cluster of cheap machines in a distributed manner. Not only this it provides Big Data analytics through distributed computing framework.
It is an open-source software developed as a project by Apache Software Foundation. Doug Cutting created Hadoop. In the year 2008 Yahoo gave Hadoop to Apache Software Foundation. Since then two versions of Hadoop has come. Version 1.0 in the year 2011 and version 2.0.6 in the year 2013. Hadoop comes in various flavors like Cloudera, IBM BigInsight, MapR and Hortonworks.
“Hadoop is a technology to store massive datasets on a cluster of cheap machines in a distributed manner”. It was originated by Doug Cutting and Mike Cafarella.
Doug Cutting’s kid named Hadoop to one of his toy that was a yellow elephant. Doug then used the name for his open source project because it was easy to spell, pronounce, and not used elsewhere.
Why Hadoop is Invented?
Let us discuss the shortcomings of the traditional approach which led to the invention of Hadoop –
1. Storage for Large Datasets
The conventional RDBMS is incapable of storing huge amounts of Data. The cost of data storage in available RDBMS is very high. As it incurs the cost of hardware and software both.
2. Handling data in different formats
The RDBMS is capable of storing and manipulating data in a structured format. But in the real world we have to deal with data in a structured, unstructured and semi-structured format.
3. Data getting generated with high speed:
The data in oozing out in the order of tera to peta bytes daily. Hence we need a system to process data in real-time within a few seconds. The traditional RDBMS fail to provide real-time processing at great speeds.
Core Components of Hadoop
Let us understand these Hadoop components in detail.
1. HDFS
Short for Hadoop Distributed File System provides for distributed storage for Hadoop. HDFS has a master-slave topology.
Master is a high-end machine where as slaves are inexpensive computers. The Big Data files get divided into the number of blocks. Hadoop stores these blocks in a distributed fashion on the cluster of slave nodes. On the master, we have metadata stored.
HDFS has two daemons running for it. They are :
NameNode : NameNode performs following functions –
- NameNode Daemon runs on the master machine.
- It is responsible for maintaining, monitoring and managing DataNodes.
- It records the metadata of the files like the location of blocks, file size, permission, hierarchy etc.
- Namenode captures all the changes to the metadata like deletion, creation and renaming of the file in edit logs.
- It regularly receives heartbeat and block reports from the DataNodes.
DataNode: The various functions of DataNode are as follows –
- DataNode runs on the slave machine.
- It stores the actual business data.
- It serves the read-write request from the user.
- DataNode does the ground work of creating, replicating and deleting the blocks on the command of NameNode.
- After every 3 seconds, by default, it sends heartbeat to NameNode reporting the health of HDFS.
Erasure Coding in HDFS
Till Hadoop 2.x replication is the only method for providing fault tolerance. Hadoop 3.0 introduces one more method called erasure coding. Erasure coding provides the same level of fault tolerance but with lower storage overhead.
Erasure coding is usually used in RAID (Redundant Array of Inexpensive Disks) kind of storage. RAID provides erasure coding via striping. In this, it divides the data into smaller units like bit/byte/block and stores the consecutive units on different disks. Hadoop calculates parity bits for each of these cell (units). We call this process as encoding. On the event of loss of certain cells, Hadoop computes these by decoding. Decoding is a process in which lost cells gets recovered from remaining original and parity cells.
Erasure coding is mostly used for warm or cold data which undergo less frequent I/O access. The replication factor of Erasure coded file is always one. we cannot change it by -setrep command. Under erasure coding storage overhead is never more than 50%.
Under conventional Hadoop storage replication factor of 3 is default. It means 6 blocks will get replicated into 6*3 i.e. 18 blocks. This gives a storage overhead of 200%. As opposed to this in Erasure coding technique there are 6 data blocks and 3 parity blocks. This gives storage overhead of 50%.
The File System Namespace
HDFS supports hierarchical file organization. One can create, remove, move or rename a file. NameNode maintains file system Namespace. NameNode records the changes in the Namespace. It also stores the replication factor of the file.

Best Big Data Hadoop Training Cover In-Depth Concepts By Top-Rated Instructors
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
2. MapReduce
It is the data processing layer of Hadoop. It processes data in two phases.
They are:-
Map Phase- This phase applies business logic to the data. The input data gets converted into key-value pairs.
Reduce Phase– The Reduce phase takes as input the output of Map Phase. It applies aggregation based on the key of the key-value pairs.
You must check this MapReduce tutorial to start your learning.
Map-Reduce works in the following way:
- The client specifies the file for input to the Map function. It splits it into tuples
- Map function defines key and value from the input file. The output of the map function is this key-value pair.
- MapReduce framework sorts the key-value pair from map function.
- The framework merges the tuples having the same key together.
- The reducers get these merged key-value pairs as input.
- Reducer applies aggregate functions on key-value pair.
- The output from the reducer gets written to HDFS.
3. YARN
Short for Yet Another Resource Locator has the following components:-
Resource Manager
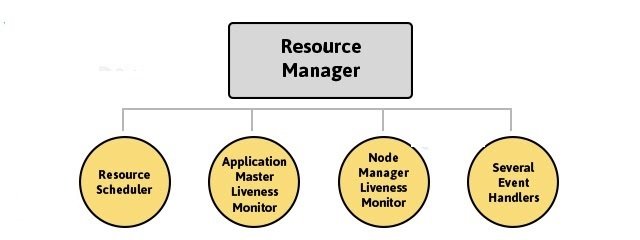
- Resource Manager runs on the master node.
- It knows where the location of slaves (Rack Awareness).
- It is aware about how much resources each slave have.
- Resource Scheduler is one of the important service run by the Resource Manager.
- Resource Scheduler decides how the resources get assigned to various tasks.
- Application Manager is one more service run by Resource Manager.
- Application Manager negotiates the first container for an application.
- Resource Manager keeps track of the heart beats from the Node Manager.
Big Data & Hadoop – Restaurant Analogy
Let us take an analogy of a restaurant to understand the problems associated with Big Data and how Hadoop solved that problem.
Bob is a businessman who has opened a small restaurant. Initially, in his restaurant, he used to receive two orders per hour and he had one chef with one food shelf in his restaurant which was sufficient enough to handle all the orders.
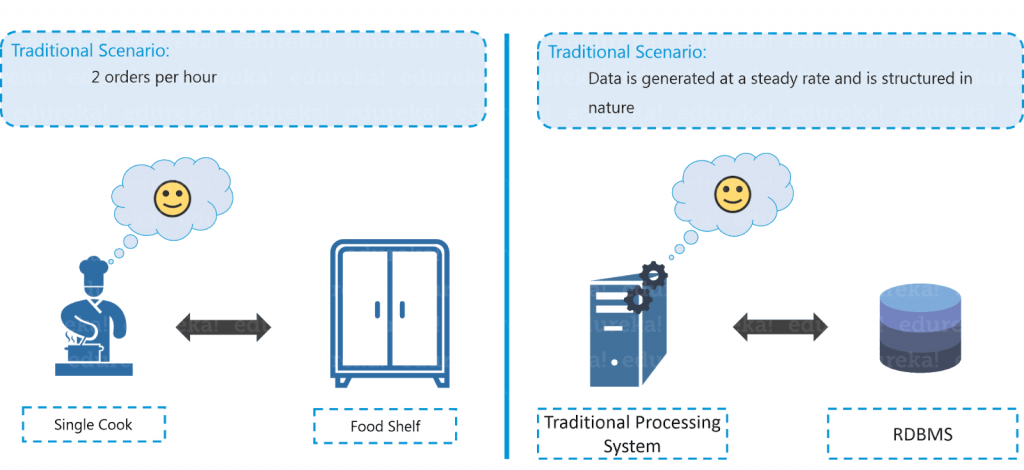
Now let us compare the restaurant example with the traditional scenario where data was getting generated at a steady rate and our traditional systems like RDBMS is capable enough to handle it, just like Bob’s chef. Here, you can relate the data storage with the restaurant’s food shelf and the traditional processing unit with the chef as shown in the figure above.
Big After a few months, Bob thought of expanding his business and therefore, he started taking online orders and added few more cuisines to the restaurant’s menu in order to engage a larger audience. Because of this transition, the rate at which they were receiving orders rose to an alarming figure of 10 orders per hour and it became quite difficult for a single cook to cope up with the current situation. Aware of the situation in processing the orders, Bob started thinking about the solution.

Similarly, in Big Data scenario, the data started getting generated at an alarming rate because of the introduction of various data growth drivers such as social media, smartphones etc.

Learn Big Data Hadoop Certification Course to Build Your Skills & Career
Weekday / Weekend BatchesSee Batch DetailsNow, the traditional system, just like the cook in Bob’s restaurant, was not efficient enough to handle this sudden change. Thus, there was a need for a different kind of solutions strategy to cope up with this problem.
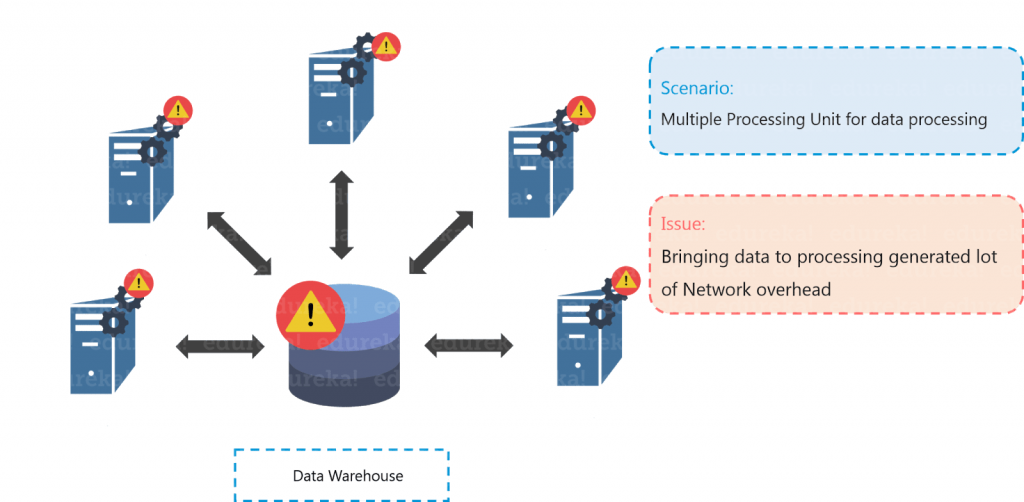
After a lot of research, Bob came up with a solution where he hired 4 more chefs to tackle the huge rate of orders being received. Everything was going quite well, but this solution led to one more problem. Since four chefs were sharing the same food shelf, the very food shelf was becoming the bottleneck of the whole process. Hence, the solution was not that efficient as Bob thought.
Similarly, to tackle the problem of processing huge data sets, multiple processing units were installed so as to process the data in parallel (just like Bob hired 4 chefs). But even in this case, bringing multiple processing units was not an effective solution because the centralized storage unit became the bottleneck.
In other words, the performance of the whole system is driven by the performance of the central storage unit. Therefore, the moment our central storage goes down, the whole system gets compromised. Hence, again there was a need to resolve this single point of failure.
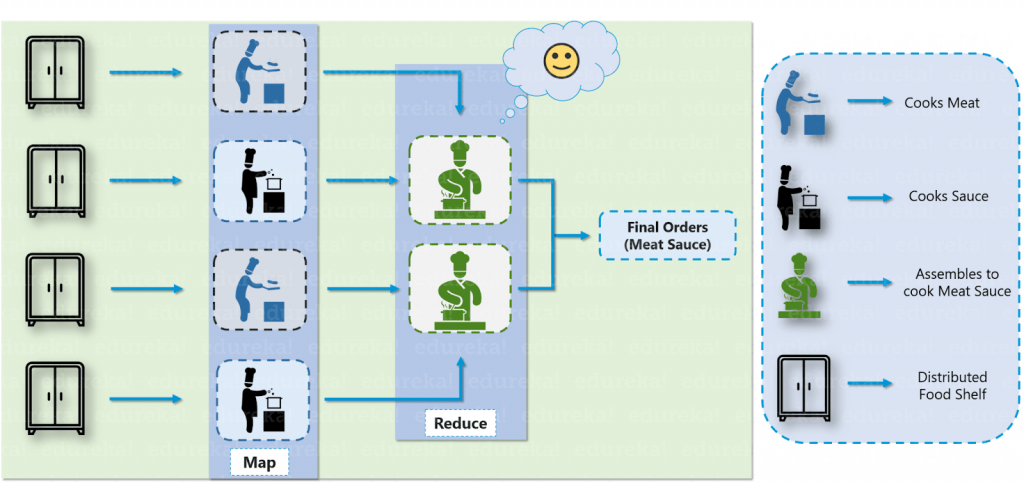
Bob came up with another efficient solution, he divided all the chefs into two hierarchies, that is a Junior and a Head chef and assigned each junior chef with a food shelf. Let us assume that the dish is Meat Sauce. Now, according to Bob’s plan, one junior chef will prepare meat and the other junior chef will prepare the sauce. Moving ahead they will transfer both meat and sauce to the head chef, where the head chef will prepare the meat sauce after combining both the ingredients, which then will be delivered as the final order.

Hadoop functions in a similar fashion as Bob’s restaurant. As the food shelf is distributed in Bob’s restaurant, similarly, in Hadoop, the data is stored in a distributed fashion with replications, to provide fault tolerance. For parallel processing, first the data is processed by the slaves where it is stored for some intermediate results and then those intermediate results are merged by master node to send the final result.




