
Last updated on 16th Dec 2021| 2556
A Hadoop cluster is a collection of computers, known as nodes, that are networked together to perform these kinds of parallel computations on big data sets. Hadoop clusters consist of a network of connected master and slave nodes that utilize high availability, low-cost commodity hardware.
- Introduction to hadoop cluster
- Hadoop Cluster architecture
- Characteristics of hadoop cluster
- What is cluster size in Hadoop?
- What are the challenges of a Hadoop Cluster?
- Hadoop Clusters Properties
- Types of Hadoop Cluster
- Components of a Hadoop Cluster
- Benefits of Hadoop Cluster
- Conclusion
Introduction to hadoop cluster:
Apache Hadoop is an open supply, Java-based, software package framework and similar processing engine. It allows giant processing tasks to be softened into smaller tasks which will be performed seamlessly with victimisation associated algorithmic rules (such as the MapReduce algorithm), and distribute them within the Hadoop assortment. Hadoop assortment may be a cluster of computers, referred to as nodes, that square measure connected along to perform these forms of compatible calculations on giant knowledge sets.
In contrast to different pc collections, Hadoop collections square measure specifically designed to store and analyse giant amounts of organised and unstructured knowledge in an exceedingly distributed pc surroundings. Another factor that separates the Hadoop scheme from different pc collections is their distinctive design and design. Hadoop’s collections embrace a network of connected slave nodes victimization high-availability, inexpensive hardware. Ability to queue and quickly add or calculate nodes pro re nata volume that creates them appropriate for big knowledge analytics operations with terribly versatile knowledge sets.
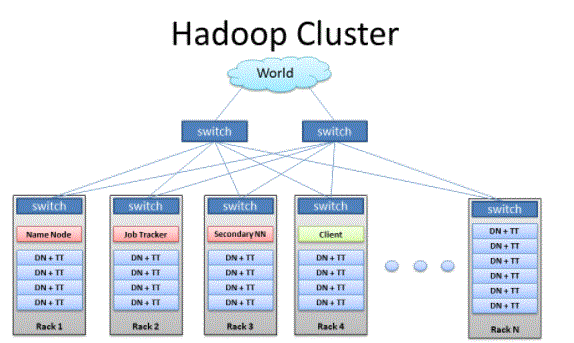
- Hadoop collections are made up of a network of key nodes and staff that organise and perform various tasks throughout Hadoop’s distributed file system. Key nodes typically use high quality hardware and include NameNode, Second NameNode, and JobTracker, each running on a separate machine.
- Employees integrate virtual machines, which use both DataNode and TaskTracker resources on asset hardware, and perform real-time storage and processing tasks as directed by key nodes.
- The last part of the Node Client system, which is responsible for uploading data and downloading results.
- Master nodes are responsible for storing data on HDFS and overseeing important tasks, such as using compatible statistics on data using MapReduce.
- Staff notes include most of the visual cues in the Hadoop collection, and perform the function of storing data and using statistics. Each employee node uses DataNode and TaskTracker services, which are used to receive instructions from master nodes.
- Client notes are responsible for uploading data to a collection. Client notes first post MapReduce tasks that explain how the data needs to be processed and then download the results once the processing is complete.
Hadoop Cluster architecture:
Characteristics of hadoop cluster:
Let’s quote the key options that make Hadoop a lot more reliable to use, the industry’s favourite, and also the most powerful huge information tool.
Open Source:
Hadoop is open supply, which implies it’s liberal to use. Because it is an associate degree open supply project, the ASCII text file is obtainable on-line for anyone to grasp or certify changes in step with their trade demand.
Extremely climbable Cluster:
Hadoop could be a terribly measurable model. an outsized quantity of information is categorised into many cheap machines in an exceedingly cluster processed. the quantity of those machines or nodes is accumulated or remittent in step with business wants. In ancient RDBMS (Related information Management System) systems can not be measured to access massive amounts of information.
Mistake Tolerance Available:
Hadoop uses hardware (inexpensive systems) which will crash at any time. Hadoop information is duplicated on numerous DataNodes within the Hadoop assortment that ensures information handiness in any manner any of your applications crashes. you’ll scan all {the information|the info|The information} on one machine if this machine faces technical drawback data is re-read to different nodes within the Hadoop assortment as a result of the information being derived or duplicated mechanically. By default, Hadoop makes three copies of every file block and stores it in separate nodes. This continual feature is adjustable and might be modified by dynamic repetition within the hdfs-site.xml file.
High handiness Provided:
Mistake tolerance provides High handiness within the Hadoop assortment. High handedness means that information handiness within the Hadoop assortment. because of error tolerance within the event of any DataNode drop a similar information is found in the other place wherever the information is duplicated. The Hadoop assortment is found at the highest and has two or a lot of Name Nodes particularly Active NameNode and Passive NameNode additionally referred to as stand by NameNode. within the event that Active NameNode fails then Passive node can take responsibility for Active Node and supply similar information as Active NameNode which might be simply utilised by the user.
Inexpensive:
Hadoop is associate degree open supply and uses low-priced hardware that gives an economical model, not like ancient Relationship info that needs high-priced hardware and advanced processors to handle huge amounts of information. The matter with ancient Relationship Websites is that high-volume information storage isn’t high-priced, therefore the company has begun to delete data. which can not reach the correct state of their business. It means that Hadoop provides the USA with two main edges at a price: one is open supply, which means that it is used for complementary and also the difference is that it uses affordable hardware.
Hadoop Provides Flexibility:
Hadoop is intended in such the simplest way that it will handle any kind of info like structured (MySql Data), Semi-Structured (XML, JSON), Un-structured (Images and Videos) alright. This suggests that it will simply method any kind of freelance information of its structure creating it extremely versatile. It’s terribly helpful for businesses because it will simply method massive information sets, thus businesses will use Hadoop to research vital information from sources like communications, email, etc. With this flexibility, Hadoop is used for the log processes, Data. plus storage, fraud detection, etc.
simple to Use:
Hadoop is straightforward to use as developers don’t need to worry concerning any process work because it is in hand by Hadoop itself. The Hadoop system is additionally terribly massive and comes with several tools like Live, Pig, Spark, HBase, Mahout, etc.

Learn Advanced Hadoop Administration Certification Training Course to Build Your Skills
Weekday / Weekend BatchesSee Batch DetailsHadoop uses an information Centre:
The Dataspace thought is employed to hurry up the Hadoop process. in an exceeding information centre thought, the machine mind is stirred nearer to the information instead of moving the information to the machine thought. The price of moving information to HDFS is extremely high-priced and with the assistance of the information centre, the information measure used within the system is reduced.
Provides quick information Processing:
Hadoop uses a distributed filing system to manage its storage i.e. HDFS (Hadoop Distributed File System). In DFS (Distributed File System) large-sized file is broken into smaller file blocks and distributed between Nodes found within the Hadoop assortment, as this massive range of file blocks square measure processed in an exceedingly similar manner that creates Hadoop quicker, so providing higher performance compared to traditional management Systems.
What is cluster size in Hadoop?
Hadoop collection size is a set of metrics that defines storage capacity and calculation to start Hadoop tasks, namely:
Number of nodes: number of Master nodes, number of Edge Nodes, number of Tasks.
Node configuration for each type: number of cores per node, RAM and Disk Volume.
What are the challenges of a Hadoop Cluster?
Problem with very little} files – Hadoop struggles with large volumes of little files – smaller than the default Hadoop block size of 128MB or 256MB. They were designed to support large amounts of information. Instead, Hadoop works best once there square measure atiny low vary of monumental files. Finally once you increase the degree of very little files, it overloads Namenode as a result of it saves the program name.
ore advanced methods – reading and writing activities in Hadoop are also very expensive quickly, notably once method large amounts of information. All of this comes right all the way down to Hadoop’s inability to methodology memory and instead data is browsed and written from and to disk.
Only execution is supported – Hadoop is supposed for small volumes of monumental files by clusters. This goes back to the approach data is collected and keeps that need to all be done before it should be processed. What this means is ultimately that streaming data is not supported and cannot perform processing with low latency.
Recurring method – Hadoop contains a data flow structure set in ordered phases that makes it impossible to perform a continual method or use cc.
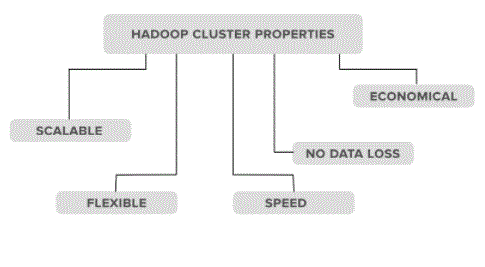
Hadoop Clusters Properties:
Scalability: Hadoop clusters are terribly capable of up-and-down and scale back the amount of nodes i.e. servers or hardware. Let’s take a glance at an associate degree example of what this property means. Suppose a corporation needs to investigate or take care of concerning 5PB knowledge|of knowledge|of information} for successive a pair of months therefore he used ten nodes (servers) in his Hadoop assortment to store all this data. However, currently what happens, within the middle of this month the organisation got additional 2PB information. If so, the organisation ought to establish or upgrade the amount of servers in its Hadoop assortment system from ten to twelve (let’s consider) to stay it. The method of skyrocketing or decreasing the amount of servers within the Hadoop assortment is named quantifiability.
Flexibility: this is often one among the foremost necessary options that the Hadoop assortment has. per this design, the Hadoop assortment is extremely versatile which implies it will handle any sort of information despite its sort and structure. With the assistance of this platform, Hadoop will method any sort of information from on-line websites.
Speed: Hadoop clusters work best to run at high speeds as a result of {the information|the info|the information} remains distributed at intervals the cluster and since of its ability to map data i.e. MapReduce design that works on Master-Slave phenomena.
No information Loss: there’s no likelihood knowledge|of knowledge information} loss in any node within the Hadoop assortment as a result of Hadoop collections having the flexibility to duplicate data elsewhere. Thus within the event of failure of any node no information is lost because it tracks the backup of that information.
Economics: Hadoop clusters are terribly economical as they carry the last methodology distributed in their clusters i.e. the information remains distributed by cluster across all nodes. Therefore, within the case of increasing storage we tend to solely have to add some more cost-effective hardware storage.
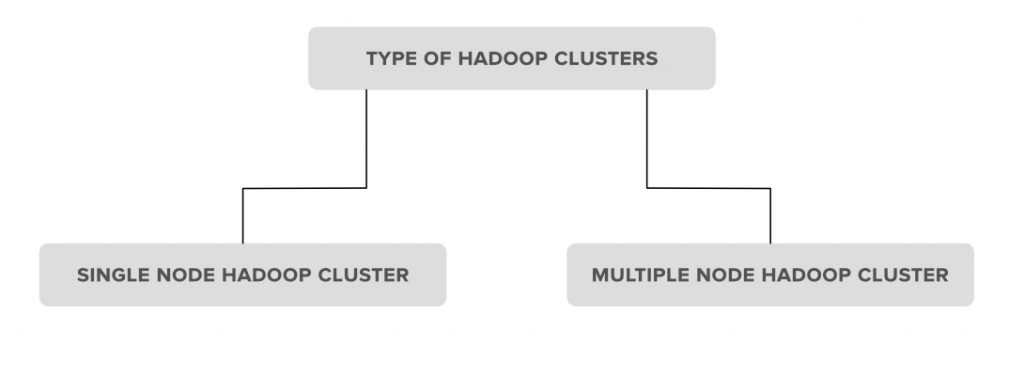
Types of Hadoop Cluster:
1. Single Node Hadoop Cluster: In Single Node Hadoop Cluster because the name suggests that the gathering is simply one place which implies all of our Hadoop Daemons specifically Name Node, Data Node, Second Name Node, Service Manager, Node Manager can operate identical system or on identical machine. It additionally means all of our processes are going to be managed by only 1 JVM (Java Virtual Machine) method Instance.
2. Multiple Node Hadoop Cluster: In multiple Hadoop enode collections because the name suggests it contains multiple nodes. During this kind of set all our Hadoop Daemons, which are able to be restricted to completely different nodes to line identical assortment. Generally, in fixing a Hadoop set of multiple nodes we have a tendency to try and use our prime Master node process nouns specifically Name node and Resource Manager and use the cheaper Daemon’s program i.e. Node Manager and information Node.
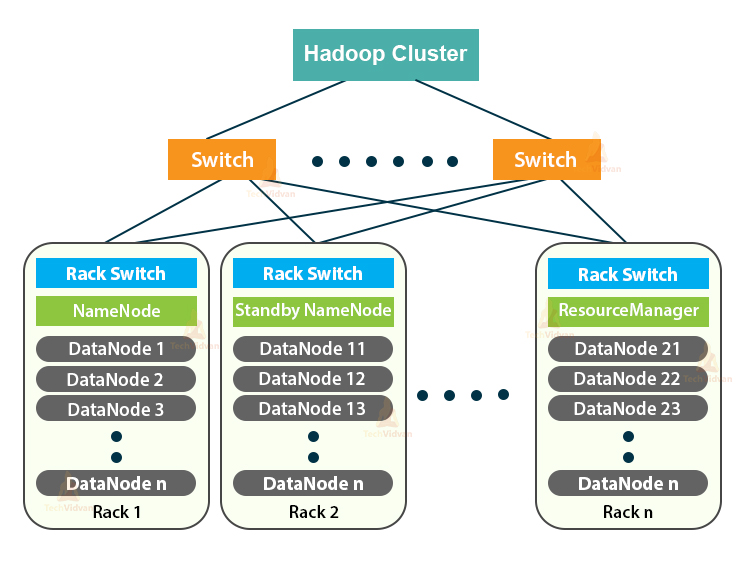
Components of a Hadoop Cluster:
Master Node – The Master Node within the hadoop assortment is to blame for storing information in HDFS and activating a uniform calculation of hold on information victimisation MapReduce. Master Node has three nodes – NameNode, Second NameNode and JobTracker. JobTracker monitors similar processing victimisation MapReduce whereas NameNode handles information storage operations via HDFS. NameNode keeps track of all info in files (i.e. information in files) like file time interval, that user accesses the file at the present time and that file is held on within the hadoop assortment. The second NameNode maintains a backup of NameNode information.
Slave / Work Node- This half within the hadoop assortment is to blame for storing information and activity calculations. each slave / worker node uses each the TaskTracker and therefore the DataNode service to attach to the Master node within the assortment. DataNode service is second to NameNode and TaskTracker service is second to JobTracker.
Client Nodes – consumer node has hadoop put in with all the required configuration settings and is to blame for uploading all information to the hadoop assortment. consumer location delivers mapreduce operations that specify however information has to be processed and output is detected by consumer location once process function is complete.
- As huge information grows quicker, an equivalent process power of the Hadoop cluster helps to extend the speed of the analysis method. However, the process capability of a hadoop cluster might not be enough for the growing volume of knowledge. In such cases, hadoop assortments will simply start up to stay up with the analysis speed by adding further collection nodes while not creating changes to the applying construct.
- Hadoop assortment setup isn’t as overpriced as interference low-cost hardware. Any organisation will start a robust hadoop assortment while not outlay on overpriced server hardware.
- Hadoop clusters square measure proof against failures which implies that whenever information is shipped to a particular location for analysis, it’s perennial on alternative nodes within the hadoop cluster. If the node fails then a replica copy of the information settled elsewhere within the assortment is used for analysis.
Benefits of Hadoop Cluster:
- So, we’ve seen it all about the Hadoop Cluster in detail. Moreover, in this Hadoop Cluster study, we discussed Architecture of Cluster in
- Hadoop, Its Components and Hadoop Nodes Configuration Detailed. Also, we discussed the Hadoop Cluster Diagram to better understand Hadoop.
- Working with Hadoop collections is very important for all those working with or associated with the Big Data industry. For more information on how Hadoop collections work, contact us! We have a wide range of Big Data online courses that can help you make your dream of becoming a Big Data scientist a reality.
Conclusion:




