
Last updated on 20th Dec 2021| 2558
Pig is a high level scripting language that is used with Apache Hadoop. Pig enables data workers to write complex data transformations without knowing Java. Pig’s simple SQL-like scripting language is called Pig Latin, and appeals to developers already familiar with scripting languages and SQL.
- Introduction to Apache pig
- Need of Pig
- Features of Apache Pig
- Apache Pig Installation
- Apache Pig Run Modes
- Ways to execute Pig Program
- Why Do We Need Apache Pig?
- Apache pig architecture
- Benefits of Apache pig
- Conclusion
Introduction to Apache pig:
Apache Pig could be a platform for analyzing massive knowledge sets that contain high-quality language rendering of information analytics programs, alongside the testing infrastructure for these systems. A vital feature of Pig systems is that their configurations square measure extremely compatible, permitting them to be ready to handle terribly massive knowledge sets. Currently, the Pig infrastructure layer consists of a moderator that produces a sequence of Map-Reduce programs, during which massive parallel implementations exist already (e.g., Hadoop subprojects). The pig language layer presently contains a text language known as Pig Latin, that has the subsequent key features:
Easy to edit. it’s impossible that he would do the same for straightforward “analytical” knowledge analysis tasks. subtle tasks that comprehend loads of connected conversion square measure clearly documented as knowledge flow sequences, that makes it easier to document, understand, and store
Opportunities for development. The approach the code is written permits the system to mechanically improve its performance, permitting the user to specialize in linguistics rather than operating expeditiously.
Extension. Users will produce their own tasks to perform the special-purpose process.

Need of Pig:
One limitation of MapReduce is that the event cycle is incredibly long. Writing a slider and a map, combining code packaging, posting work and retrieving output could be a long task. Apache Pig reduces development time employing a multi-quiz approach. Also, Pig is helpful for programmers UN agencies don’t seem like Java. two hundred lines of Java code is written in only ten lines exploiting the Latin Pig language. SQL practitioners want a lot of effort to find out Pig Latin.
Emergence of Pigs: Earlier in 2006, the Apache Pig was developed by Yahoo researchers. At the time, the best plan of developing Pig was to use MapReduce functions on terribly giant databases. In 2007, it was affected by the Apache software system Foundation (ASF) creating its Associate in Nursing open supply project. The primary version (0.1) of pork arrived in 2008. The most recent version of Apache Pig is zero.18 that came in 2017.
- To perform several functions Apache Pig provides rich operator sets such as filters, joins, filters, etc.
- Easy to read, read and write. Especially for the SQL-programmer, Apache Pig is a blessing.
- Apache Pig is flexible so you can perform your own user-defined tasks and processes.
- Joining is easy on the Apache Pig.
- A few lines of code.
- The Apache Pig allows splitting between pipes.
- The data structure is high value, nested, and rich.
- Pig can handle your analysis for both formal and informal data.
- To view large data sets using Pig Scripting.
- Provides support for all large data sets of Ad-hoc queries.
- In prototyping of large algorithms for processing data sets.
- It is necessary to process the upload of sensitive data in a timely manner.
- Collection of large amounts of databases in the form of web search and clarity logs.
- Used when analysis data is required using samples.
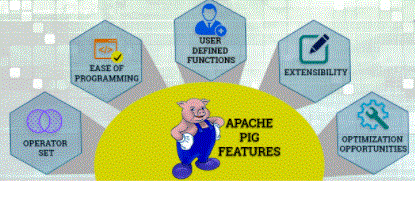
Features of Apache Pig:
Apache Pig Applications:
Apache Pig comes with the following features –
Rich user set – Provides multiple operators to perform tasks such as joining, editing, file uploading, etc.
Easy to edit – Pig Latin is similar to SQL and it is easy to write Pig text if you are SQL.
Upgrade opportunities – Tasks in Apache Pig improve their performance automatically, so programmers need to focus only on language semantics.
Extensions – Using existing operators, users can create their own reading, processing, and writing operations.
UDF’s – Pig provides a place to create User-defined Tasks in other programming languages such as Java and to request or embed them in Pig Scripts.
Manages all types of data – Apache Pig analyzes all types of data, both formal and informal. Saving results to HDFS.
- Steps to install Apache Pig
- Download the Apache Pig tar file.
- Open the downloaded tar file.
- $ tar -xvf pig-0.16.0.tar.gz
- Open the bashrc file.
- $ sudo nano ~ / .bashrc
- Now, provide the following PIG_HOME version.
- export PIG_HOME = / home / hduser / pig-0.16.0
- Export Route = $ Route: $ PIG_HOME / bin
- Let’s examine the inclusion in the command type
- $ pig -h
- Let’s start a pig in MapReduce mode.
- $ pig
Apache Pig Installation:
At this stage, we will do a pig implant.
Prerequisite
Java Installation – Check that Java is installed or does not use the following command.
$ java -version
Hadoop Installation – Check that Hadoop is installed or does not use the following command.
$ Hadoop version
If one of them is not included in your system, follow the link below to install it. Click Here to install.
- Apache Pig Run Modes
- Local mode
- It works with one JVM and is employed to take a look at development and prototyping.
- Here, files are put in and running exploitation localhost.
- Local mode works in a very native filing system. The input and output information area unit holds on within the native filing system.
- $ native pig-x
- MapDownload Mode
- MapReduce Mode is additionally called Hadoop Mode.
- It is the default mode.
- In this Pig interprets Pig Latin into MapDimit tasks and performs them in clusters.
- It is often done against part distributed or totally distributed Hadoop installations.
- Here, the input and output information is on the market in HDFS.
- $ pig
- Or,
- $ pig -and mapreduce
Apache Pig Run Modes:
Apache Pig signs in 2 ways: space Mode and Map scale back Mode.
Local mode shell command:
Map minimisation command command:

Ways to execute Pig Program:
The following are some ways in which you can create a Pig program in local mode and Mapreduce: –
Interaction Mode – In this mode, Pig is used in Grunt shell. To request a Grunt shell, use the pig command. Once Grunt mode is in use, we can issue Pig Latin statements and order in conjunction with the command line.
Collection mode – In this mode, we can use a text file with the .pig extension. These files contain Pig Latin commands.
Embedded Mode – In this mode, we can define our functions. These activities can be called UDF (User Defined Functions). Here, we use programming languages such as Java and Python.
- Java programmers who don’t work well in Java typically want to put their all into Hadoop, particularly once doing any MapReduce tasks. Apache Pig may be a blessing to any or all such program planners.
- Using Pig Latin, editors will perform MapReduce tasks simply while not writing complicated codes into Java.
- The Apache Pig uses a multi-query methodology, therefore reducing the code length. As an example, an operation that will need you to type two hundred lines of code (LoC) in Java may be simply done by writing as low as ten LoC in Apache Pig. The Apache Pig finally reduced its development time by sixteen times.
- Pig Latin may be a SQL-like language and it’s simple to be told Apache Pig if you’re at home with SQL.
- Apache Pig provides several intrinsic operators to support knowledge functions like connection, filters, ordering, etc. additionally, it conjointly provides nested knowledge sorts like tuples, bags, and non-MapReduce maps.
Why Do We Need Apache Pig?
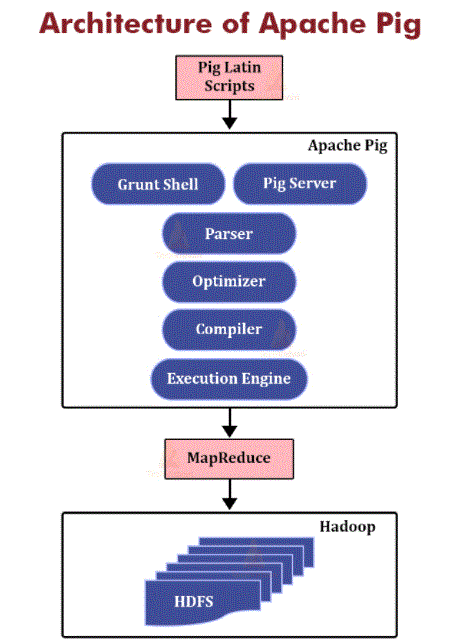
Apache pig architecture:
The language used to analyze data on Hadoop using Pig is known as Pig Latin. It is a high-quality data processing language that provides a rich set of data types and operators to perform various data functions.
To perform a specific task Program editors using Pig, program editors need to write Pig text using the Latin Pig language, and do it using any formats (Grunt Shell, UDFs, Embedded). After execution, these scripts will go through a series of changes used by the Pig Framework, to produce the output you want.
Inside, Apache Pig converts these texts into a series of MapReduce tasks, and thus, simplifies the work of the designer. The structure of the Apache Pig is shown below.
Analyst– Initially, the Pig inscriptions are handled by the Compiler. Checks syntax for text, checks genre, and other mixed tests. Analyst output will be DAG (targeted acyclic graph), representing Pig Latin statements and sensible operators. In DAG, sensible text operators are represented as nodes and data flows are expressed as edges.
Optimizer– The logical system (DAG) is transmitted to a logical developer, which carries out logical preparation such as guessing and pushing.
Compiler– The moderator integrates a sound logical program into a series of MapReduce tasks.
Production engine– Finally MapReduce tasks are submitted to Hadoop in a sequential order. Finally, these MapReduce functions used in Hadoop produce desirable results.
Latin Pork Data Model– The Pig Latin data model is fully integrated and allows for complex non-atomic data types such as map and tuple. Given below is a graphic representation of the Pig Latin data model.
Data Model– Any value in Pig Latin, regardless of their data, is a type known as the Atom. It is stored as a cord and can be used as a cord and a number. int, long, floating, double, chararray, and bytearray Pig atomic values. A piece of data or a simple atomic number is known as a field. Example – ‘raja’ or ‘30’
Tuple– The record formed by the set order of the fields is known as the tuple, the fields can be of any type. The tuple is similar to the RDBMS table line. Example – (Raja, 30)
Bag– The bag is a random set of tuples. In other words, a collection of tuples (which is no different) is known as a bag. Each tuple can have a number of fields (flexible schema). The bag is represented by ‘{}’. It is similar to the table in RDBMS, but unlike the table in RDBMS, it is not necessary for each tuple to have the same number of fields or for fields in the same location (column) to have the same type. Example – {(Raja, 30), (Mohammad, 45)}
Map– A map (or data map) is a set of key value pairs. The key needs to be of char array type and must be different. The value can be of any kind. Represented by ‘[[]’ Example – [name # Raja, age # 30]
Relationships– A relative is a bag of tuples. Relationships in Pig Latin are random (there is no guarantee that tuples are processed in any particular order).
Benefits of Apache pig:
i. Minimum development time- It consumes less time while it is being developed. Therefore, we can say that it is one of the great advantages. Especially considering vanilla MapReduces the complexity of tasks, time spent, and maintenance of systems.
ii. Easy to read- Well, the Apache Pig learning curve has no slope. That means anyone who can write vanilla MapReduce or SQL for that matter can pick up and write MapReduce works.
iii. Process language- Apache Pig is a process language, not a declaration, unlike SQL. Thus, we can easily follow the instructions. Also, it provides the best exposure to data conversion at all stages.
iv. Data flow- It is the language of data flow. That means that here everything is about the data even though we sacrifice control structures such as loop or if the structures. “With this data and because of data”, data conversion is a first-class citizen. Also, we cannot create loops without data. We need to constantly change and manipulate data.
v. It is easy to control the execution- We can control the action of every step because it is a natural process. And, the advantage is that, right. That means we can write our own UDF (User Defined Function) and inject into a specific section of the pipeline.
vi. UDF- It is possible to write our UDF.
vii. Lazy test- As its name implies, it is not tested unless you generate an outgoing file or extract any message. It is the benefit of a logical plan. That it can make the program start and end and the optimizer can produce an effective startup program.
viii. Use of Hadoop features– With Pig, we can enjoy everything Hadoop offers. Similar to compliance, error tolerance has many aspects of related websites.
ix. Works on non-built– Pig works well on large informal and confusing databases. Basically, Pig is one of the best tools for organizing large informal data.
x. Basic pipe– Here, we have the UDFs we want to match and use for large amounts of data. That means we can use Pig as a basic pipe where it does the hard work. In that sense, we are using our UDF in the process we want.
Conclusion:
So we have finally seen what the Apache Pig is, The History of the Pig, Why the Pig is Needed and the key features of the Apache Pig that make it different from other similar technologies.
Pig in big data is useful for application developers as it provides the platform with a simple visual interface, reduces code complexity, and encourages them to achieve results more effectively. Twitter, LinkedIn, eBay, and Yahoo are part of organizations that use Pig to handle their vast amount of data.




