
Last updated on 04th Jul 2020| 1914
Data Science with Python is a dynamic and expansive field that harnesses the capabilities of the Python programming language and a suite of powerful libraries to extract insights from complex datasets. In this discipline, Python serves as a versatile tool, facilitating tasks such as data cleaning and preprocessing through libraries like Pandas and NumPy. These libraries enable efficient handling of missing data, outliers, and the transformation of raw data into a format suitable for analysis. Moreover, Python excels in data exploration and visualization, thanks to libraries like Matplotlib and Seaborn.
1. Describe the distinction between Python’s deep copy and shallow copy.
Ans:
Shallow copy exchanges references to items within but generates a new object. The object’s top-level structure is essentially duplicated, while the inside objects continue to refer to the original objects.
A deep copy, on the other hand, starts with a new object and copies every item inside it recursively. It produces a whole separate object with a unique collection of nested components.
2. What is a generator in Python, and how does it differ from a regular function?
Ans:
- Python iterators that are defined using functions that contain the ‘yield’ keyword are known as generators.
- Generators, in contrast to ordinary functions, provide lazy evaluation, which means they only generate values one at a time as necessary.
3. How can you handle exceptions in Python? Provide examples.
Ans:
The ‘try’ and ‘except’ blocks in Python are used to handle exceptions. The code that might throw an exception is included in the ‘try’ block, and the code to gracefully manage the error is contained in the ‘except’ block. As an illustration:
- try:
- # code with the capability to raise an exception
- except SomeException as e:
- # code to handle the exception
4. What does Python’s Global Interpreter Lock mean?
Ans:
In Python, the Global Interpreter Lock is a technique that ensures that only one thread runs Python bytecode at a time. This is particularly concerning in the context of multithreading since it has the potential to degrade the performance of CPU-bound processes. The GIL prohibits several threads from running Python code concurrently, reducing CPU-bound programmes’ ability to fully use multiple cores.
5. Describe the function of Python classes’ ‘__init__’ method.
Ans:
When an object is formed from a class in Python, a particular method called “__init__” is called. Initialising the object’s characteristics is its main objective. For instance:
- class MyClass:
- def __init__(self, attribute):
- self.attribute = attribute
6. How does Python’s garbage collection work?
Ans:
Memory management in Python is handled by the garbage collector, which automatically recovers objects and memory that aren’t being utilised. It makes use of both a cyclic garbage collector and reference counting. An object is erased when the number of references to it is zero, which is tracked using reference counting. Circular references that may escape detection by reference counting are found and gathered by the cyclic garbage collector.
7. What is a lambda function in Python, and when would you use one?
Ans:
- In Python, a lambda function is a short-lived, anonymous function declared using the ‘lambda’ keyword.
- It is frequently employed for quick, one-time tasks when a complete function description would appear overly complicated.
- Lambda functions are particularly useful in functional programming constructs like ‘map()’, ‘filter()’, and ‘reduce()’.
8. What is the purpose of the ‘__str__’ and ‘__repr__’ methods in Python classes?
Ans:
The ‘__str__’ method is responsible for returning a human-readable string representation of an object. It is invoked by the built-in ‘str()’ function.
The ‘__repr__’ method returns an unambiguous string representation of the object and is invoked by the built-in ‘repr()’ function. It is often used for debugging and development.
9. What is the objective of the Python ‘zip()’ function?
Ans:
To create an iterator of tuples from two or more iterables, use Python’s ‘zip()’ method. The items from the input iterables are contained in each tuple at the same place. This is very helpful when iterating through several sequences in simultaneously. As an example:
- list1 = [1, 2, 3]
- list2 = [‘a’, ‘b’, ‘c’]
- zipped = zip(list1, list2)
- # Result: [(1, ‘a’), (2, ‘b’), (3, ‘c’)]
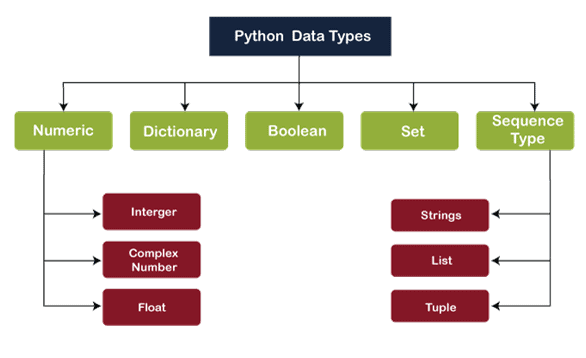
10. Which data types are pre-built in Python?
Ans:
- Numeric Types
- Sequence Types
- Set Types
- Mapping Type
- Boolean Type
- None Type
11. How can I search a dataset for duplicate values?
Ans:
Python and related libraries, such as Pandas, may be used to find duplicate values in a dataset. For example, you may use Pandas’ ‘duplicated()’ method to find duplicate rows if you have a DataFrame.
- import pandas as pd
- # Assuming df is your DataFrame
- duplicate_rows = df[df.duplicated()]
12. What distinguishes ‘xrange’, and ‘range from one another?
Ans:
‘range()’: Returns a list containing an arithmetic sequence of numbers.
‘xrange()’: Returns an xrange object, which is an iterable representing an arithmetic sequence. It is more memory-efficient than range() because it generates numbers on-the-fly.
13. Describe the distinction between Pandas’s loc() and iloc() functions.
Ans:
| Attribute | Purpose | Example | |
| ‘loc()’ |
Label-based indexing |
‘df.loc[2, ‘Column_A’]’ | |
| ‘iloc()’ | Integer-location based indexing | ‘df.iloc[1, 0]’ |
14. Which deep learning frameworks exist?
Ans:
- TensorFlow
- PyTorch
- Keras
- Theano
- Caffe
- MXNet
15. What does Python’s list comprehension mean?
Ans:
In Python, list comprehension offers a condensed method for creating lists. Compared to conventional loops, it offers a more concise and clear syntax for creating lists. The fundamental syntax is:
16. What components make up a Matplotlib plot?
Ans:
A Matplotlib plot typically consists of the following components:
Figure: The top-level container for all the plot elements.
Axes: The subplot or the area where the data is plotted.
Axis: The X and Y axis with ticks, tick labels, and axis labels.
Plot: The graphical representation of data in the form of lines, markers, etc.
Legend: Describes the elements of the plot.
Title: The title of the plot.
17. How do you handle missing or NaN values in a Pandas DataFrame?
Ans:
Pandas provides methods like ‘dropna()’ to remove rows with missing values, and ‘fillna()’ to fill or impute missing values with specified values or methods.
- import pandas as pd
- # Drop rows with NaN values
- df.dropna(inplace=True)
- # Fill NaN values with a specific value, e.g., mean
- df.fillna(df.mean(), inplace=True)
18. What is the purpose of the ‘virtualenv’ tool in Python development?
Ans:
To construct isolated Python environments, use the programme “virtualenv.” Installing packages and dependencies for a particular project is possible without compromising the Python environment globally. This is essential for maintaining dependencies and preventing disputes between various projects.
19. How does the Python ‘asyncio’ library work, and what is its use case?
Ans:
‘asyncio’ is a library for asynchronous programming in Python. It uses coroutines (asynchronous functions) and an event loop to manage non-blocking I/O operations.
It is particularly useful for concurrent execution of tasks, like handling multiple network connections or parallelizing I/O-bound operations.
20. What is the purpose of the ‘with’ statement in Python? Provide an example.
Ans:
The ‘with’ statement is used to simplify resource management, such as file handling. It ensures that certain operations are performed before and after a block of code, and resources are properly released.
- with open(‘example.txt’, ‘r’) as file:
- content = file.read()
21. Explain the concept of a Python decorator.
Ans:
A decorator is a function that extends or changes the behaviour of another function by passing it as an argument. The syntax for applying it is ‘@decorator’. Decorators are frequently used to do tasks without changing the underlying function, such as timing, logging, and code validation.
22. What is the role of the ‘__name__ ‘variable in Python?
Ans:
- In Python, a specific variable is called “__name__.” When a Python script runs, ‘__main__’ is assigned to ‘__name__’.
- It only permits certain blocks to be executed by the script when it is the primary programme and not when it is being imported as a module.
23. How does the ‘pickle’ module in Python work, and what is it used for?
Ans:
Python’s ‘pickle’ module is used to serialise and deserialise Python objects. It turns Python objects into a byte stream, allowing them to be easily saved to a file or sent over a network. It is frequently employed for data persistence and inter-process communication.
24. What is the purpose of Python’s’map()’ function?
Ans:
The method’map()’ applies a provided function to all elements in an iterable and returns an iterator that produces the results. It’s a quick technique to modify or process all items of a list or other iterable at once.
- numbers = [1, 2, 3, 4, 5]
- squared = map(lambda x: x**2, numbers)
- # Result: [1, 4, 9, 16, 25]
25. Explain the concept of inheritance in Python, and provide an example.
Ans:
In object-oriented programming (OOP), inheritance is a basic notion. It permits one class (subclass/derived class) to inherit characteristics and methods from another (superclass/base class).
- class Animal:
- def speak(self):
- print(“Animal speaks”)
- class Dog(Animal):
- def bark(self):
- print(“Dog barks”)
- my_dog = Dog()
- my_dog.speak() # Inherits ‘speak’ method from Animal
- my_dog.bark() # Has its own ‘bark’ method
26. Explain the purpose of NumPy and its main features.
Ans:
NumPy is a robust Python numerical computation package. The multi-dimensional array called ndarray, which enables effective operations on big datasets, is its main feature. NumPy offers methods for performing mathematical operations on these arrays, making it possible to efficiently complete tasks like statistical analysis, linear algebra, and mathematical computations.
27. What is the role of Pandas in Data Science, and how is it different from NumPy?
Ans:
- Building on the features of NumPy, Pandas is a library for data analysis and manipulation.
- It introduces two key data structures: Series, a one-dimensional labeled array, and DataFrame, a two-dimensional table with labeled axes.
28. Why does Pandas include the ‘apply()’ function?
Ans:
When applying a function down the axis of a DataFrame or Series, Pandas’ ‘apply()’ function is an effective tool. It permits each element, column, and row of the data structure to have either custom or preset functions applied to it. This feature allows for flexibility and customisation in data transformation procedures, which is very helpful when executing intricate operations on data.
29. Describe the Python list comprehension concept.
Ans:
- In Python, list comprehensions are a succinct and accessible method of creating lists.
- A ‘for’ clause, an optional ‘if’ clause, and an expression follow each other.
- List comprehensions provide you a concise syntax for making lists by giving each item in an iterable an expression.
30. What does Pandas’ ‘groupby()’ function accomplish?
Ans:
The ‘groupby()’ function in Pandas is used for grouping data based on some criteria. It facilitates the split-apply-combine strategy, where data is first split into groups based on specific criteria, then a function is applied to each group independently, and finally, the results are combined into a new data structure.

Get On-Demand Data Science with Python Training & Certification Course
Weekday / Weekend BatchesSee Batch Details31. How do you handle missing values in a Pandas DataFrame using Python?
Ans:
Handling missing values in a Pandas DataFrame is crucial for data preprocessing. Common methods include using ‘dropna()’ to remove rows or columns with missing values, and ‘fillna()’ to fill or impute missing values with specific values or calculated values (e.g., mean, median).
32. Explain the role of the ‘seaborn’ library in Python Data Science.
Ans:
Based on Matplotlib, Seaborn is a library for statistical data visualisation. It gives you a high-level interface to create visually beautiful and educational statistics visuals. With its pre-built themes and colour schemes, Seaborn makes the process of creating intricate visualisations easier.
33. How does Regex work?
Ans:
Regular Expressions, or Regex, is a potent tool for matching patterns in texts. It enables you to design patterns that can be used to text manipulation, matching, and searching. Regular expressions are supported by Python’s’re’ module. Characters that create search patterns, such as quantifiers, character classes, and wildcards, make up regex patterns.
34. Explain the concept of broadcasting in NumPy.
Ans:
- Broadcasting is a NumPy feature that allows operations on arrays of different shapes and sizes.
- The smaller array is broadcasted across the larger array to perform element-wise operations, making it convenient to work with arrays of different dimensions.
35. What is the purpose of the ‘crosstab()’ function in Pandas?
Ans:
The ‘crosstab()’ function in Pandas is used for creating contingency tables, which showcase the distribution of variables across different categories. It’s particularly useful for analyzing relationships between categorical variables and gaining insights into patterns and dependencies within the data.
36. Explain the differences between a DataFrame and a Series in Pandas.
Ans:
A Series is a one-dimensional labeled array, representing a single column or row in a DataFrame. While a DataFrame can be seen as a collection of Series, the key distinction lies in their dimensions and the operations they support.
37. What is a correlation matrix, and how is it useful in data analysis?
Ans:
The correlation coefficients between several variables in a dataset are displayed in a table called a correlation matrix. Data scientists may better understand how changes in one variable may impact others by using it to establish links and dependencies between variables. High correlation values point to a robust linear relationship.
38. Explain the concept of Natural Language Processing (NLP).
Ans:
- Natural Language Processing (NLP) is a field of artificial intelligence that focuses on enabling computers to understand, interpret, and generate human language.
- NLP encompasses a range of tasks, including text classification, sentiment analysis, and named entity recognition.
39. Discuss the concept of feature selection in machine learning.
Ans:
Feature selection involves choosing a subset of relevant features from the original set to improve model performance. It is crucial for enhancing model interpretability, reducing overfitting, and speeding up training. Techniques like Recursive Feature Elimination (RFE) and feature importance from tree-based models aid in selecting the most informative features.
40. What is the significance of the Expectation-Maximization (EM) algorithm?
Ans:
- The Expectation-Maximization (EM) algorithm is a powerful tool in unsupervised learning, especially in scenarios involving missing or incomplete data.
- EM is an iterative optimization algorithm that estimates the parameters of probabilistic models with latent variables.
41. Can you explain the concept of word embeddings in Natural Language Processing (NLP).
Ans:
Word embeddings are vector representations of words in a continuous vector space, designed to capture semantic relationships between words. In Natural Language Processing (NLP), word embeddings play a crucial role in converting textual data into a numerical format suitable for machine learning models.
42. What is the role of the K-means clustering algorithm in unsupervised learning?
Ans:
- K-means clustering is a widely used algorithm in unsupervised learning for grouping similar data points into clusters.
- The algorithm starts by randomly selecting k centroids, where k is the number of desired clusters.
43. Explain the concept of dropout in neural networks.
Ans:
Dropout is a regularization technique used in neural networks to prevent overfitting. During training, random neurons are “dropped out” or temporarily ignored, meaning they don’t contribute to the forward or backward pass. This forces the network to learn more robust features and prevents it from relying too heavily on specific neurons.
44. What is the purpose of the F1 score in evaluating classification models?
Ans:
- The F1 score is a metric that combines precision and recall, providing a balanced assessment of a classification model’s performance.
- The F1 score is calculated as the harmonic mean of precision and recall, ensuring that both false positives and false negatives are considered.
45. Discuss the concept of LDA (Linear Discriminant Analysis).
Ans:
Linear Discriminant Analysis (LDA) is a technique used for both dimensionality reduction and classification. In dimensionality reduction, LDA aims to find a subspace where the data points of different classes are well-separated, maximizing the inter-class variance while minimizing the intra-class variance.
46. What is the difference between bagging and boosting in ensemble learning?
Ans:
In bagging, multiple models are trained independently on randomly sampled subsets of the training data, and their predictions are combined, reducing overfitting and enhancing robustness.
Boosting, exemplified by algorithms like AdaBoost and Gradient Boosting, aims to correct errors and improve overall model accuracy. Both bagging and boosting leverage the diversity of models to achieve superior predictive performance.
47. Explain the term “ensemble learning”.
Ans:
Ensemble learning combines predictions from multiple models to enhance overall performance. By aggregating diverse models, each capturing different aspects of the data, ensemble methods reduce overfitting and increase generalization. Popular techniques include bagging (e.g., Random Forest) and boosting (e.g., AdaBoost, Gradient Boosting).
48. Explain the concept of time-series analysis.
Ans:
- Time-series analysis focuses on understanding and predicting data points ordered chronologically.
- Applications include financial forecasting, stock price prediction, and weather forecasting.
49. What is the difference between precision and accuracy?
Ans:
Precision assesses the correctness of positive predictions, emphasizing the absence of false positives. Accuracy, on the other hand, measures the overall correctness of predictions. While accuracy provides a holistic view, precision focuses on minimizing false positives, crucial in scenarios where misclassifying positive instances has significant consequences.
50. Explain the concept of transfer learning.
Ans:
Transfer learning involves leveraging knowledge gained from a pre-trained model on a source task to improve performance on a target task. In the context of deep neural networks, this technique accelerates model training by using pre-existing features learned from large datasets.
51. Enumerate PEP8.
Ans:
PEP8 is the Python Enhancement Proposal that provides style conventions for writing clean and readable code in Python. It covers various aspects such as indentation, naming conventions, import formatting, and more. Enumerating PEP8 means following these guidelines to maintain a consistent and standardized coding style across Python projects.
52. Describe a module in Python.
Ans:
- A Python module is a file that have code written in Python.
- It permits code organisation and reuse and has the ability to declare variables, classes, and functions.
- Large programmes may be divided into more manageable, smaller parts with the help of modules.
53. What is the Python use case for a negative index?
Ans:
Negative indices in Python are used to access elements from the end of a sequence (like a list or string). For example, ‘my_list[-1]’ refers to the last element of the list. Negative indices provide a convenient way to access elements without explicitly knowing the length of the sequence.

Enroll in Best Data Science with Python Training and Get Hired by TOP MNCs
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
54. When you quit Python, does memory get released?
Ans:
- Yes, the memory utilised by the Python process is freed when you terminate it.
- A built-in garbage collector in Python releases memory that is held by defunct objects automatically.
55. What does Python list comprehension mean?
Ans:
List comprehension is a productive way to build lists in Python. Its succinct syntax allows you to specify whatever components you want to have in a new list. For example, the expression ‘[x**2 for x in range(5)]’ yields a list of squares for the numbers 0 through 4.
56. Enumerate Python’s salient features.
Ans:
Python’s salient features include readability, simplicity, versatility, object-oriented programming, extensive standard library, community support, cross-platform compatibility, and dynamic typing.
57. What distinguishes Python’s / from //?
Ans:
In Python, the ‘/ ‘operator performs true division, returning a floating-point result. The ‘// ‘operator, on the other hand, performs floor division, which returns the largest integer less than or equal to the division result. For example, ‘5 / 2’ returns ‘2.5’, while ‘5 // 2’ returns ‘2’.
58. What distinguishes a module from a library?
Ans:
- Python code is contained in a single file called a module, but a library is made up of several modules.
- A library may be compared to a collection of pre-written code that is meant to be used just once on different applications.
- A library’s modules serve as its fundamental units.
59. What distinguishes ‘pass’ from ‘continue’ from ‘break’?
Ans:
‘pass’: A null operation, essentially a no-operation placeholder. It is used when syntactically some code is required, but no action is desired.
‘continue’: Proceeds to the next loop iteration without executing the remaining code in the current one.
‘break’: Exits the loop prematurely, skipping the remaining iterations.
60. What do ‘**kwargs’ and ‘*args’ mean?
Ans:
- ‘*args’ is used in a function definition to allow the function to accept any number of positional arguments. It collects them into a tuple.
- ‘**kwargs’ is used to allow the function to accept any number of keyword arguments. It collects them into a dictionary.
61. What is the difference between ‘regplot()’ and ‘lmplot()’?
Ans:
‘regplot()’ is a more basic function that displays a scatter plot with a linear regression line.
‘lmplot()’ is a more versatile function that allows you to create multiple regression plots on a FacetGrid, which can be useful for visualizing relationships in datasets with multiple subgroups.
62. What does a heatmap mean?
Ans:
A heatmap is a graphical representation of data in a matrix format where values are represented as colors. It is useful for visualizing the magnitude of a phenomenon as colors in two dimensions. Typically, darker colors represent higher values, and lighter colors represent lower values.
63. What does a density plot or kde plot serve?
Ans:
- A density plot (Kernel Density Estimate or KDE plot) is used to visualize the distribution of a continuous variable.
- It provides a smoothed representation of the data’s underlying probability density.
64. What’s known as the ‘FacetGrid’?
Ans:
A ‘FacetGrid’ is a Seaborn object that allows you to create a grid of subplots based on the values of one or more categorical variables. It is often used with functions like ‘lmplot()’ to create multiple plots, each showing a subset of the data.
65. What is the distinction between stripplot() and swarmplot()?
Ans:
‘stripplot()’ plots points along a single axis, providing a way to represent the distribution of values within categories.
‘swarmplot()’ is similar but adjusts the positions of points to avoid overlap, providing a better representation of the distribution.
66. What describes a docstring?
Ans:
In Python, a docstring is a string literal that appears as the first statement in the definition of a module, function, class, or method. It is used to document the code by stating its purpose, arguments, return values, and other pertinent information. Docstrings, which may be accessed using the ‘help()’ function, are vital for code documentation and comprehension.
67. When should we utilise crosstab and pivot_table?
Ans:
- ‘crosstab()’ is used for computing a cross-tabulation table, showing the frequency distribution of variables.
- ‘pivot_table()’ is more general and allows you to perform various aggregations on data, including sum, mean, count, etc., based on one or more categorical variables.
68. What does a Pairplot mean?
Ans:
A pairplot is a visualization technique commonly employed in data analysis using libraries like Seaborn. It is particularly useful for exploring relationships between multiple numeric variables in a dataset.
69. How can I reshape a pandas dataframe?
Ans:
Reshaping a DataFrame involves transforming it from one structure to another, typically from wide to long format or vice versa. Pandas provides several functions for reshaping data, including ‘melt()’, ‘pivot()’, ‘stack()’, and ‘unstack()’. These functions are useful when you need to organize your data differently to facilitate analysis or visualization.
70. How do you use groupby?
Ans:
The ‘groupby()’ function in Pandas is a powerful tool for splitting a DataFrame into groups based on some criteria, applying a function to each group independently, and then combining the results. This is particularly useful for aggregating data based on certain columns.
71. When should you use a for loop and a while loop?
Ans:
For Loop:
- Use a for loop when you know the number of iterations or when iterating over elements in an iterable (e.g., list, tuple, string).
- It is generally used when you have a sequence of elements to iterate through.
While Loop:
- Use a while loop when the number of iterations is uncertain and depends on a condition.
- It is typically used when you need to repeat a block of code until a certain condition is met.
72. In Python, how is exception handling accomplished?
Ans:
- Exception handling in Python is done using the ‘try’, ‘except’, ‘else’, and ‘finally’ blocks.
- It enables you to gracefully manage mistakes and exceptions, keeping your programme from crashing.
73. What exactly is the distinction between conditionals and control flows?
Ans:
Conditionals involve decision-making in code based on specified conditions, typically implemented with constructs like ‘if’, ‘elif’, and ‘else’. They control the flow of execution by determining which block of code to execute. On the other hand, control flows, encompassing loops and function calls, dictate the order in which statements or code blocks are executed, shaping the overall program flow.
74. List some of Python’s most significant Regex functions.
Ans:
- re.search(pattern, string)
- re.match(pattern, string)
- re.findall(pattern, string)
- re.sub(pattern, replacement, string)
- re.compile(pattern)
75. What exactly is the distinction between global and local variables?
Ans:
Global Variables: Defined outside of any function. Accessible throughout the entire program.
Local Variables: Defined within a function. Only available inside the context of that function.
76. How do the reduce and filter functions function?
Ans:
- ‘reduce()’ is a function from the ‘functools’ module that applies a rolling computation to sequential pairs of values in a list until it reduces to a single cumulative result.
- ‘filter()’ is a built-in function that constructs an iterator from elements of an iterable for which a function returns true.
77. Explain the function enumerate().
Ans:
The ‘enumerate()’ function is used to iterate over a sequence (such as a list) along with an index.
- for index, value in enumerate([‘a’, ‘b’, ‘c’]):
- print(f”Index: {index}, Value: {value}”)
- # Output:
- # Index: 0, Value: a
- # Index: 1, Value: b
- # Index: 2, Value: c
78. What is the distinction between is and ‘==’?
Ans:
‘==’ (Equality Operator):
- Compares the values of two objects for equality.
- Checks whether the content of the objects is the same.
- Usage: ‘a== b’.
‘is’ (Identity Operator):
- Checks if two objects refer to the same memory location.
- Verifies whether the objects are the exact same instance.
- Usage: ‘a is b’.
79. What’s the distinction between print and return?
Ans:
‘print’: Outputs information to the console for debugging or user interaction.
‘return’: Sends a value back from a function to the caller.
- def add_numbers(a, b):
- result = a + b
- print(f”The sum is: {result}”) # Print to be displayed
- return result # Return for further use
80. Specify the names of changeable and immutable objects.
Ans:
Changeable (Mutable) Objects:
- Lists
- Dictionaries
- Sets
Immutable Objects:
- Tuples
- Strings
- Numbers (int, float)
81. Specify the names of changeable and immutable objects.
Ans:
In Python, it is possible to set default values for function parameters. When defining a function, you can assign default values to some or all of its parameters. These default values are used when a value is not provided during the function call. This feature enhances flexibility and makes functions more adaptable to different use cases.
82. Explain Python run-time failures.
Ans:
Python run-time failures, commonly referred to as exceptions, occur when an error disrupts the normal flow of a program during execution. Examples include ‘TypeError’, ‘ValueError’, and ‘ZeroDivisionError’. Exception handling in Python involves using try, except, else, and finally blocks to manage and gracefully handle these run-time errors, preventing the program from crashing.
83. What are the most popular Python libraries for data science?
Ans:
- NumPy
- Pandas
- Matplotlib
- Seaborn
- Scikit-learn
83. How do you make a sorted vector from two sorted vectors?
Ans:
To create a sorted vector from two sorted vectors, you can use the merge operation. This involves merging the two vectors and then sorting the resulting vector.
- vector1 = [1, 3, 5]
- vector2 = [2, 4, 6]
- sorted_vector = sorted(vector1 + vector2)
- print(sorted_vector)
- # Outputs: [1, 2, 3, 4, 5, 6]
84. How can I import a CSV file from a Pandas library URL?
Ans:
You can import a CSV file directly from a URL using Pandas’ ‘read_csv’ function. Provide the URL as the argument, and Pandas will fetch and read the data into a DataFrame.
- import pandas as pd
- url = ‘https://example.com/data.csv’
- df = pd.read_csv(url)
85. List some NumPy array methods.
Ans:
‘numpy.array()’: Creates an array.
‘ndarray.shape’: Returns the shape of an array.
‘ndarray.reshape()’: Changes the shape of an array.
‘numpy.concatenate()’: Concatenates two arrays.
‘numpy.mean()’, ‘numpy.sum()’: Compute mean and sum, respectively.
86. What is the distinction between series and vectors?
Ans:
A series is a one-dimensional labelled array that may store any form of data. Because each element has an index, it may be thought of as a labelled vector.
A broader phrase that frequently denotes an organized collection of constituents. Vectors may be represented as Pandas Series in the context of data science.
87. What exactly are categorical distribution plots?
Ans:
Categorical distribution plots in Seaborn, such as ‘boxplot’, ‘violinplot’, and ‘swarmplot’, visualize the distribution of categorical data. They provide insights into the spread, central tendency, and shape of the data within different categories.
88. What is a distinction between list.append() and list.extend()?
Ans:
‘list.append()’:
- Adds a single item to the list’s conclusion.
- Any form of data, including lists, may be represented by the element.
‘list.extend()’:
- Adds the elements of an iterable (e.g., another list) to the end of the list.
- Extends the list, incorporating multiple elements.
89. How do you make a sorted vector from two sorted vectors?
Ans:
To create a sorted vector from two sorted vectors, you can use the ‘merge’ operation. This involves merging the two vectors and then sorting the resulting vector.
- vector1 = [1, 3, 5]
- vector2 = [2, 4, 6]
- sorted_vector = sorted(vector1 + vector2)
- print(sorted_vector)
- # Outputs: [1, 2, 3, 4, 5, 6]
90. In NumPy, find the inverse of a matrix.
Ans:
In NumPy, obtaining the inverse of a matrix is accomplished using the ‘numpy.linalg.inv()’ function. Ensure that the matrix is square and non-singular to obtain a valid inverse. The function returns the inverted matrix, allowing for various linear algebra operations. This functionality is particularly useful in solving systems of linear equations and other mathematical computations involving matrices.




