
Last updated on 19th Dec 2021| 3142
Apache HBase is used to have random, real-time read/write access to Big Data. It hosts very large tables on top of clusters of commodity hardware. Apache HBase is a non-relational database modeled after Google’s Bigtable. Bigtable acts up on Google File System, likewise Apache HBase works on top of Hadoop and HDFS.
- Need for HBase
- HBase Use Cases- When to use
- HBase Architecture Explained
- HBase Data Model
- Storage Mechanism in HBase
- HBase Read and Write Data Explained
- Features of HBase
- Benefits of HBase
- Conclusion
Need for HBase:
Apache Hadoop has gained popularity in the big data storage space, managing and processing big data as it is able to handle high data with multiple structures. However, Hadoop cannot manage high-speed random reading and reading and cannot change the file without rewriting it completely. HBase is a NoSQL, a column-based database built on top of hadoop to overcome HDFS barriers as it allows for random writing and fast learning.
Also, with data growing exponentially, affiliate websites cannot manage a variety of data to provide better performance. HBase provides durability and isolation for better storage and retrieval. “Anyone who wants to store data in an HDFS environment and wants to do anything other than read the entire file system [with MapReduce] needs to look at HBase. If you need random access, you should have HBase. “- says Gartner analyst Serv Adrian.
HBase –Understanding the Basics:
HBase could be a Data model almost like the massive Google table designed to supply random access to high-volume formal or informal Data. HBase is an Associate in Nursing integral part of the Hadoop scheme that utilizes the HDFS error tolerance feature. HBase provides period scan or write access to Data in HDFS. HBase is known as a Data store rather than a web site because it misses some necessary options of ancient RDBM like written columns, triggers, advanced question languages and secondary references.
HBase Data Model:
The HBase Data model stores compact Data with totally different Data varieties, split column size and field size. The structure of the HBase Data model simplifies Data separation and distribution throughout the gathering. The HBase Data model contains many logical elements – line key, column family, table name, timestamp, etc. the road key’s accustomed to specifically establish lines in HBase tables. The families of the columns on HBase are mounted whereas the columns, themselves, rotate.
HBase Tables – A logical assortment of lines held in numerous sections referred to as Regions.
HBase Row – standing of Data within the table.
RowKey – All entries within the HBase table are known and displayed by RowKey.
Columns – Throughout RowKey an unlimited variety of attributes is saved.
Family Column – Rat Data is sorted along as column families and every one column is held on along in an exceedingly normal storage file referred to as the HFile.
HBase Use Cases- When to use:
HBase is a perfect platform with ACID compliance options that create an ideal alternative for high-quality, period of time applications. It doesn’t need a hard and fast schema, thus developers have the choice of adding new information if required unless it’s aligned with the predefined model.
It offers users access to the location within the Hadoop scale storage, so developers will scan or write to the info set properly, while not having to scan the entire info. HBase is the best choice as a NoSQL website, wherever your application already encompasses a Hadoop set that works with massive amounts of Data. HBase helps scan / write quicker.
- HBase HMaster could be a light-weight system that has regions to regional servers within the Hadoop cluster for load loading. HMaster Responsibilities –
- Manages and Monitors Hadoop assortment
- Perform Management (Interface for making, change and deleting tables.)
- Error management
- DDL operations are handled by HMaster
- Whenever a shopper desires to alter the schema and modify any data practicality, HMaster is liable for all of those functions.
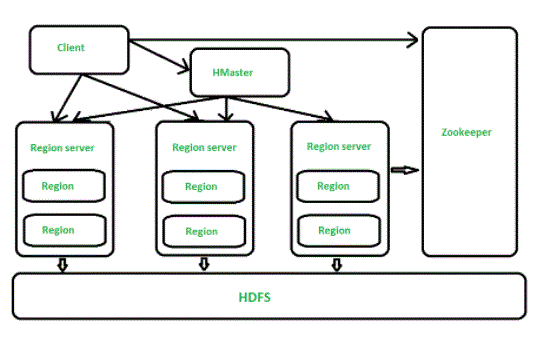
HBase Architecture Explained:
HBase provides inexpensive random reading and writing over HDFS. On HBase, the tables are at random distributed to the system whenever it becomes large to be managed (Auto Sharding). a straightforward and basic unit of horizontal measure within the HBase Region. an endless, filtered set of lines unbroken along is termed a circuit (a set set of table data). HBase design has one HBase master node (HMaster) and a couple of slaves specifically regional servers.
Every region server (slave) operates a collection of regions, and a part will solely be employed by one regional server. Whenever a shopper submits a written request, HMaster receives the request and transfers it to the corresponding regional server. HBase will work with multiple master settings, wherever only 1 key is active at a time. HBase tables are divided into multiple regions and every region maintains multiple table rows.
Components of Apache HBase design
HBase design has three key options – HMaster, Regional Server and ZooKeeper.
HMaster
Regional Server
These are employee records that handle reading, writing, reviewing, and deleting requests from shoppers. The regional Server method applies to any or all nodes within the Hadoop assortment. Regional Server operates on HDFS DataNode and contains the subsequent elements –
Block cache – this can be a browser cache. Most legible information is kept within the browser repository and whenever the repository is full, fresh used information is retrieved.
MemStore- this can be a cache repository and stores new unwritten information on disk. Each column family within the space features a MemStore. Print Log (WAL) could be a file that stores new information that’s not subject to permanent storage. HFile could be a real archive file that keeps lines as filtered keys to disk.
Animal keeper
HBase uses ZooKeeper as a distributed regional distribution service and detects any regional server crashes by uploading them to alternative active regional servers. ZooKeeper could be a centralized observance server that stores configuration data and provides distributed synchronization. Whenever a shopper desires to speak with regions, they must approach Zookeeper 1st. With HMaster and Regional servers registered with the ZooKeeper service, the shopper has to access the ZooKeeper variety to speak with regional and HMaster servers. within the event that the nodes fail among the HBase cluster, ZKquorum can trigger error messages and begin repairing failing nodes.
- Set of tables
- Each table with families of columns and rows
- Each table ought to have AN item outlined as Key Key.
- The line key acts because of the Main key on HBase.
- Each column in HBase refers to the corresponding object attribute
- The telecommunication business faces Technical challenges
- Maintains billions of CDR logs (call details) generated by the telecommunication domain
- Provide period of time access to CDR logs and client payment info
- Provide a reasonable answer compared to traditional website programs
- HBase is employed to store billions of lines of careful decision records. If 20TB of information is supplementary monthly to the prevailing RDBMS website, performance can deteriorate. Managing giant amounts of information during this usage case, HBase is the best answer. HBase promptly queries and displays records.
- The industry generates ample records a day. Additionally to the present, the industry additionally desires AN analytics answer which will sight concealing Storage, process and change giant amounts of information and perform analysis, a wonderful answer – HBase integrated with a number of parts of the Hadoop system.
- That besides, HBase is often used Whenever there’s a necessity to jot down troublesome applications.
- Perform online log statistics and compliance reports.
HBase Data Model:
HBase information Model could be a set of parts that embody Tables, Rows, Column Families, Cells, Columns, and Versions. HBase tables contain families of columns and rows with components outlined as Key keys. The column within the HBase information model table represents object attributes.
The HBase information Model contains the subsequent options:

Learn Advanced Apache HBase Certification Course to Build Your Skills
Weekday / Weekend BatchesSee Batch DetailsHBase Use Cases
The following are samples of HBase application cases with a close description of the answer we provide for numerous technical issues.
Problem Statement answer:
- Next to HBase keywords represent a table schema
- Column orientation is compared to line-based retention
- The column and end-line endings take issue in their final path. As we have a tendency to all understand connected models store information consistent with line-based format as following information lines. Column-based storage stores information tables consistent with columns and column families.
- Web-centered website
- When matters involve analysis and analysis we have a tendency to use this technique. like on-line Analytical process and your applications.
- Online dealings processes like banking and monetary domains use this technique.
- The amount of Data you’ll save during this model is as giant as petabytes
- It is designed for a little variety of rows and columns.
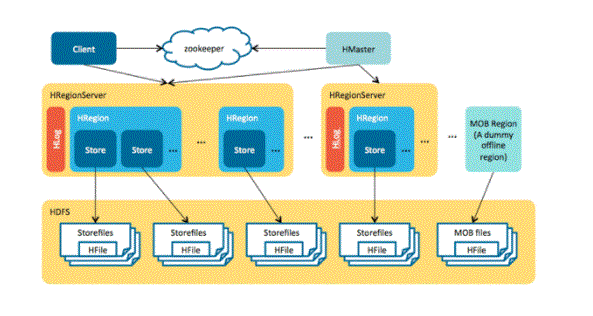
Storage Mechanism in HBase:
HBase could be a column-focused website and information is kept in tables. Table are organized by RowId. As shown below, HBase has RowId, which could be a cluster of many column families given within the table.
The column families that exist within the schema are pairs of key values. If we glance well, the family of every column features a sizable amount of columns. Column values stored in disk memory. Every table cell has its own data like timestamp and alternative data.
The following table presents the most variations between the last 2 areas:
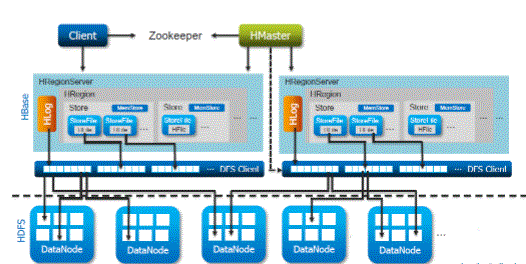
- The consumer desires to write down the info and 1st contact the Regional server then the regions
- The regions that contact the memstore to be unbroken associated with the column family
- 1st it stores the info in Memstore, wherever the info is sorted then, in HFile. The best reason to use Memstore is to store Data in a very Distributed filing system supported Line key. Memstore are going to be inserted into the most memory of the Regional server whereas HFiles are recorded in HDFS.
- The consumer desires to browse the info from the Regions
- Then the consumer has direct access to the alphabetic character store, and may request Data.
- consumer approaches HFiles to retrieve Data. Data is downloaded and downloaded by the consumer.
- Memstore keeps a memory modification future. Sequence of things in HBase regions as shown from prime to bottom within the table below.
- The HBase table is obtainable within the HBase assortment
- Regions HRegions presentation tables
- Store It stores a column every Family in each region of the table
- Memstore for every regional store table
- Sorts Data before moving to HFiles
- Literacy can increase thanks to filtering
- StoreFile StoreFiles in every regional store table
- Block Blocks at intervals StoreFiles
HBase Read and Write Data Explained:
Read and Write activities from consumer to file will be shown within the diagram below. Read and Write Data on HBase.
Memstore
- HBase is linearly measured.
- It has support for auto failure.
- Provides consistent reading and writing.
- It includes Hadoop, both as a source and destination.
- It has a simple java API for clients.
- Provides data duplication for all collections.
- When Used HBase
- Apache HBase is used for random access, real-time reading / writing of big data.
- It holds very large tables over collections of platforms.
- Apache HBase is an unrelated site depicted by Google Bigtable. Bigtable works on Google File System, as well as Apache HBase, works on Hadoop and HDFS.
- HBase Applications
- It is used whenever it is necessary to write difficult applications.
- HBase is used whenever we need to provide random quick access to available data.
- Companies like Facebook, Twitter, Yahoo, and Adobe use HBase internally.
Features of HBase:
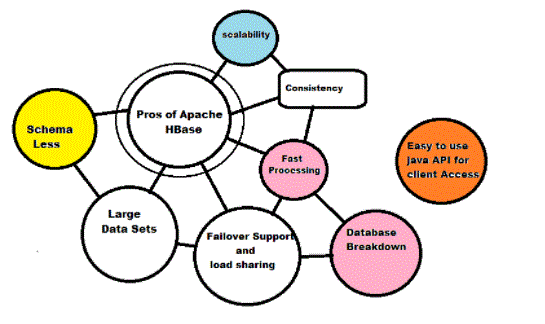
- Can store large data sets
- The website can be shared
- It is very expensive from gigabytes to petabytes
- High availability for failure and repetition
- HBase Issues –
- No SQL framework support
- No support done
- Sorted by key only
- Memory problems in the collection
Benefits of HBase:
- HBase style components: HMaster, HRegionServer, HRegions, ZooKeeper, HDFS
- HMaster in HBase is the first server implementation for HBase vogue.
- Regions are the essential building blocks of the HBase cluster that has distribution tables and is built by Column families.
- HDFS provides a high level of error tolerance and uses the foremost reasonable hardware.
- HBase information Model may be a collection of elements that embrace Tables, Rows, Column Families, Cells, Columns, and Versions.
- The column and end-line endings disagree in their final path.
Conclusion:




