
Last updated on 16th Dec 2021| 1781
The primary difference between Spark and MapReduce is that Spark processes and retains data in memory for subsequent steps, whereas MapReduce processes data on disk.
- Introduction of MapReduce vs Spark
- Meaning of Hadoop MapReduce
- Meaning of Spark
- Factors that Drive the Hadoop MapReduce vs Spark Decision
- Limitations of Hadoop MapReduce and Apache Spark
- Conclusion
- Apache Spark is an open-source, lightning speedy massive records framework that’s designed to decorate the computational velocity. While Spark can run on pinnacle of Hadoop and gives a higher computational velocity solution. This educational offers a radical assessment among Apache Spark vs Hadoop MapReduce.
- In this manual, we can cowl what’s the distinction among Spark and Hadoop MapReduce, how Spark is 100x quicker than MapReduce. This complete manual will offer function smart assessment among Apache Spark and Hadoop MapReduce.
Introduction of MapReduce vs Spark
- Hadoop MapReduce.
- HDFS (Hadoop File System)
- Hadoop MapReduce is a programming version that allows the processing of Big Data this is saved on HDFS. Hadoop MapReduce is predicated at the sources of more than one interconnected computer systems to address massive quantities of each established and unstructured records.
- Before the creation of Apache Spark and different Big Data Frameworks, Hadoop MapReduce changed into the most effective participant in Big Data Processing.
- Hadoop MapReduce works with the aid of using assigning records fragments throughout nodes withinside the Hadoop Cluster. The concept is to break up a dataset into some of chunks and follow an set of rules to the chunks for processing on the equal time. The use of more than one machines to carry out parallel processing at the records will increase the processing speed.
Meaning of Hadoop MapReduce
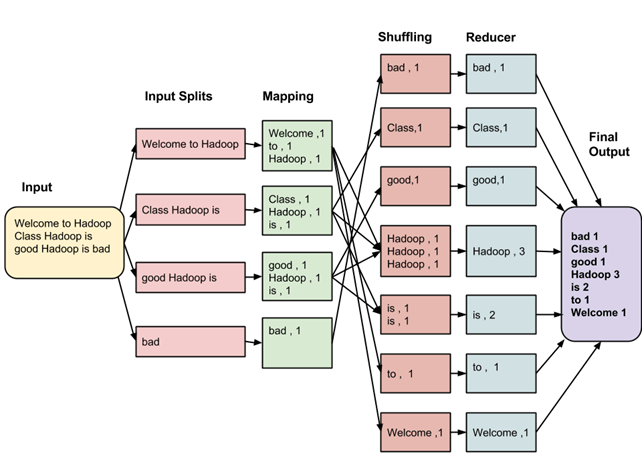
Hadoop MapReduce is a processing version in the Apache Hadoop project. Hadoop is a platform that changed into evolved to address Big Data thru a community of computer systems that shop and manner records. Hadoop has low priced committed servers that you could use to run a Cluster. You can manner your records the usage of low-price customer hardware. It is a especially scalable platform the usage of which you could begin with one device to start with and boom them later as in step with enterprise and records requirements.Its most important default additives are as follows:-
- Apache Spark is an Open-supply and Distributed System for processing Big Data workloads. It makes use of optimized question execution and in-reminiscence caching to enhance the rate of question processing on facts of any size.
- So, Apache Spark is a popular and speedy engine for processing facts on a huge scale. Apache Spark is quicker than maximum Big Data Processing solutions, and that’s why it has taken over maximum of them to turn out to be the maximum desired device for Big Data Analytics.
- Apache Spark is quicker as it runs on reminiscence (RAM) instead of on disk. Apache Spark may be used for more than one obligations which includes strolling dispensed SQL, consuming facts right into a database, developing facts pipelines, running with facts streams or graphs, system studying algorithms, and lots more.
Meaning of Spark

Learn Advanced Apache Spark Certification Training Course to Build Your Skills
Weekday / Weekend BatchesSee Batch Details- Hadoop MapReduce vs Spark: Performance.
- Hadoop MapReduce vs Spark: Ease of Use.
- Hadoop MapReduce vs Spark: Data Processing Capabilities.
- Hadoop MapReduce vs Spark: Fault Tolerance.
- Hadoop MapReduce vs Spark: Security.
- Hadoop MapReduce vs Spark: Scalability.
- Hadoop MapReduce vs Spark: Cost.
Factors that Drive the Hadoop MapReduce vs Spark Decision
To assist you make a decision which one to choose, let’s talk the variations among Hadoop MapReduce and Apache Spark:-
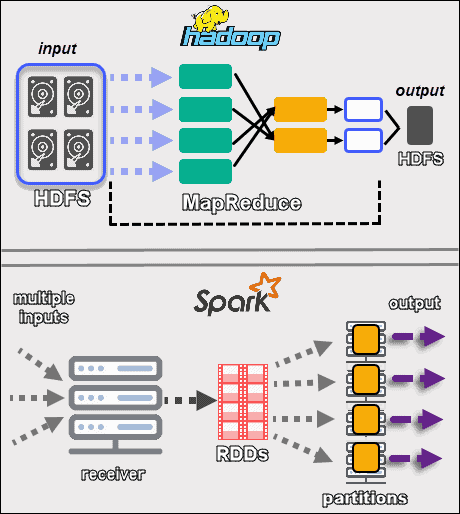
- Apache Spark is famous for its velocity. It runs one hundred instances quicker in-reminiscence and 10 instances quicker on disk than Hadoop MapReduce. The motive is that Apache Spark techniques facts in-reminiscence (RAM), whilst Hadoop MapReduce has to persist facts lower back to the disk after each Map or Reduce action.
- Apache Spark’s processing velocity supplies close to Real-Time Analytics, making it a appropriate device for IoT sensors, credit score card processing systems, advertising campaigns, protection analytics, system learning, social media sites, and log monitoring.
Hadoop MapReduce vs Spark: Performance
- Apache Spark comes with in-constructed APIs for Scala, Java, and Python, and it is usually Spark SQL (previously known as Shark) for SQL customers. Apache Spark additionally has easy constructing blocks, which make it smooth for customers to put in writing user-described functions. You can use Apache Spark in interactive mode to get on the spot remarks while jogging commands.
- On the alternative hand, Hadoop MapReduce became written in Java and is tough to program. Unlike Apache Spark, Hadoop MapReduce doesn’t offer a manner to apply it in interactive mode.
- Considering the above-said factors, it could be concluded that Apache Spark is simpler to apply than Hadoop MapReduce.
Hadoop MapReduce vs Spark: Ease of Use
- With Apache Spark, you could do extra than simply undeniable facts processing. Apache Spark can procedure graphs and additionally comes with its very own Machine Learning Library referred to as MLlib. Due to its high-overall performance capabilities, you could use Apache Spark for Batch Processing in addition to close to Real-Time Processing. Apache Spark is a “one length suits all” platform that may be used to carry out all duties as opposed to splitting duties throughout distinct platforms.
- Hadoop MapReduce is a great device for Batch Processing. If you need to get functions like Real-Time and Graph Processing, you need to integrate it with different tools.
Hadoop MapReduce vs Spark: Data Processing Capabilities
- Apache Spark is based on speculative execution and retries for each project much like Hadoop MapReduce. However, the reality that Hadoop MapReduce is based on tough drives offers it a mild gain over Apache Spark which is based on RAM.
- In case an unexpected occasion occurs and a Hadoop MapReduce system crashes withinside the center of execution, the system may also maintain in which it’s miles left off. This isn’t always feasible with Apache Spark because it should begin processing from the beginning.
- Hence, Hadoop MapReduce is extra fault-tolerant than Apache Spark.
Hadoop MapReduce vs Spark: Fault Tolerance
- Hadoop MapReduce is higher than Apache Spark as a long way as safety is concerned. For instance, Apache Spark has safety set to “OFF” with the aid of using default, that can make you susceptible to attacks. Apache Spark helps authentication for RPC channels through a shared secret. It additionally helps occasion logging as a feature, and you may stable Web User Interfaces through Javax Servlet Filters.
- Hadoop MapReduce can use all Hadoop safety features, and it is able to be incorporated with different Hadoop Security Projects.
- Hence, Hadoop MapReduce gives higher safety than Apache Spark.
Hadoop MapReduce vs Spark: Security
- Both Hadoop MapReduce and Apache Spark are Open-supply platforms, and they arrive for free. However, you need to put money into hardware and employees or outsource the development. This approach you’ll incur the fee of hiring a group this is acquainted with the Cluster administration, software program and hardware purchases, and maintenance.
- As a ways as fee is concerned, enterprise necessities must manual you on whether or not to pick out Hadoop MapReduce or Apache Spark. If you need to technique big volumes of data, take into account the use of Hadoop MapReduce. The purpose is that tough disk area is inexpensive than RAM. If you need to carry out Real-Time Processing, take into account the use of Apache Spark.
Hadoop MapReduce vs Spark: Cost
- No Support for Real-time Processing: Hadoop MapReduce is best true for Batch Processing. Apache Spark best helps close to Real-Time Processing.
- Requirement of Trained Personnel: The structures can best be utilized by customers with technical expertise.
- Cost: You will should incur the value of buying hardware and software program gear in addition to hiring skilled personnel.
Limitations of Hadoop MapReduce and Apache Spark
The following are the restrictions of each Hadoop MapReduce and Apache Spark:-
- This article supplied you with an in-intensity information of what Hadoop MapReduce and Apache Spark are and indexed different factors that pressure the Hadoop MapReduce vs Spark selection for Big Data Processing capabilities. It may be concluded that any commercial enterprise must preferably pick Hadoop MapReduce if they’re going to be processing huge volumes of statistics however if close to Real-Time Data Processing is expected, then Apache Spark will be the favored desire. Both gear could require excessive funding to installation engineering groups and buying high-priced hardware and software program gear.
- In case you need to export statistics from a supply of your desire into your favored Database/vacation spot then Hevo Data is the proper desire for you!
Conclusion




