
Last updated on 15th Dec 2021| 2160
Hive LLAP allows customers to perform sub-second interactive queries without the need for additional SQL-based analytical tools. Impala offers fast, interactive SQL queries directly on our Apache Hadoop data stored in HDFS or HBase.
- Introduction to Hive vs Impala
- Difference Between Hive vs Impala
- Key Difference Between Hive and Impala
- Benefits of Apache Hive Apache Impala
- Conclusion
Introduction to Hive vs Impala:
Apache Hive might not be ideal for interactive computing whereas Impala is meant for interactive computing. Hive is batch based Hadoop MapReduce whereas Impala is more like MPP database. Hive supports complex types but Impala does not. Apache Hive is fault tolerant whereas Impala does not support fault tolerance.

- Apache Hive facilitates in reading the big dataset saved withinside the Hadoop document device (HDFS) and different well matched document systems.
- Hive QL – For querying statistics saved in Hadoop Cluster.
- Exploits the Scalability of Hadoop via way of means of translation.
- Hive is NOT a Full Database.
- It does Not offer record-degree updates.
- Hadoop is Batch Oriented System.
- Hive Queries have excessive latency because of MapReduce.
- Hive does now no longer offer functions of It are near OLAP.
- Best acceptable for Data Warehouse Applications.
- Query execution thru MapReduce.
- question language may be used with custom scalar functions (UDF’s), aggregations (UDAF’s), and desk functions (UDTF’s).
- Hive additionally gives Indexing to accelerate, index kind together with compaction and bitmap index as of zero.10, greater index sorts are planned.
- Storage sorts supported via way of means of Hive are RCfile, HBase, ORC, and Plain textual content.
- By default, Hive shops metadata in an embedded Apache Derby database.
- Impala is a question engine that runs on Hadoop. It public beta check distribution became introduced in October 2012 and have become normally to be had on May 2013.
- It helps HDFS Apache HBase garage and Amazon S3.
- Reads Hadoop document formats, together with textual content, Parquet, Avro, RCFile, LZO, and Sequence document.
- Supports Hadoop Security (Kerberos authentication).
Difference Between Hive vs Impala:
Hive is a statistics warehouse software program mission constructed on pinnacle of APACHE HADOOP advanced via way of means of Jeff’s group at Facebook with a modern-day strong model of 2.3.zero released. It is used for summarising Big statistics and makes querying and evaluation easy. Apache Hive is an powerful fashionable for SQL-in Hadoop.
Impala is a parallel processing SQL question engine that runs on Apache Hadoop and use to technique the statistics which shops in HBase (Hadoop Database) and Hadoop Distributed File System. Apache Hive and Impala each are key components of the Hadoop device.
HIVE
IMPALA

Learn Advanced Apache Hive Certification Training Course to Build Your Skills
Weekday / Weekend BatchesSee Batch Details
- Snappy (Recommended for its powerful stability among compression ratio and decompression velocity),
- Gzip (Recommended whilst accomplishing the best degree of compression),
- Deflate (now no longer supported for textual content documents), Bzip2, LZO (for textual content documents only);
- It lets in you to question on nested systems together with maps, structs, and arrays.
- It lets in multi-person concurrent queries and additionally lets in admission manage on the premise of prioritization and queuing of queries.
It helps a couple of compression codecs:
- Hive is advanced via way of means of Jeff’s group at Facebook however Impala is advanced via way of means of Apache Software Foundation.
- Hive helps document layout of Optimized row columnar (ORC) layout with Zlib compression however Impala helps the Parquet layout with snappy compression.
- Hive is written in Java however Impala is written in C++.
- Query processing velocity in Hive is gradual however Impala is 6-sixty nine instances quicker than Hive.
- In Hive Latency is excessive however in Impala Latency is low.
- Hive helps garage of RC document and ORC however Impala garage helps is Hadoop and Apache HBase.
- Hive generates question expression at assemble time however in Impala code era for ‘’massive loops” takes place throughout runtime.
- Hive does now no longer help parallel processing however Impala helps parallel processing.
- Hive helps MapReduce however Impala does now no longer help MapReduce.
- In Hive, there may be no protection function however Impala helps Kerberos Authentication.
- In an improve of any mission wherein compatibility and velocity each are crucial Hive is a perfect preference however for a brand new mission, Impala is the best preference.
- Hive is Fault tolerant however Impala does now no longer help fault tolerance.
- Hive helps complicated kind however Impala does now no longer help complicated sorts.
- Hive is batch-primarily based totally Hadoop MapReduce however Impala is MPP database.
- Hive does now no longer help interactive computing however Impala helps interactive computing.
- Hive question has a hassle of “bloodless start” however in Impala daemon technique are commenced at boot time itself.
- Hive useful resource supervisor is YARN (Yet Another Resource Negotiator) however in Impala useful resource supervisor is native *YARN.
- Hive target target market is Data Engineers however in Impala target target market are Data Analyst/Data scientists.
- Hive throughput is excessive however in Impala throughput is low.
Key Difference Between Hive and Impala:
The variations among Hive and Impala are defined in factors offered below:
- Hive is perfect for those project where compatibility and speed are equally important
- Impala is an ideal choice when starting a new project
- Hive translates queries to be executed into MapReduce jobs
- Impala responds quickly through massively parallel processing
- Versatile and plug-able language
- Used for brute force processing
- Every hive query has this problem of “cold start”
- It avoids startup overhead as daemon processes are started at boot time
- It has SQL like queries
- It provides HDFS and apache HBase storage support
- Use familiar built in user defined functions(UFFDs) to manipulate the data
- Can easily read metadata using driver and SQL syntax from apache hive
- It is data warehouse infrastructure build over hadoop platform
- It doesn’t require data to be moved or transformed
- Used for analysis processing and visualization
- Used by programmers for running queries on HDFS and apache HBase
Benefits of Apache Hive Apache Impala:
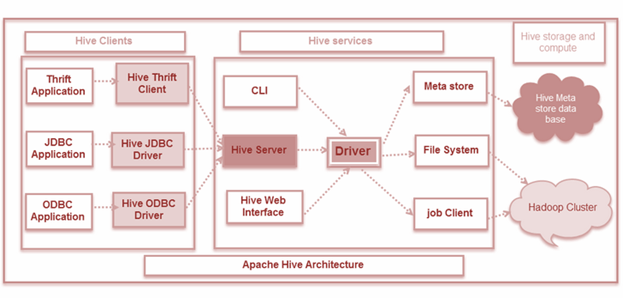
Conclusion:
In this article, we’ve attempted show off that what are technology specifically Hive vs Impala are and additionally the fundamental distinction among those technology. In sensible terms, we will say that Hive and Impala aren’t the competition they each belong to the equal basis that is called MapReduce for executing the queries, using each may also create the distinction. According to our want we will use it collectively or the high-quality consistent with the compatibility, want, and performance.
Hive question language is Hive QL which may be very flexible and time-honored language whilst Impala is reminiscence extensive and does now no longer works nicely for processing heavy information operations instance be a part of queries. If for your task paintings is associated with batch processing for a massive quantity of information, the Hive will higher if so and in case your paintings is associated with the real-time procedure of an ad-hoc question on information then Impala can be higher if so.




