
Last updated on 16th Jul 2020| 2843
Hive is a data warehouse system which is used to analyze structured data. It is built on the top of Hadoop. It was developed by Facebook.Hive provides the functionality of reading, writing, and managing large datasets residing in distributed storage. It runs SQL like queries called HQL (Hive query language) which gets internally converted to MapReduce jobs.Using Hive, we can skip the requirement of the traditional approach of writing complex MapReduce programs. Hive supports Data Definition Language (DDL), Data Manipulation Language (DML), and User Defined Functions (UDF).
Features of HiveThese are the following features of Hive:
Hive is fast and scalable.It provides SQL-like queries (i.e., HQL) that are implicitly transformed to MapReduce or Spark jobs.It is capable of analyzing large datasets stored in HDFS.It allows different storage types such as plain text, RCFile, and HBase.It uses indexing to accelerate queries.It can operate on compressed data stored in the Hadoop ecosystem.It supports user-defined functions (UDFs) where user can provide its functionality.
Important features of Hive
Hive’s command line interface (CLI) lets you to interact with it. You can write Hive queries in Hive Query Language(HQL) through this CLI.Though the name HQL sounds similar to SQL, unlike SQL that works on a traditional database, HQL works on Hadoop’s infrastructure and executes its queries here.Metastore is an important part of Hive that lies in a relational database and lets users to store schema information.WebGUI and JDBC interface are two methods that let you interact with Hive.Hive creates tables and databases and later loads data into them.
WHAT IS APACHE HIVE?
Apache Hive is a data warehouse system built on top of Apache Hadoop that facilitates easy data summarization, ad-hoc queries, and the analysis of large datasets stored in various databases and file systems that integrate with Hadoop, including the MapR Data Platform with MapR XD and MapR Database. Hive offers a simple way to apply structure to large amounts of unstructured data and then perform batch SQL-like queries on that data. Hive easily integrates with traditional data center technologies using the familiar JDBC/ODBC interface.
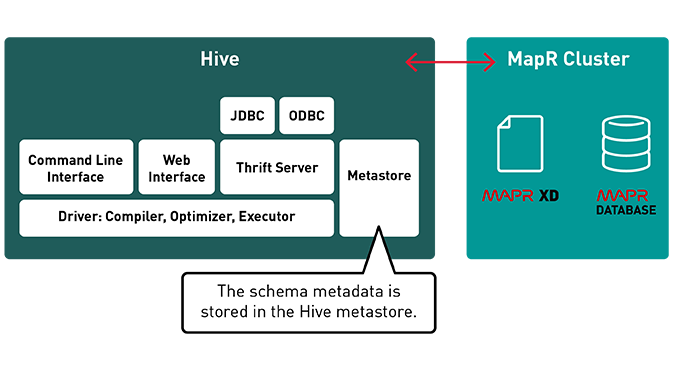
The Hive metastore provides a simple mechanism to project structure onto large amounts of unstructured data by applying a table schema on top of the data. This table abstraction of the underlying data structures and file locations presents users with a relational view of data in the file systems and NoSQL databases. Structure is applied to data at time of read, so users don’t need to worry about formatting the data when it is stored in their cluster. Data can be read from a variety of formats, from unstructured flat files with comma- or space-separated text, to semi-structured JSON files, to structured HBase tables.
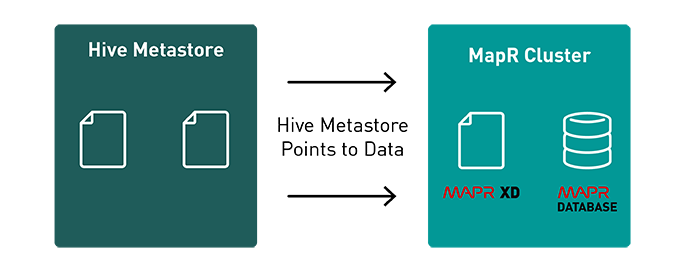
Hive features an SQL-like programming interface called HiveQL to query data stored in various databases and file systems. HiveQL automatically translates SQL-like queries into batch MapReduce jobs.
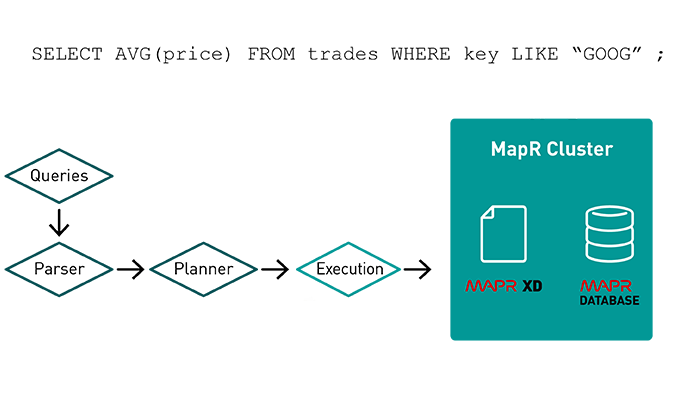
Several efforts have emerged for faster execution of HiveQL or SQL on top of Hadoop:
- Apache Spark is a powerful unified analytics engine for large-scale distributed data processing and machine learning. The Hive metastore can be used with Spark SQL and/or HiveQL can run on the Spark execution engine, optimizing workflows and offering in-memory processing to improve performance significantly.
- Apache Drill is an open source distributed SQL query engine offering fast in memory processing with ANSI SQL versus HiveQL. Drill provides the ability to leverage the metadata in the Hive metastore for querying. This is in addition to querying nested data with dynamic schemas.
- Tez has emerged as a complementary high-performance execution engine with the introduction of YARN as an independent resource manager. Hive can run on Tez, allowing queries to run significantly faster.
- Impala leverages Hive’s query language (HiveQL) and metastore to bring interactive SQL to Hadoop.
Hive Architecture
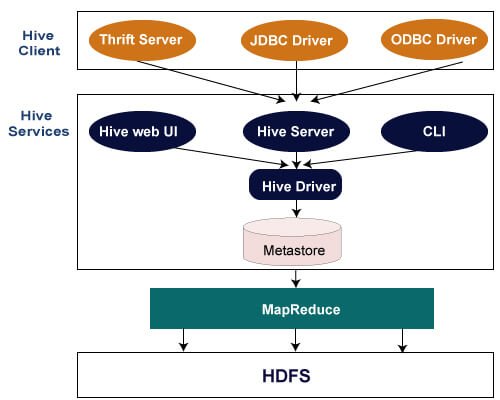
The above figure shows the architecture of Apache Hive and its major components. The major components of Apache Hive are:
- Hive Client
- Hive Services
- Processing and Resource Management
- Distributed Storage
Hive Client
Hive supports applications written in any language like Python, Java, C++, Ruby, etc. using JDBC, ODBC, and Thrift drivers, for performing queries on the Hive. Hence, one can easily write a hive client application in any language of its own choice.
Hive clients are categorized into three types:
1. Thrift Clients
The Hive server is based on Apache Thrift so that it can serve the request from a thrift client.
2. JDBC client
Hive allows for the Java applications to connect to it using the JDBC driver. JDBC driver uses Thrift to communicate with the Hive Server.
3. ODBC client
Hive ODBC driver allows applications based on the ODBC protocol to connect to Hive. Similar to the JDBC driver, the ODBC driver uses Thrift to communicate with the Hive Server.




