
Last updated on 04th Jul 2020| 7452
A data architect is a professional responsible for designing, creating, deploying, and managing an organization’s data architecture. Data architecture encompasses the structures, policies, practices, and standards that govern how data is collected, stored, arranged, integrated, and used within an organization. Given the speed at which technology and data management techniques are developing, data architects also need to be flexible and forward-thinking. Having an eye toward the future is crucial to creating a data architecture that is robust and future-proof.
1. What is data architecture, and why is it important?
Ans:
Data architecture refers to the design and organization of an organization’s data assets, including databases, data models, and storage systems. It provides a blueprint for managing, storing, and accessing data.
It is important because a well-defined data architecture ensures data consistency, reliability, and accessibility, supporting business processes and decision-making.
2. Explain the concept of normalization in database design.
Ans:
- Normalization is a process in database design that organizes data in a relational database to reduce redundancy and improve data integrity.
- It involves decomposing tables into smaller, related tables while ensuring data dependencies are properly maintained.
- The goal is to minimize data redundancy and anomalies such as insertion, update, and deletion anomalies.
3. How do you handle data redundancy in a database?
Ans:
Data redundancy is minimized through normalization, which involves breaking down tables and relationships to eliminate duplicate data. Additionally, enforcing data integrity constraints, such as unique constraints and foreign keys, helps prevent and manage redundancy. Using normalization and normalization forms like 1NF, 2NF, and 3NF helps ensure a database is free from unnecessary duplication.
4. Differentiate between logical and physical data models.
Ans:
A logical data model represents the data requirements and relationships without considering how the data will be stored. It focuses on entities, attributes, and their relationships.
In contrast, a physical data model represents how the data is stored in the database, including details like table structures, indexes, and storage mechanisms.
5. Discuss the role of indexes in database optimization.
Ans:
Indexes in a database provide a structured mechanism for quick data retrieval. They enhance query performance by reducing the number of rows that need to be scanned. However, indexes come with trade-offs, as they consume storage space and can impact insert/update/delete performance. Properly designed indexes are essential for optimizing query performance in database systems.
6. Describe the ETL process in detail.
Ans:
ETL (Extract, Transform, Load) is a data integration process.
Extract: Data is extracted from source systems.
Transform: Data undergoes transformations like cleaning, validation, and conversion.
Load: Transformed data is loaded into the target data warehouse or database. ETL ensures data quality and consistency across the organization.
7. What is a star schema and how is it used in data warehousing?
Ans:
A star schema is a type of database schema commonly used in data warehousing. It consists of a central fact table linked to dimension tables. The fact table contains quantitative data, and dimension tables provide context with descriptive attributes. This schema simplifies querying for business intelligence and reporting purposes, as it facilitates quick and efficient data retrieval.
8. Explain the benefits and challenges of denormalization.
Ans:
Denormalization involves introducing redundancy into a database design to improve query performance. Benefits include faster query execution and simplified data retrieval.
Challenges include increased storage requirements, potential data inconsistency, and the need for careful management to maintain data integrity.
9. What are the characteristics of a well-designed data warehouse?
Ans:
Performance: Efficient query and reporting performance.
Scalability: Ability to handle growing volumes of data.
Flexibility: Adaptability to changing business requirements.
Usability: User-friendly interfaces for data access and analysis.
Data Quality: Ensuring data accuracy, consistency, and integrity.
10. What distinguishes OLAP from OLTP?
Ans:
| Feature | OLAP | OLTP | |
| Purpose |
Analytical processing for decision support |
Transactional processing for day-to-day operations | |
| Data Type | Historical and aggregated data | Current, detailed transactional data | |
| Query Complexity | Complex queries involving aggregations | Simple queries for specific transactions | |
| Database Design |
Multidimensional, star, or snowflake schemas |
Normalized relational schemas |
11. How do you approach designing a database schema for a new project?
Ans:
Designing a database schema involves understanding project requirements, identifying entities and relationships, normalizing data, considering performance needs, and ensuring scalability. Prioritize data integrity, choose appropriate data types, and review the schema for flexibility and future changes.
12. What is the difference between a data lake and a data warehouse?
Ans:
- A data warehouse is structured, optimized for analytics, and stores processed data.
- A data lake is a repository for raw, unstructured data, accommodating diverse data types.
- Data lakes offer flexibility for exploration, while data warehouses provide curated data for structured analysis and reporting.
13. Explain the CAP theorem and its implications for distributed databases.
Ans:
The CAP theorem states that in a distributed system, it’s impossible to simultaneously provide Consistency, Availability, and Partition tolerance. A distributed database can prioritize two out of the three. Understanding these trade-offs is crucial; for example, sacrificing consistency for availability is common in distributed systems.
14. Discuss the advantages and use cases of NoSQL databases.
Ans:
- NoSQL databases offer flexibility, scalability, and support for large volumes of unstructured data.
- They are suitable for use cases like real-time big data processing, content management systems, and applications requiring horizontal scaling.
- NoSQL databases excel in scenarios where a flexible schema and rapid development are priorities.
15. How do you ensure data security and privacy in a data architecture?
Ans:
Implement access controls, encryption, and authentication mechanisms. Conduct regular security audits, ensure compliance with regulations, and educate stakeholders on security best practices. Additionally, use secure connections and anonymization techniques for sensitive data.
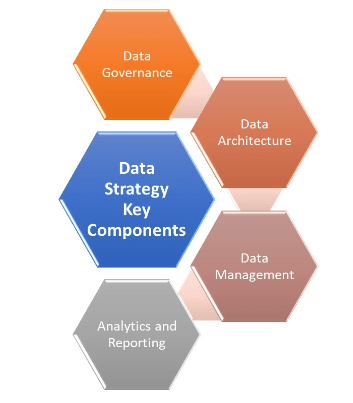
16. What are the key components of a data governance strategy?
Ans:
- A data governance strategy includes policies, standards, and processes for data management.
- Key components include data stewardship, metadata management, data quality controls, and establishing roles and responsibilities.
- Ensuring compliance with regulations and fostering a data-driven culture are also integral parts.
17. Describe the concept of sharding in database design.
Ans:
Sharding involves horizontally partitioning a database into smaller, more manageable pieces called shards. Each shard holds a subset of data, distributing the workload and improving scalability. Sharding is commonly used in distributed databases to enhance performance and accommodate growing datasets.
18. Explain the ACID properties of database transactions.
Ans:
ACID stands for Atomicity, Consistency, Isolation, and Durability.
Atomicity: Ensures that a transaction is treated as a single, indivisible unit.
Consistency: Guarantees that a transaction brings the database from one valid state to another.
Isolation: Ensures that concurrent transactions do not interfere with each other.
Durability: Ensures that once a transaction is committed, its changes are permanent and survive system failures.
19. Discuss the importance of data lineage in data management.
Ans:
Data lineage tracks the flow of data from its origin through various processes and transformations. It provides transparency, aiding in understanding data quality, compliance, and troubleshooting issues. Data lineage is crucial for maintaining control over data assets and ensuring trustworthiness in data-driven decision-making.
20. How do you address data quality issues in a dataset?
Ans:
- Addressing data quality involves profiling data, establishing data quality metrics, implementing validation rules, and cleansing data.
- Regularly monitor and cleanse data, involve data stewards, and establish governance policies.
- Data quality tools and automated processes can also assist in maintaining high data quality standards.
21. How do you handle data integration in a heterogeneous environment?
Ans:
Data integration in a heterogeneous environment involves using middleware, ETL (Extract, Transform, Load) tools, and APIs. Establish data standards, map data sources, and transform data into a common format. Implementing data virtualization and maintaining clear documentation are also essential for seamless integration.
22. What is Master Data Management (MDM), and why is it important?
Ans:
- MDM is a method of managing an organization’s critical data, such as customer information, in a centralized system.
- It ensures consistency, accuracy, and uniformity of data across an enterprise.
- MDM is crucial for improving data quality, supporting data-driven decision-making, and enhancing business processes.
23. Describe the role of metadata in data management.
Ans:
Metadata provides information about data, including its source, format, quality, and usage. It plays a crucial role in data management by enhancing data understanding, facilitating data discovery, ensuring data lineage, and supporting governance and compliance initiatives.
24. What is real-time data processing, and when would you use it?
Ans:
Real-time data processing involves handling and analyzing data as it is generated, providing immediate insights. It is used when low-latency processing is crucial, such as in financial transactions, monitoring systems, and IoT applications where timely responses are essential for decision-making.
25. Explain the principles of columnar storage in databases.
Ans:
- Columnar storage stores data in columns rather than rows, optimizing query performance.
- It improves compression, reduces I/O operations, and enhances analytical query speed.
- Columnar databases are well-suited for data warehouse scenarios with read-heavy analytical workloads.
26. How would you design a data architecture for a scalable and distributed system?
Ans:
Designing for scalability involves horizontal scaling, partitioning data, and using distributed databases. Implement load balancing, consider eventual consistency, and leverage cloud services for elasticity. Use microservices architecture to distribute workloads and ensure fault tolerance.
27. Discuss the advantages and challenges of using in-memory databases.
Ans:
- In-memory databases store data in system memory, enabling faster data retrieval.
- Advantages include improved query performance and reduced latency.
- Challenges include higher costs for large datasets and potential limitations in storage capacity compared to traditional databases.
28. What is the difference between horizontal and vertical partitioning?
Ans:
Horizontal partitioning involves dividing a table into smaller subsets based on rows, typically by range or hash. Vertical partitioning involves splitting a table into smaller subsets based on columns. Horizontal partitioning is often used for distributing data across nodes, while vertical partitioning optimizes storage by separating frequently and infrequently accessed columns.
29. Describe the concept of data virtualization and its benefits.
Ans:
- Data virtualization combines data from disparate sources, presenting it as a single, unified view.
- It provides real-time access to data without physical consolidation, reducing data duplication and ensuring agility.
- Benefits include improved data accessibility, simplified integration, and reduced data latency.
30. How do you optimize schema design for query performance?
Ans:
Optimize schema design by denormalizing where appropriate, choosing appropriate data types, creating indexes strategically, and considering partitioning for large datasets.
Analyze query patterns, use query optimization tools, and ensure the schema aligns with the specific needs of the application to enhance overall query performance.

Get Practical Oriented Data Architect Certification Course By Experts Trainers
Weekday / Weekend BatchesSee Batch Details31. Explain the concept of eventual consistency in distributed databases.
Ans:
Eventual consistency is a property in distributed databases where, after a period of time, all replicas converge to the same state. It acknowledges that, due to network partitions or latency, immediate consistency may not be achievable. Systems achieve eventual consistency through mechanisms like conflict resolution, versioning, and reconciliation.
32. How do you approach capacity planning in a data architecture?
Ans:
- Capacity planning involves estimating future data growth, analyzing workload patterns, and ensuring infrastructure can handle demand.
- Consider factors like data volume, transaction rates, and user concurrency.
- Regularly monitor and adjust resources based on usage trends, and leverage cloud services for scalability.
33. Discuss the use of data encryption for securing sensitive information.
Ans:
Data encryption protects sensitive information by converting it into unreadable ciphertext. Implement encryption at rest and in transit using robust algorithms.
Manage encryption keys securely, enforce access controls, and regularly audit encryption configurations to ensure compliance with security standards.
34. What is the role of materialized views in database optimization?
Ans:
- Materialized views store precomputed query results, reducing the need for expensive computations during query execution.
- They enhance query performance by providing quick access to aggregated or complex data.
- Materialized views are especially useful in scenarios where frequent queries involve aggregations or joins.
35. Describe the components of a Big Data ecosystem.
Ans:
Hadoop (HDFS), Spark, Kafka, and NoSQL databases (such as Cassandra and MongoDB) are examples of components that make up the Big Data ecosystem. Large amounts of heterogeneous data must also be managed and insights must be derived from it. Tools for data processing, storage, and analytics like Hive, Pig, and HBase help with this.
36. How would you design a data architecture for a cloud-native environment?
Ans:
Utilize microservices architecture, cloud-native databases, and containerization (e.g., Docker, Kubernetes) to design for cloud-native settings. For cost-effectiveness and scalability, use serverless computing. Stress cloud-native concepts like as automation, flexibility, and resilience.
37. Explain the concept of multi-model databases.
Ans:
Multi-model databases enable multiple data models (e.g., document, graph, and key-value) within a single database engine. This flexibility enables users to select the best data model for individual use cases, minimizing the need for many specialized databases and simplifying data administration.
38. How do you ensure data availability in a highly available system?
Ans:
- Ensure data availability through redundancy, failover mechanisms, and distributed architectures.
- Implement clustering and replication for data synchronization across nodes.
- Use load balancing to distribute traffic and prevent overloads. Regularly test and simulate failure scenarios to ensure quick recovery.
39. What are the challenges and benefits of polyglot persistence?
Ans:
Polyglot persistence involves using multiple data storage technologies based on the unique requirements of each application component. Challenges include increased complexity and potential data consistency issues. Benefits include optimizing data storage for specific needs, improved performance, and the ability to choose the most suitable technology for each use case.
40. What are the best practices for data migration between systems?
Ans:
Best practices include thorough planning, data profiling, ensuring data quality, and maintaining backups. Employ ETL (Extract, Transform, Load) processes, validate data at each stage, conduct tests in a controlled environment, and communicate changes transparently. Monitor and optimize performance during and after migration.

Get Data Architect Training with In-Depth Modules for Beginner to Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
41. Discuss the role of blockchain in data architectures.
Ans:
- Blockchain ensures secure, transparent, and tamper-resistant data transactions by creating a decentralized and distributed ledger.
- It provides a trust layer for data integrity, enabling traceability and immutability.
- Blockchain is used in data architectures in situations like supply chain management when transaction verifiability, trust, and transparency are critical.
42. How do you perform data modeling for unstructured data?
Ans:
Data modeling for unstructured data involves defining metadata, understanding data sources, and categorizing data based on content. Use schema-on-read approaches, classify data into logical categories, and employ techniques like document-oriented databases. Flexibility is key, and metadata plays a crucial role in describing the characteristics of unstructured data.
43. Explain the principles of data caching and its impact on performance.
Ans:
Data caching involves storing frequently accessed data in a temporary storage layer to expedite retrieval. It improves performance by reducing latency and minimizing redundant data fetches.
Implement caching strategies such as time-based expiration or LRU (Least Recently Used) to optimize for specific use cases and enhance overall system efficiency.
44. How do you design for data resilience in case of system failures?
Ans:
- Design for data resilience by implementing data redundancy, backups, and distributed systems.
- Use replication and failover mechanisms to ensure continuous availability.
- Employ proper error handling and logging to facilitate quick recovery.
- Regularly test and simulate system failures to validate the effectiveness of resilience strategies.
45. What is the role of data catalogs in modern data architectures?
Ans:
Data catalogs centralize metadata management, making it easier to discover, understand, and govern data assets. They provide a searchable inventory of datasets, data lineage, and usage information. Data catalogs enhance collaboration, ensure data quality, and support compliance initiatives by fostering a data-driven culture within organizations.
46. Describe the principles of data streaming and event-driven architecture.
Ans:
Data streaming involves processing and analyzing data in real-time as it is generated. Event-driven architecture leverages events to trigger actions or notifications. Together, they enable responsive and scalable systems.
Data streaming is effective for applications requiring low-latency processing, while event-driven architecture ensures decoupled and efficient communication between system components.
47. Discuss the considerations for choosing a data storage format.
Ans:
Considerations for choosing a data storage format include data structure, compression efficiency, and query performance. JSON is suitable for semi-structured data and interoperability, while Parquet is efficient for analytics due to its columnar storage and compression. Choose the format based on the specific requirements of data storage, processing, and retrieval.
48. What are the emerging trends in data architecture?
Ans:
Emerging trends in data architecture include the integration of artificial intelligence and machine learning, the rise of edge computing for decentralized processing, increased adoption of serverless architectures, and the growing importance of data mesh concepts. Additionally, there is a focus on data privacy and security in response to evolving regulations.
49. Explain the role of surrogate keys in database design.
Ans:
- Surrogate keys are artificial, system-generated keys used as unique identifiers for database records.
- They simplify data management, enhance performance in join operations, and provide a stable reference even if natural keys change.
- Surrogate keys are especially useful when working with distributed databases or data warehousing scenarios.
50. How do you approach data modeling for time-series data?
Ans:
Data modeling for time-series data involves defining timestamped data points, understanding temporal relationships, and choosing appropriate storage mechanisms. Use specialized databases for time-series data, consider compression techniques, and design for efficient retrieval based on time intervals. Implementing indexes on timestamps can further optimize queries.
51. Discuss the principles of Polybase and its use in data integration.
Ans:
- Polybase is a technology that allows querying and integrating data from both relational and non-relational sources using SQL queries.
- It enables seamless data integration across various platforms, providing a unified view.
- Polybase supports parallel processing and is commonly used in data warehouses for efficient analytics.
52. What is the difference between horizontal and vertical scaling in databases?
Ans:
Horizontal scaling involves adding more machines or nodes to a system, distributing the load across them. Vertical scaling, on the other hand, involves increasing the resources (CPU, RAM) on a single machine. Horizontal scaling is more cost-effective and scalable for distributed systems.
53. What is the difference between horizontal and vertical scaling in databases?
Ans:
- Designing for multi-tenancy involves using a shared infrastructure where each tenant’s data is logically isolated.
- Considerations include secure access controls, efficient resource utilization, and the ability to scale horizontally.
- Implementing a hierarchical structure with a common application layer and separate databases for each tenant ensures isolation.
54. Explain the concept of a data mesh and its relevance in modern data architectures.
Ans:
A data mesh is an approach that decentralizes data ownership and delivery by treating data as a product. It advocates for domain-oriented decentralized data teams, self-serve data infrastructure, and using APIs for data access. The data mesh concept addresses scalability and agility challenges in large organizations with diverse data needs.
55. Discuss the advantages of using in-memory caching for databases.
Ans:
- In-memory caching stores frequently accessed data in the system’s memory, reducing latency and enhancing performance.
- Advantages include faster data retrieval, improved response times, and reduced load on backend storage.
- In-memory caching is particularly beneficial for read-heavy workloads and frequently accessed data.
56. What considerations are important when designing for data archival and purging?
Ans:
Considerations for data archival and purging include defining retention policies, ensuring compliance with regulations, and balancing storage costs.
Implement a structured archival strategy based on data lifecycle, and regularly review and update policies. Ensure data integrity and maintain proper documentation for audit purposes.
57. How do you ensure data consistency in a distributed database system?
Ans:
Ensuring data consistency in distributed databases involves using techniques like two-phase commit protocols, distributed transactions, and consensus algorithms. Implementing proper isolation levels, enforcing referential integrity, and using conflict resolution mechanisms help maintain a consistent state across distributed nodes.
58. Describe the role of data profiling in data quality management.
Ans:
- Data profiling involves analyzing and assessing the quality of data within a dataset.
- It helps identify anomalies, inconsistencies, and patterns in data, enabling organizations to understand and improve data quality.
- Data profiling is a critical step in data quality management, providing insights for data cleansing, enrichment, and validation.
59. Discuss the principles of data anonymization and pseudonymization for privacy.
Ans:
Data anonymization involves removing personally identifiable information (PII) from datasets, while pseudonymization involves replacing PII with non-sensitive identifiers.
Both techniques protect privacy and are crucial for compliance with data protection regulations. Implementing strong encryption, tokenization, and ensuring irreversibility are key principles in these processes.
60. Explain the concept of schema-on-read versus schema-on-write in data lakes.
Ans:
Schema-on-read allows flexibility by storing raw data without a predefined schema, and the schema is applied when the data is read. Schema-on-write, in contrast, enforces a schema at the time of data ingestion. Data lakes often use schema-on-read to accommodate diverse data sources and evolving analytical needs, providing agility in data exploration and analysis.
61. How do you handle data partitioning for efficient query performance?
Ans:
- Data partitioning involves dividing large datasets into smaller, more manageable partitions.
- Choose a partitioning key aligned with query patterns, enabling the database to quickly locate relevant data.
- Use range, hash, or list partitioning based on data distribution characteristics, and consider partition elimination for optimizing query performance.
62. Discuss the principles of data compression in database storage.
Ans:
Data compression reduces the storage footprint by encoding data in a more efficient format. Principles include choosing appropriate compression algorithms, balancing compression ratios with decompression overhead, and considering columnar storage for analytics. Compression minimizes storage costs and can improve I/O performance.
63. How do you design for data lineage and impact analysis?
Ans:
- Design for data lineage by capturing metadata at each processing stage, documenting data flow, and creating a centralized metadata repository.
- Impact analysis involves tracing the effects of changes on downstream processes.
- Implement tools for automated lineage tracking and impact analysis to enhance transparency and decision-making.
64. Discuss the challenges and strategies for data migration in a cloud environment.
Ans:
Challenges in cloud data migration include bandwidth limitations, data integrity, and downtime concerns. Strategies involve using incremental migration, parallel processing, and leveraging cloud-native services. Employing data validation checks, monitoring, and having rollback plans mitigate risks during migration.
65. What is the role of CDC (Change Data Capture) in data replication?
Ans:
- CDC identifies and captures changes made to database records, facilitating data replication.
- It tracks insert, update, and delete operations, enabling replication processes to transmit only changed data.
- CDC is crucial for maintaining synchronized data across distributed systems and minimizing data transfer overhead.
66. Explain the principles of graph databases and their use cases.
Ans:
Graph databases represent data as nodes and edges, emphasizing relationships. Principles include traversing relationships efficiently, using graph query languages (e.g., Cypher), and leveraging graph algorithms. Graph databases excel in use cases such as social networks, fraud detection, and recommendation engines where relationships are key.
67. How do you implement data versioning to manage changes in data structures?
Ans:
- Data versioning involves maintaining historical versions of data structures.
- Implement version control mechanisms, timestamping, or snapshotting to capture changes over time.
- This is crucial for auditability, tracking schema evolution, and ensuring compatibility with evolving application requirements.
68. Describe the principles of data deduplication and its impact on storage efficiency.
Ans:
Data deduplication removes redundant copies of data, optimizing storage efficiency. Principles include using hash algorithms to identify duplicate data, employing block-level or file-level deduplication, and considering global or local deduplication. Deduplication reduces storage costs and accelerates data transfer.
69. How would you design a data architecture for real-time analytics?
Ans:
Designing for real-time analytics involves using stream processing frameworks, in-memory databases, and scalable storage. Implement data pipelines for continuous ingestion, leverage distributed processing, and choose analytics tools suitable for low-latency querying. Consider microservices architecture for modular and scalable components in real-time analytics systems.
70. Explain the principles of data masking and its use in securing sensitive information.
Ans:
- Data masking involves replacing sensitive information with fictional or anonymized data in non-production environments.
- Principles include preserving data realism for testing while ensuring data privacy.
- Dynamic masking techniques, consistent across applications, are used to protect sensitive information from unauthorized access.
71. Explain the use of materialized views for aggregating and pre-computing data.
Ans:
Materialized views store precomputed aggregations or joins, reducing query processing time. They enhance performance by allowing direct access to summarized data, especially in analytics scenarios. Materialized views are updated periodically, striking a balance between query performance and data freshness.
72. Discuss the principles of federated databases and their advantages.
Ans:
- Federated databases integrate data from multiple autonomous and distributed sources, providing a unified view.
- Principles include virtualization, abstraction of data sources, and query optimization.
- Advantages include real-time access to diverse data, improved scalability, and reduced data duplication.
73. How do you handle data consistency in a distributed microservices architecture?
Ans:
Achieving data consistency involves using distributed transactions, eventual consistency models, and compensating transactions. Implement strong consistency for critical transactions and eventual consistency for less critical scenarios. Leverage messaging patterns like Saga for orchestrating distributed transactions in a microservices architecture.
74. Discuss the considerations for designing a data architecture that complies with GDPR.
Ans:
- Designing for GDPR compliance involves data anonymization, explicit consent mechanisms, and robust security practices.
- Consider data minimization, purpose limitation, and implementing the right to be forgotten.
- Ensure transparent data processing, document compliance measures, and appoint a Data Protection Officer.
75. What is the role of Apache Kafka in event-driven data architectures?
Ans:
Apache Kafka acts as a distributed event streaming platform, facilitating real-time data integration and communication between microservices. It provides durability, fault tolerance, and scalability for event-driven architectures. Kafka enables decoupled communication, ensuring reliable and ordered event processing.
76. Explain the principles of data lakes governance and metadata management.
Ans:
Data lakes governance involves defining policies, access controls, and metadata management to ensure data quality, security, and compliance. Metadata catalogs document data lineage, quality, and usage. Governance principles include data classification, versioning, and monitoring to maintain a well-managed and secure data lake.
77. Discuss the advantages and challenges of using a document-oriented database.
Ans:
- Document-oriented databases store data as JSON or BSON documents, providing flexibility and scalability.
- Advantages include schema flexibility, support for nested structures, and ease of horizontal scaling.
- Challenges include potential for data redundancy and the need for careful schema design to avoid performance issues.
78. How do you approach data modeling for geospatial data?
Ans:
Geospatial data modeling involves defining spatial relationships, using spatial indexes, and selecting appropriate coordinate systems. Leverage specialized geospatial databases or extensions for efficient querying. Considerations include data precision, geometric operations, and support for various geospatial data types.
79. Explain the principles of data tiering in storage systems.
Ans:
- Data tiering involves categorizing data based on access frequency and assigning storage tiers accordingly.
- Hot data is stored in high-performance, expensive storage, while cold data is moved to lower-cost, slower storage.
- Automated tiering ensures cost efficiency while meeting performance requirements.
80. How do you design for data redundancy without compromising performance?
Ans:
Design for data redundancy by using techniques like replication, sharding, or denormalization for improved performance. Choose redundancy based on access patterns and data criticality. Implementing synchronization mechanisms, such as Change Data Capture, ensures consistency across redundant datasets without sacrificing performance.
81. How do you design for data access control and authorization?
Ans:
- Design for data access control involves implementing role-based access, encryption, and robust authentication mechanisms.
- Fine-grained authorization ensures users have appropriate access rights.
- Centralized access control systems and auditing mechanisms help monitor and enforce data security policies.
82. Discuss the principles of time-series databases and their use cases.
Ans:
Time-series databases specialize in storing and querying data points indexed by time. Principles include efficient compression, indexing, and handling large volumes of timestamped data. Use cases include IoT applications, financial markets, and monitoring systems where analyzing data trends over time is critical.
83. What is the role of Apache Hadoop in modern data architectures?
Ans:
- Apache Hadoop is a distributed storage and processing framework for big data.
- It provides the Hadoop Distributed File System (HDFS) for storage and MapReduce for parallel processing.
- Hadoop is foundational in modern data architectures, supporting scalable and fault-tolerant processing of large datasets.
84. Explain the concept of schema evolution and its importance in data management.
Ans:
Schema evolution allows databases to adapt to changing requirements by modifying schema structures. It is crucial for managing evolving data models without disrupting existing systems. Techniques include backward and forward compatibility, versioning, and using tools like schema migrations to ensure smooth transitions.
85. Discuss the principles of data replication and disaster recovery.
Ans:
Data replication involves creating redundant copies of data to ensure availability and fault tolerance. Disaster recovery planning includes backup strategies, off-site storage, and failover mechanisms. Principles include synchronous or asynchronous replication, backup frequency, and defining recovery point objectives (RPO) and recovery time objectives (RTO).
86. Explain the principles of data integration for disparate data sources.
Ans:
- Data integration involves combining data from different sources into a unified view.
- Principles include ETL (Extract, Transform, Load) processes, data cleansing, and ensuring semantic consistency.
- Use tools for data profiling and mapping to harmonize diverse data formats, structures, and schemas.
87. How do you approach data architecture for data-intensive applications?
Ans:
Designing for data-intensive applications involves using scalable storage solutions, distributed processing frameworks, and optimizing data access patterns. Employ data compression methods, take into account partitioning and indexing procedures, and leverage caching for performance. To handle massive amounts of data with flexibility and scalability, utilize cloud services.
88. Explain the principles of data obfuscation.
Ans:
Data obfuscation involves disguising sensitive information to protect privacy. Principles include using techniques like anonymization, pseudonymization, and tokenization.
Obfuscation ensures that even if unauthorized access occurs, the data is not personally identifiable. Implement robust encryption and adhere to data protection regulations.
89. How would you approach data architecture for a machine learning system?
Ans:
Designing for a machine learning system involves data preprocessing, feature engineering, and selecting suitable storage for training and inference data. Consider real-time and batch processing, model versioning, and integration with data pipelines. Implement scalable and reproducible workflows to support model training, deployment, and monitoring.
90. What is the role of data stewardship in effective data management?
Ans:
Data stewardship involves managing and overseeing an organization’s data assets. The role includes defining data policies, ensuring data quality, and promoting data governance. Data stewards collaborate with various stakeholders to maintain data integrity, compliance, and usability.




