Last updated on 23rd Jul 2025| 11131
- Introduction
- Definition of Data Lake
- Data Warehouse Overview
- Data Structure Differences
- Data Processing
- Storage Technologies
- Query Performance
- Use Cases
- Scalability and Flexibility
- Cost Considerations
- Conclusion
Introduction
In today’s data-driven landscape, organizations face the challenge of storing, processing, and analyzing enormous volumes of data from diverse sources. Database Training explores the architectural foundations of modern data systems. Two foundational technologies address this need data lakes and data warehouses. Though both serve as data repositories, they differ in architecture, usage, and capabilities. Understanding their differences and strengths is crucial for businesses aiming to establish scalable and efficient data management infrastructures.
Do You Want to Learn More About Database? Get Info From Our Database Online Training Today!
Definition of Data Lake
A data lake is a centralized repository designed to store data in its native, raw format. Whether the data is structured, semi-structured, or unstructured, it is ingested as-is and stored without the need for immediate processing. Buzzword in Database Management like schema-on-read architecture provide immense flexibility, making them ideal for big data analytics, artificial intelligence (AI), and machine learning (ML) projects. The ability to store diverse data types from sensor data and social media feeds to text documents and video makes data lakes indispensable for exploratory data analysis.
Data Warehouse Overview
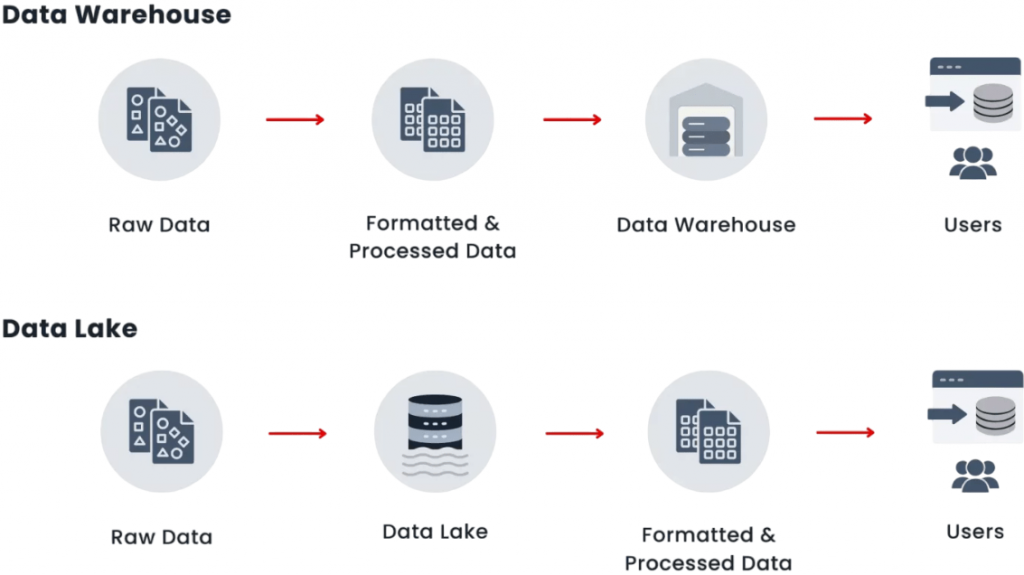
- Conversely, a data warehouse is a structured and curated environment built for the purpose of business intelligence and reporting. How to Become an SQL Developer involves mastering database design principles like schema-on-write. Employing a schema-on-write approach, data is cleaned, transformed, and organized into predefined formats before being stored.
- This ensures consistency, accuracy, and fast query performance, which are essential for dashboards, scorecards, and compliance reporting. Data warehouses are typically optimized for analytical queries over historical data.
- The core distinction between a data lake and data warehouse lies in the data structure they accept and manage. Data lakes support a wide range of file types including JSON, XML, CSV, image files, and video.
- Database Training covers the versatility of modern data platforms. They can also handle logs, clickstreams, and IoT sensor outputs without conversion. This inclusivity makes them suitable for advanced analytics use cases.
- In contrast, data warehouses accept only structured data. Every data element must fit into a table, with rows and columns clearly defined in advance. This makes data warehouses excellent for repeatable reporting but limits their use for rapidly evolving or unstructured data types.
- MongoDB vs SQL comparisons often highlight structured data advantages in warehousing. Structured data stored in a warehouse benefits from predefined schemas, indexes, and optimized queries. This allows for extremely fast performance, especially when dealing with aggregate metrics and multidimensional analysis. Business intelligence (BI) tools easily integrate with warehouses, enabling smooth dashboarding and reporting.
- Querying in a data lake can be slower, particularly with unstructured or semi-structured data. Engines like Presto, Hive, and AWS Athena provide SQL-like access, but query speed heavily depends on data format, partitioning, and metadata cataloging. However, modern lake engines like Apache Iceberg and Delta Lake are narrowing this gap.
- Machine learning and AI model training: Utilize large volumes of raw data for model development.
- Streaming data and real-time analytics: Process and analyze continuous data from IoT devices and system logs.
- Exploratory data analysis: Enable data scientists to discover patterns and test hypotheses.
- Archival and historical data storage: Store massive datasets for long-term retention and reference.
- Structured reporting and dashboarding: Support business intelligence tools for visualization and reporting.
- Financial forecasting and auditing: Analyze historical financial data to plan budgets and ensure compliance.
- Operational reporting: Provide insights to business stakeholders for day-to-day decision making.
- Historical trend analysis and KPI tracking: Monitor performance over time and measure key metrics.
Would You Like to Know More About Database? Sign Up For Our Database Online Training Now!
Data Structure Differences

Data Processing
In a data lake, data processing follows the schema-on-read principle, meaning data is parsed and formatted only when it’s accessed for analysis. This enables rapid ingestion but often shifts the complexity to the querying stage.
Tools like Apache Hadoop, Spark, Flink, and Kafka support distributed and parallel processing, enhancing performance for large-scale batch and real-time tasks. Data warehouses operate on a schema-on-write basis, where data undergoes extensive transformation, cleansing, and structuring before storage. While this delays data availability, it results in faster and more efficient querying. SQL-based engines such as Snowflake, Redshift, and BigQuery enable rapid data access, especially for business users.
To Earn Your Database Certification, Gain Insights From Leading Blockchain Experts And Advance Your Career With ACTE’s Database Online Training Today!
Storage Technologies
Data lakes generally use scalable, low-cost storage such as Amazon S3, Azure Data Lake Storage, Google Cloud Storage, and Hadoop Distributed File System (HDFS). These solutions provide object-based storage capable of handling petabytes of data at a low cost. NoSQL is the Ultimate Solution for Database Management due to its flexibility in storing diverse data types. File formats like Parquet, Avro, and ORC further optimize storage efficiency and read performance. Data warehouses rely on high-performance storage platforms that prioritize read efficiency. Vendors like Snowflake, Redshift, Azure Synapse, and BigQuery use columnar storage and indexing techniques to speed up analytical queries. While effective, the storage costs are often higher than those in data lakes.
Query Performance
Preparing for a Database Job? Have a Look at Our Blog on Database Interview Questions and Answers To Ace Your Interview!
Use Cases
Data Lake Use Cases:
Data Warehouse Use Cases:
Scalability and Flexibility
One of the standout advantages of data lakes is their scalability. Cloud-based object stores enable horizontal scaling with minimal administrative effort. The ability to ingest data from diverse sources and formats without prior transformation enhances flexibility, particularly in dynamic and experimental environments.
Data warehouses are also scalable, especially modern cloud-native versions. However, they perform best when scaling within structured paradigms. Adding new data sources often requires schema adjustments and ETL (Extract, Transform, Load) reconfigurations. While some semi-structured support exists (e.g., JSON), true flexibility is limited compared to lakes.
Cost Considerations
Storing data in a data lake is generally cheaper due to the use of object storage and the lack of extensive ETL processes. Moreover, businesses can defer processing costs until querying, making lakes economically viable for long-term storage. Data Independence in DBMS is a key principle that separates application logic from data structure. Data warehouses, on the other hand, involve higher costs tied to compute-intensive processing, indexing, and schema maintenance. These costs are justified by high performance and reliability in structured analysis. Cloud providers now offer pricing models that separate compute and storage, offering more flexibility.
Conclusion
Data lakes and data warehouses play complementary roles in modern data architecture. Data lakes offer scalable, cost-effective solutions for storing a wide range of data types, making them ideal for analytics, ML, and real-time processing. Database Training highlights the strengths of data warehousing. On the other hand, data warehouses provide fast, reliable, and structured querying capabilities, enabling efficient business reporting and decision-making. Today, many organizations are adopting a hybrid approach known as the “data lakehouse,” which merges the scalability of data lakes with the performance and governance of data warehouses. This enables unified data architecture that caters to multiple stakeholders from data engineers and scientists to business analysts and executives. Ultimately, the choice between a data lake and data warehouse or a combination of both depends on the specific needs of your organization, including data diversity, query performance, user expertise, and budget. Understanding these technologies empowers businesses to design robust and forward-thinking data strategies that drive innovation and competitive advantage.




