
Last updated on 11th Oct 2024| 5418
CouchDB is a NoSQL database that employs a schema-free JSON format for data storage, offering flexibility and ease of use. It is designed for scalability, enabling applications to efficiently manage large volumes of data. Key features include a strong replication system, multi-version concurrency control, and a RESTful HTTP API for smooth interaction. Ideal for web applications and mobile platforms, CouchDB provides excellent offline capabilities and synchronization.
1. What is the language for writing CouchDB?
Ans:
CouchDB is built in Erlang, one of the strongest and most fault-tolerant languages ever known. Erlang ensures that CouchDB can efficiently carry out concurrent processes, making it ideal for distributed systems. Because of Erlang, CouchDB can even gracefully recover from failures. Finally, it uses JavaScript for its MapReduce functions and views. This implies both backend stability and flexible querying. This architecture will ensure the performance and scalability of several applications.
2. What is CouchDB?
Ans:
CouchDB is one of the categories of NoSQL open-source databases that implement a document-oriented storage model. It is developed for extreme ease of use and reliability, owing to its schema-less data format. Data is stored in JSON format, thus allowing a certain degree of flexibility in the data structure. CouchDB supports Multi-Version Concurrency Control, or MVCC, to ensure data integrity.
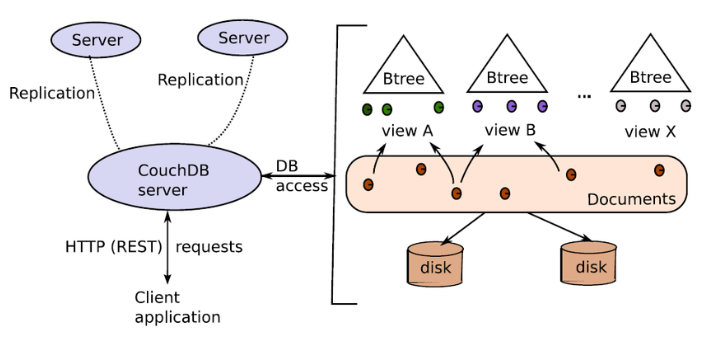
3. Why Doesn’t CouchDB Use Mnesia?
Ans:
- Mnesia is a distributed database management system that originates from Erlang but is not used in CouchDB.
- There are architectural reasons for this. Indeed, CouchDB is a document-oriented database optimized for storing JSON data, while Mnesia is designed to optimize its structure for structured data with fixed schemas.
- In addition, CouchDB’s use of MVCC allows for stronger data consistency in distributed environments. Mnesia is powerful, but its approach to scalability and replication is not as nice as CouchDB’s.
4. What makes PouchDB different from CouchDB?
Ans:
- While CouchDB is a NoSQL server-side database, PouchDB is a client-side JavaScript database for web applications.
- PouchDB enables data maintenance in local storage even when it’s not possible to connect to CouchDB; it syncs with CouchDB where there is access. The two databases share the same nature concerning data structures and API designs, making it easy to sync them.
- Meanwhile, while CouchDB is mostly focused on storage and replication on the server side, PouchDB is focused on targeting the browser and mobile environments; together, they deliver seamless experiences to applications that require offline functionality.
5. What are the three most important features of CouchDB?
Ans:
The top three characteristics that characterize CouchDB are its documentation-oriented storage model, flexible data representation, replication, and sophisticated Multi-Version Concurrency Control (MVCC) mechanism used for data integrity during multi-partitioned concurrent operations. The database uses the most natural interfaces with web applications-the restful HTTP/JSON API and is ideal for databases supporting web-based applications.
6. What is CouchDB used for?
Ans:
CouchDB is used in various applications that require flexible data storage with minimum hassle in synchronization. It is ideal for web and mobile applications that require offline capabilities and seamless data replication. Common use cases include content management systems, customer relationship management, and IoT applications. The ease with which CouchDB handles JSON documents makes it well-suited for projects whose data structures evolve frequently.
7. Explain on CouchdbKit.
Ans:
- CouchdbKit is a web framework designed to facilitate access to CouchDB. Its interface is simplified, making it simple to use.
- The tool equips developers with the knowledge to create, manage, and manipulate CouchDB documents easily. Being both client and server development-friendly, CouchdbKit has many real-world applications.
- CouchdbKit features include data synchronization, document management, and view generation. By abstracting away the complexities directly involved in interacting with CouchDB, the toolkit eases productivity.
8. How do CouchDB and MongoDB compare?
Ans:
| Feature | CouchDB | MongoDB |
|---|---|---|
| Database Model | Document store with schema-free JSON | Document store with BSON format |
| Data Storage | JSON documents | BSON documents (Binary JSON) |
| Query Language | MapReduce and Mango (query language) | MongoDB Query Language (MQL) |
| Replication | Multi-master replication | Master-slave and replica set replication |
| Scalability | Horizontal scaling through sharding | Horizontal scaling with sharding |
9. What are the main functional building blocks of Couchbase Server?
Ans:
Couchbase Server is a collection of several functional building blocks. The set includes data management, indexing, query, and analytics services. Data management services hold and retrieve the data with good high-performance. Indexing services allow access to documents without hindrances on varied index formation strategies that improve query performances. Query services enable N1QL, providing SQL-like queries on JSON documents.
10. What is a Couchbase Server data manager?
Ans:
The data manager in the Couchbase Server manages data storage, retrieval, and replication across nodes. It helps to ensure that its stored data are kept integral and consistent by data partitioning and replication strategy mechanisms. It optimizes the access pattern to data in an appropriate way for fast reading as well as writing data. It also compresses data and caches data for better performance. It supports scalability and high availability in distributed environments because of its data distribution management.
11. What is the VBucket?
Ans:
- A VBucket is an entity that represents a logical partition of data in the Couchbase Server. It enables efficient data distribution within nodes and load balancing.
- A document is distributed to a particular VBucket based on a hashing algorithm. Thus, there can be great horizontal scaling because data can be distributed among several servers.
- When a node is added or removed, only the affected VBuckets are rebalanced, thereby minimizing disruption.
- VBuckets enable replication by providing redundancy and fault tolerance through multiple copies of data.
12. What are some components that are within a Couchbase Node?
Ans:
- A Couchbase node includes the following major key components: the data service, index service, query service, and eventing service.
- Data service: It manages how a file is stored and retrieved in the document, ensuring efficient access to data. It also accommodates secondary indexing on the index service to provide for a quicker query process.
- The query service accommodates N1QL capabilities to process the query in the database; this facility accommodates SQL-like access to JSON documents. The eventing service provides further aspects of real-time processing and triggering actions based on data change.
13. What is Data replication, and what does it mean?
Ans:
Data replication entails copies of the database objects maintained on different nodes or elsewhere. It also ensures a consistent copy of data available should node failure occur or in a scenario where the network cannot access. On CouchDB, replication can be synchronous or asynchronous and is flexible in data consistency models. Replication adds to data availability and integrity in that applications continue to run even with outages.
14. What Is N1QL?
Ans:
N1QL, pronounced “nickel,” is a SQL-like query language developed specifically for Couchbase to query JSON documents. It enables developers to write expressive queries using familiar SQL syntax, even when working with unstructured data. N1QL supports many operations, including filtering, sorting, and joining, which improve the ability to analyze data. This language enables the expression of powerful querying capabilities that support the incorporation of applications already developed.
15. Describe the Data Structures of the Couchbase server.
Ans:
- The main data structures of Couchbase Server are primarily used to design data, which is kept for storage and ordered very efficiently.
- The base data type of Couchbase Server is the JSON document, which allows for a very elastic schema design. Secondary indexes increase query time by providing an additional pat to access the data.
- VBuckets allow the distribution of data and load-balancing on many nodes. These ensure that operations are optimal for reads and writes while maintaining data consistency.
16. What are the advantages of using CouchDB for data storage?
Ans:
- CouchDB provides several key advantages such as its schema-free data model that allows flexible document structures.
- It supports replication, thus allowing high availability and fault tolerance in distributed systems. The database relies on MVCC to maintain concurrent updates, which enhances data integrity.
- Its application programming interface, HTTP/RESTful API, makes integrating with web applications and services easy.
- Moreover, its handling of large volumes of JSON data makes it suitable for various application types. In summary, CouchDB’s design results in scalability, reliability, and ease of use.
17. How does the CouchDB version document?
Ans:
CouchDB manages document versioning through Multi-Version Concurrency Control (MVCC), allowing multiple versions of a document to coexist. When a document is updated, previous versions are retained for conflict resolution, and a new version is created. This enables users to access and restore earlier versions as needed. The ‘_rev’ field tracks revisions, ensuring updates occur in the correct order. MVCC minimizes data loss and prevents overwrites during concurrent edits, enhancing data integrity and flexibility in managing changes.
18. What is a View in CouchDB?
Ans:
A view in CouchDB is a query mechanism that enables the retrieval and transformation of document data. It is defined by a Map function, which processes documents to extract relevant information, and an optional Reduce function aggregates results. Views make it possible to efficiently query large datasets by indexing data along specified criteria. The pre-computation of results may reduce the database load when executing queries.
19. How does CouchDB ensure the integrity of the data during replication?
Ans:
- CouchDB ensures data integrity during replication through Multi-Version Concurrency Control (MVCC) and conflict resolution. MVCC ensures multiple revisions of documents so that data loss is avoided during simultaneous updates.
- When replication occurs, CouchDB compares revisions made within the documents and only synchronizes the changes made; hence, it keeps consistency among nodes.
- In the event of conflicts, CouchDB provides methods that allow the user to determine how to handle conflicting updates. This philosophy enhances data reliability and thus makes CouchDB completely immune to network problems and system crashes.
20. What’s the purpose of the _id field in CouchDB documents?
Ans:
- In CouchDB, a document’s ‘_id’ field serves as an identifier for every document in the database. This allowed for the efficient retrieval, updating, or deletion of a document based on its identifier.
- The uniqueness of the ‘_id’ field also prevented duplicate entries, which was important for maintaining data integrity.
- Also, the _id field was important in replication across nodes because it permitted the tracking of document modifications.
- The design of it allows easy documentation referencing and linking in applications. Overall, this ‘id’ field is very important in CouchDB for managing documents.
21. How does CouchDB document creation work?
Ans:
The approach to document creation in CouchDB will mean primarily specifying its structure in JSON. Every document needs to contain a unique “_id” field; it is the document’s identifier. Once prepared, the document is sent to the CouchDB over an HTTP POST request to a database endpoint. When received by CouchDB, a document will be assigned a revision identifier called ‘_rev.’ In other words, the version of the document is identified.
22. What kinds of data can CouchDB store??
Ans:
CouchDB mainly uses JSON format to store the data. Therefore, it can store all sorts of data types and structures. This includes simple key-value pairs, complex nested objects, and arrays. Any data represented in JSON can be stored, such as text, numbers, dates, and base64-encoded binary data. The flexibility allows it to support diverse applications, from content management systems over weblogs to IoT solutions.
23. How does CouchDB resolve conflicts?
Ans:
CouchDB resolves conflicts using the inherent MVCC system, where it keeps many revisions of a document. If there are concurrent updates, CouchDB does not lose any versions and leaves the version control entirely to the users, who can resolve conflict[s] on end. The revision history for a document is available through the ‘_rev’ field, which references the latest version. There are two options for handling the conflict: choose a specific version or manually merge all the c, changes. A method like this will ensure the integrity and flexibility to handle updates.
24. What kind of indexes does CouchDB support?
Ans:
- CouchDB supports many forms of indexes to optimize data retrieval and querying. The main index is the View index, which CouchDB creates using MapReduce functions that extract and organize the data according to defined criteria.
- Secondary indexes can support fast lookups in particular document fields. On the other hand, full-text search indexes can be combined with external tools like Elasticsearch to manage more complex search queries.
- In addition, CouchDB includes built-in indexing that improves performance by precomputing results for queries. These indexing choices allow flexibility in accommodating all application needs.
25. What is a CouchDB design document?
Ans:
- In CouchDB, a design document may be described as the container holding Views and any other database functionality, such as validation and configuration settings.
- Each design document has a specific ID prefixed with ‘_design/.’ This feature allows for retrieving and administrating those design documents at the earliest possible time.
- Data can be accessed through custom logic by defining Views in a design document. In addition, design documents can embed validation and update processing functions using JavaScript.
26. How does CouchDB make it possible for an application to support offline capabilities?
Ans:
CouchDB allows an application to support mainly offline capability through its replication capabilities and PouchDB. PouchDB is a client-side database with capabilities to extend functionality support when it works offline by changing local storage. This reconnects to establish connectivity and then re-syncs with CouchDB so that all devices will be updated. It does this seamlessly through CouchDB’s replication protocols, which handle any possible data conflicts very well.
27. What is the CouchDB HTTP API?
Ans:
The CouchDB HTTP API is a standardized interface for interacting with the database over the web. Developers can use standard HTTP methods to conduct CRUD operations on documents: create, read, update, and delete. The API uses a RESTful approach to simplify integration across various programming languages and frameworks. It supports querying, replication, and administration tasks. It also allows users to have comprehensive access to CouchDB functionalities. Database management and monitoring can also be done using remote HTTP requests.
28. How does CouchDB track changes?
Ans:
- Changes in CouchDB are tracked with a feature called the ‘_changes’ feed. This feed is essentially a real-time stream of document modifications.
- The feed can be accessed through HTTPso, so applications can listen for updates and respond accordingly. All changes are associated with a revision ID, which makes it feasible to track a document’s last state.
- The database keeps a history of all revisions on each document. That means prior versions can be retrieved at will, ensuring data consistency in distributed systems.
29. How does the MVCC model affect CouchDB?
Ans:
- The CouchDB’s usage of the MVCC model radically improves data integrity quality and performance concerning concurrent updates.
- MVCC does not allow data to be overwritten or lost due to simultaneous changes made by multiple users because multiple versions of the same document are kept.
- This is particularly important during read-and-write operations, as readers can access stable versions while writers update the document.
- Moreover, in case of data conflicts, various mechanisms are available for resolving discrepancies in data without losing its consistency.
30. Explain the features of CouchDB’s clustering.
Ans:
CouchDB supports clustering to enhance scalability and availability in distributed environments. Clustering allows several CouchDB nodes to operate and distribute the data across those nodes using VBuckets. This architecture ensures that when a node fails, data is still accessible through replicas replicated on other nodes. The upshot is that CouchDB has built-in clustering capabilities, so load balancing can be done in case lots of resources are consumed.
31. How does CouchDB store and retrieve its data?
Ans:
CouchDB stores data as schema-free JSON or, to phrase it better, flexible data structures. A unique ‘_id references each document,’ which makes for a fast lookup. It utilizes a B-tree structure for efficient querying and indexing. If a document is fetched, CouchDB retrieves it directly from the disk and services it through the HTTP API. Moreover, CouchDB uses caching to improve the read performance. This system supports high availability and scalability for various applications.
32. What are the security functionalities provided in CouchDB?
Ans:
- CouchDB provides several security functionalities to protect data and access controls. It implements user authentications, such as basic authentication and cookie-based sessions,
- Access control lists, or ACLs, allow the administrator to set certain types of access for different users or roles. Certificate and SSL/TLS encryption can be used to secure data between clients and the server.
- Moreover, CouchDB supports CouchDB supports documents with fine-grained read-and-write controls over specific documents. On a higher level, such features provide data security and integrity.
33. What kind of interaction does CouchDB have with web applications?
Ans:
- CouchDB interacts with web applications through its RESTful HTTP API. This approach’s major benefit is that developers can perform CRUD operations using standard HTTP methods.
- Since this API accepts data in JSON format, it can easily allow data sharing from the database into applications. This increases CouchDB’s capabilities to create dynamic applications by using JavaScript functions for data processing within CouchDB.
- Libraries and frameworks such as PouchDB allow seamless interaction between client-side applications and CouchDB.
34. What is the purpose of the CouchDB command-line interface?
Ans:
The CouchDB command-line interface is a powerful tool for managing and administering CouchDB databases. It enables to creation of databases, having documents within this, and performing management using settings for configuration. This means that direct interaction with the CouchDB server through CLI allows automating and scripting routine tasks. Apart from the above, it will enable monitoring of the server performance and the use of resources.
35. How does CouchDB handle large data?
Ans:
CouchDB deals with large data by adopting a distributed architecture that provides horizontal scalability. In this case, data is fragmented into VBuckets to distribute across several nodes effectively. This design supports load balancing, so there are no node bottlenecks while accessing the data. Indexing in CouchDB increases query performance for big datasets by evaluating results beforehand. Incremental indexing is also supported, so updates can be done without rebuilding indexes entirely. Summarily, these features make CouchDB viable with huge data volumes.
36. What is the CouchDB replication protocol used for?
Ans:
- This replication protocol is used for synchronizing various instances of CouchDB and supports one-way and two-way replication, thus helping distribute data across different nodes or locations.
- All changes resulting from updates in one database get reflected in others, maintaining consistency between the data.
- The data can be replicated continuously or scheduled according to need, giving flexibility in managing data.
- In addition, the protocol has built-in mechanisms for conflict detection and resolution to manage conflict effectively. In general, replication serves data availability redundancy.
37. How does CouchDB implement authentication and authorization?
Ans:
- CouchDB can authenticate a user through basic authentication or cookie-based sessions. Users must present a valid credentials database, which prohibits unlawful invasion.
- Authorization maintains the access control lists that contain database and document-level permissions for different users or roles. That way, it is possible to have very fine-grained permissions controlling who can read, write, or modify an exact document.
- In addition, CouchDB supports external authentication mechanisms such as OAuth, which adds more security features. These features ensure overall robustness regarding user management and data protection.
38. How do CouchDB synchronous and asynchronous replication differ?
Ans:
Synchronous replication in CouchDB- when changes send an immediate ripple throughout all replicas- with the penalty being very high for the delay so that data may be effectively consistent only where all applications need real-time data accuracy. Asynchronous replication will allow a change to be propagated to all replicas with some delay, which could be less expensive in performance but risks minor temporary inconsistencies. Asynchronous replication is useful when the application is better tolerated to less strict consistency.
39. How does CouchDB approach database backups?
Ans:
CouchDB approaches database backups mainly by replication and utilization of continuous backup strategies. DBs can be copied to another CouchDB instance, so now data is duplicated and thus safe. Snapshot tools can be used to build point-in-time backups of the database files. As a final step, documents can also be exported in JSON format from CouchDB; thus, backups can be taken manually.
40. Why is JSON so important to CouchDB?
Ans:
- JSON is the base of the data format used by CouchDB. It allows for quite flexible, loosely coupled, and schema-free application of data storage.
- The format supports complex data structures, including nested objects and arrays, to provide flexibility for diverse application needs.
- Because it will fit so well with modern Web technologies and programming languages, it is relatively easy to handle data manipulation when using JSON.
- N1QL further enables some queries on JSON documents in CouchDB, making it much easier to use.

Get JOB CouchDB Training for Beginners By MNC Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
41. How are views defined and queried in CouchDB?
Ans:
In CouchDB, views are defined inside design documents using JavaScript functions based on mapping and reducing data. The purpose of the Map function is to process each document and emit key-value pairs; the Reduce function, which may or may not be provided, then accumulates those results. Once defined, views can be queried by issuing requests with the CouchDB HTTP API.
42. How to monitor CouchDB performance?
Ans:
CouchDB has several tools to monitor performance, such as the Fauxton web interface. Here, an overview of the database status, active tasks, and request logs is provided. Additionally, CouchDB offers logging that can be configured to gather fine-grained operational metrics. Out-of-the-box monitoring tools like Prometheus and Grafana may be incorporated for more comprehensive analytics and visualization. Tools are required to monitor metrics like response times, document accesses per second, etc.
43. Limitation of CouchDB
Ans:
- CouchDB has some weaknesses, including difficulties when complex queries that require joins or aggregation are implemented.
- Such queries will be less efficient in CouchDB compared to what they are in SQL databases.
- Its eventual consistency model could not fit applications requiring strict data consistency in real-time.
- Although CouchDB does well with large datasets, it gets ugly when dealing with the most extreme document sizes. This can indeed bring about performance degradation.
44. What major differences does CouchDB offer over traditional SQL databases?
Ans:
- The main difference between CouchDB and the usual SQL databases is its schema-free, document-oriented data model compared to SQL databases’ structured tables.
- Whereas SQL databases depend on ACID transactions for guaranteed data integrity, CouchDB follows an eventual consistency model that favors availability and partition tolerance.
- Compared with SQL databases, CouchDB queries use N1QL with JSON data. While SQL databases mostly use structured query language, CouchDB is a highly flexible and scalable option, especially for unstructured data.
45. What can be done to enhance the performance of CouchDB?
Ans:
There are several aspects by which a person could optimize CouchDB’s performance. Proper indexing would make queries faster. Updating views along with frequent maintenance would make quick responses to queries possible. Implementing in-memory caches during data retrieval reduces disk I/O. Horizontal scaling using the addition of nodes distributes the load and improves overall throughput. The system performance can be monitored, and configurations can be adjusted based on usage patterns to optimize resource utilization.
46. What is CouchDB’s role in microservices architecture?
Ans:
The importance of CouchDB in microservices is a flexible, scalable, and distributed data store. Such an approach, with its schema-free JSON document model, allows for evolving microservices without stringent constraints on their data structure. Therefore, information could be kept in sync across different microservices using the capabilities in CouchDB, such as replication for distributed data management.
47. How does CouchDB handle schema evolution?
Ans:
Because CouchDB is a schema-free database, it inherently ignores all issues related to schema evolution. Developers modify the document structures without downtime; new fields can be added to documents without disturbing the already existing records due to changes in the application requirement; since the documents are stored as JSON, there can exist varying structures within the same database, and due to this flexibility, things become easy.
48. What are some of the problems of scaling CouchDB?
Ans:
- Scaling an instance of CouchDB creates multiple challenges. Data distribution and replication are also concerns.
- Balancing data distribution among nodes is critical; uneven data distribution would lead to bottlenecks in performance.
- Further, the complexity of managing conflicts between nodes regarding replication generally increases the challenge of achieving data consistency due to the multi-master architecture.
- Also need good operational oversight to monitor and maintain node health for various nodes.
49. How can CouchDB be used in a distributed system?
Ans:
- CouchDB employs replication and synching built into the system to use it in distributed systems effectively.
- VBuckets enable the distribution of data across nodes, which is helpful when balancing loads and fault tolerance is critical. The replication protocol will synchronize data one way and bi-directionally in different locations, ensuring data integrity.
- In addition, CouchDB ensures reliability because of its use of MVCC in handling conflicts in a collaborative environment. Its design also makes it schema-less, allowing it to accommodate a myriad of data structures across different nodes in the distributed system.
50. How does network latency impact the performance of CouchDB?
Ans:
- Network latency is a determining factor in CouchDB’s performance when reading data from different nodes.
- Higher latency means that queries take too long to execute and return the data, impeding responsiveness. Latency in replication can also slow synchronization and even cause stale reads.
- There are applications that may contain real-time information processing, and variability in those applications can occur based on the timing of the network delay.
51. How does CouchDB permit integration with other data systems?
Ans:
CouchDB permits integration with other data systems through a RESTful HTTP API that enables standard CRUD operations via HTTP requests. It can interact with different programming languages and frameworks, making it adaptable to a different application. Moreover, CouchDB enables data replication to and from other CouchDB instances, thus enabling data sharing between systems. Data processing and streaming can also be made by integrating tools like Apache Kafka and ETL platforms.
52. What are the important considerations for deploying CouchDB in production?
Ans:
It involves key matters when putting CouchDB into production: having the right amount of hardware placed to support the projected loads and performance requirements. Essential settings regarding memory, disk I/O, and other things should be configured appropriately to give the best possible performance. Security in the form of user authentication and encryption of sensitive information will be implemented.
53. Can CouchDB be used in real-time applications?
Ans:
- CouchDB can be used in real-time applications by utilizing its ‘_changes’ feed, which offers continuous document updates.
- This feed application can subscribe to enable immediate reaction to changes in the database. It also increases data availability and responsiveness by making data replication across nodes.
- It supports even real-time functions in truly disconnected environments through offline capabilities by synchronizing with PouchDB. Its RESTful API allows fast access to data, fast enough for user interaction.
54. What do triggers serve in CouchDB?
Ans:
- Triggers exist in traditional SQL databases; however, they do not exist in CouchDB but can be equivalent in using the ‘_changes’ feed and external processing.
- That is, applications would listen to changes in the database and take action based on those changes. For example, adding or updating a document can cause an external service to act on that document.
- Such a system permits flexible responses to data changes without placing concrete constraints on the database. Design documents can also be containers for JavaScript functions to manage complex logic.
55. How does CouchDB handle error management and recovery?
Ans:
CouchDB tracks errors through advanced logging mechanisms, so that all the details of the errors encountered are taken for operations. Since replication is a characteristic of CouchDB in case of failure, data will be available from replicas also, hence availability and data consistency will be guaranteed. This MVCC model also ensures that no data loss occurs which may occur due to concurrent writes since different versions of documents will be preserved.
56. What are some best practices while designing CouchDB schemas?
Ans:
Best practices in designing CouchDB schemas include having an elastic, schema-less schema to accommodate changing data structures. Documents mean meaningful ID of documents, making retrieval and management easy. Withholding data related to each other within individual documents further gives less complex join. Furthermore, implementing Views for indexing common query patterns also improves the performance.
57. How does CouchDB model data when compared to relational databases?
Ans:
- Data is modeled as a JSON format document in CouchDB. It can, therefore, be structured flexibly and nested. Relational databases organize data into fixed-schema tables, which contrasts the former.
- The design allows CouchDB to maintain mixed document types within a database. Thus, CouchDB does not use foreign keys, and it manages relationships through embedding or referencing documents.
- Horizontal scaling for CouchDB is encouraged instead, while relational databases scale up vertically.
58. What does the _changes feed do in CouchDB?
Ans:
- The CouchDB’s ‘changes’ feed enables applications to receive a continuous stream of document changes; thus, applications can see all changes in real-time.
- It will monitor all modifications, including additions, deletions, and updates; thus, any database activity can be comfortably monitored.
- Applications can subscribe to this feed to react instantly to changes, thus enabling increased interaction. The feed supports filtering, allowing clients to receive only relevant updates based on specific criteria.
59. How does CouchDB handle document expiry and TTL?
Ans:
CouchDB manages its document expiration using the TTL feature, setting a particular time. If that time passes, the document gets automatically deleted from the database. At the time of creation of a document, it can be set with a TTL value; thus, when that time ends, the document becomes eligible to be removed in the next compaction. Therefore, this feature also helps in maintaining storage by removing old data.
60. How can CouchDB be used for IoT-related applications?
Ans:
IoT applications can utilize the full potential of CouchDB as it supports handling large amounts of unstructured data sourced from the devices. The schema-less design also enables flexible data modeling in terms of different formats that various devices use for reporting data. Replication capability will allow data to be synchronized with an edge device and central servers, allowing offline functionality. The ‘_changes’ feed also supports real-time updates, which may be used to observe the status of events associated with devices.

61. How does CouchDB support mobile application development?
Ans:
The synchronization feature also allows for the development of mobile applications. This means the mobile application will be available to access even when out of network and automatically synchronize with data once the device returns online. PouchDB is a JavaScript library that assists the mobile application in facilitating CouchDB interactions. Its local storage and replication features make it essential for enabling user experiences without jarring the smooth flow of data events, even in low-connectivity scenarios.
62. What does CouchDB do in the CMS?
Ans:
- CouchDB has become a good backend for content management systems because it can provide flexible and scalable content storage for different types of content content content.
- CouchDB’s no-schema nature allows the handling of multiple content formats, from text to images and metadata. The replication feature ensures the availability of the content across several nodes, thereby increasing performance.
- Besides that, CouchDB’s support for the ‘_changes’ feed allows one to maintain his content in real-time, updated across all his devices and user accounts. Built-in versioning also makes content revisions easy.
63. How can CouchDB be combined with data visualization tools?
Ans:
- CouchDB is combined with data visualization tools, using the RESTful API to give direct access to the database’s data.
- Tools like Grafana and Tableau support direct connections to CouchDB, which provides a good option for querying data for visualization and reporting purposes.
- Custom applications can be developed to fetch the data from CouchDB and use these data structures with a JavaScript library, such as D3.js or Chart.js.
- The flexibility of JSON data structures supports diversity in visualization formats and requirements. Views in CouchDB can be used to pre-aggregate data to make visualization efficient.
64. What are the choices to import data into CouchDB?
Ans:
Many options for transferring data into CouchDB, ranging from using ETL (Extract, Transform, Load) tools to direct uploads through the HTTP API. For example, the ETL tools can extract data from relational or NoSQL databases and then transform it into a JSON format before loading it into CouchDB. The migration process can also be made much easier, especially with complex transformations, by writing custom scripts with a language like Python or Node.js.
65. What are the implications for performance when using CouchDB with large JSON documents?
Ans:
CouchDB implies performance considerations when using large JSON documents regarding the time to store and retrieve. Large documents typically incur increased amounts of time that might take for read-and-write operations, which affects overall responsiveness. Indexing also becomes rather resource-intensive when dealing with large meat view builds that take a long time. Network latency can easily arise when dealing with large documents, thereby affecting user experience.
66. How is multi-tenancy supported in CouchDB?
Ans:
- CouchDB supports multi-tenancy by creating separate databases for different tenants or clients, where the data is isolated and secured.
- Each client can have their database with customized ACLs that may be used to handle the appropriate permissions.
- Even CouchDB’s schema-free nature permits different tenants to have varying numbers of data structures without conflict. Additionally, features of CouchDB’s replication make it possible to synchronize data between tenant databases and central instances when needed.
67. What is the role of CouchDB in cloud computing environments?
Ans:
- CouchDB is important in the cloud computing environment because it allows for a scalable and distributed data solution to be applied across cloud instances.
- Replication allows the network to be geographically dispersed and synchronized to enhance availability and disaster recovery.
- The lack of schema allows cloud applications to mold to diverse data types with different workloads.
- Through its RESTful interface, it is easy to integrate with services and applications designed for clouds, making data access and management pretty easy and fluid.
68. How does CouchDB handle cross-origin resource sharing (CORS)?
Ans:
- CouchDB handles cross-origin resource sharing, or CORS, by allowing the configuration of CORS settings on the server. This allows CouchDB to decide which domains can access its resources using the HTTP API.
- For developers, enabling CORS can be done by changing the configuration file or using the HTTP headers to decide access.
- CORS Settings Features allows to specify which domains, methods, and headers can be allowed to give secure, controlled access. This feature is especially useful for web applications interacting with CouchDB from various domains.
69. What does it mean to use CouchDB in a GDPR-compliant architecture?
Ans:
All personally identifiable data will be treated in accordance with data protection laws. These include suitable access controls to ensure that no unauthorized personnel access the sensitive information stored on CouchDB. Data minimization should be followed, ensuring thatby collecting and holding only relevant personal information. Other functionalities, including document versioning and facilities for deleting documents, assist organizations in fulfilling data erasure requests.
70. How does CouchDB handle updates and deletes?
Ans:
There is an update with a versioning on the ‘_rev’ field, where it can track different revisions of documents. Updating a document creates a new revision while retaining the previous one that may eventually be needed for conflict resolution. Deletes are handled by marking documents as deleted, keeping the associated ‘_rev’ information should they need to refer to it again. In this way, documents that have been deleted are only immediately and permanently discarded once compilations occur, and thus, recoverable if needed.
71. What are the advantages of using CouchDB for real-time data processing?
Ans:
These make CouchDB a good choice for real-time data processing—mainly its _changes feed, which immediately notifies of changes to any document within the database. This can make an application interact immediately with database updates. The lack of a schema enables support for various data types, making flexible ingestion possible. Moreover, the replication capabilities will ensure that the data can be available across all distributed systems.
72. In what way does CouchDB apply to data warehousing?
Ans:
- CouchDB can be used in data warehousing as a storehouse for unstructured and semi-structured data. Because it is schemaless, it can accommodate very varied datasets, such as logs and event data.
- Data integration from multiple sources can be done seamlessly with CouchDB as it supports replication and synchronization.
- The views allow for querying and easy reporting on big data. In addition, CouchDB can be integrated with ETL tools to perform data transformation and loading.
73. What is the role of the CouchDB ecosystem, including libraries and frameworks?
Ans:
- The CouchDB ecosystem is highly important for enhancing its functionality and usability. It consists of various libraries and frameworks that make integration and development easier.
- Many web and mobile applications have immense offline capabilities with PouchDB. Tools like Fauxton would provide a friendly interface to manage instances of CouchDB.
- Combined with data visualization libraries, it could provide better representation and analysis of the data.
74. How does CouchDB support localization and internationalization?
Ans:
CouchDB supports localization and internationalization through its flexible document structure, accommodating multi-lingual content. Applications manage different language versions of a document by storing language-specific fields in the same document. Using design documents can also allow for other views unique to a particular locale or language. Restful API will enable developers to implement, for example, language preferences in application logic.
75. What debugging tools does CouchDB have available for developers?
Ans:
Several tools are available for debugging CouchDB developers, including the Fauxton interface, built into the installation; this one includes a graphical overview of databases and documents. The logging feature captures detailed information about database operations. Tools like Curl and Postman may be used to test and debug HTTP requests to the CouchDB API. Debugging JavaScript views may be simplified using console logs in the design document.
76. How does CouchDB support versioned APIs?
Ans:
Versioned APIs in CouchDB can coexist through a RESTful architecture as the APIs may coexist in different versions. Since this strategy enforces the ability to roll out various features over time without compromising the validity of applications that depend on earlier versions, developers can have multiple endpoints for one unique API, following the variants in each. The clients could decide which version they want when requesting something and use a different API based on the required functionality.
77. What does it mean for a microservice architecture to use CouchDB?
Ans:
- With CouchDB, decentralization allows for the independent management of data for each service in a microservices architecture.
- Its schema-free design allows multiple data models and lets services grow freely without rigid constraints. Built-in replication means that when data is destroyed, it is backed up elsewhere in the system.
- Instead, its support for interoperation also allows for more simplicity in communication between services using a RESTful API. Otherwise, careful planning may be necessary to ensure data consistency across services.
78. How does one benchmark a performance in CouchDB?
Ans:
- Performance can be benchmarked on CouchDB using various tools and metrics, such as throughput, latency, and resource utilization. Tools such as Apache JMeter allow for the simulation of concurrent users to determine response times and throughput under load.
- Additionally, it can monitor some key metrics during the tests with proper monitoring tools, such as CPU usage, memory consumption, and disk I/O.
- Even the built-in statistics endpoint will help with database operations and request handling. Any benchmark should have diversified scenarios to achieve sound performance analysis.
79. What is the architectural difference between CouchDB and Couchbase?
Ans:
Other main differences in architectural approach and the features that distinguish CouchDB from Couchbase lie in that CouchDB is a document-oriented database where, while the focus is on data preservation and replication, it presents one node architecture that can be distributed. Couchbase is a non-relational document-oriented database that combines key-value storage and supports the implementation of built-in caching and high-performance querying.
80. How can machine learning applications be supported through CouchDB?
Ans:
- CouchDB can host the machine learning application and serve as a repository for the training dataset; it is useful for the versatile storage of structured and unstructured data.
- Its design does not need a schema, which makes it easier to change the format of the data and accommodates various types of data used in machine learning. The replication features make it convenient to synchronize and copy the training data in distributed systems to increase access to data.
- In addition, CouchDB is fully RESTful, thereby fitting nicely into machine learning frameworks and libraries.
81. What couchDB options exist for securing data at rest?
Ans:
Several ways exist to lock down CouchDB data at rest:
- Disk encryption.
- Encrypting information on physical drives.
- File system encryption tools can be configured to encrypt the CouchDB data directory.
It is also possible to utilize ACLs to control user permissions and ensure that sensitive information is accessed only by authorized personnel. Data should be encrypted, and regular backups should be considered to protect data stored and during transport. Security can also be achieved by installing a secure server environment and using firewalls.
82. What is CouchDB’s policy on high availability and failover?
Ans:
It then uses replication features to place the data in replicas on multiple nodes, providing high availability. Requests may then be redirected from the client to the replica nodes in the event of a node failure, thereby reducing the overall downtime. CouchDB supports master-master replication, which allows writes on all nodes and provides improved fault tolerance. Load balancing can then be supplied in continuous access using several nodes working together through clustering.
83. What metrics should be measured to determine CouchDB health metrics?
Ans:
- BeloCouchDB provides a few crucial metrics for CouchDB health monitoring: Request latency provides an idea of the time taken to process queries.
- Measuring the number of active connections is also pertinent to gauging the database’s load and capability. Memory consumption is also very important because overutilization generally leads to system performance degradation.
- Disk I/O rates reflect data about storage performance, and replication lag specifies the lag in synchronizing data among nodes. The number of document changes may also indicate active database usage.
84. How does CouchDB cope with heavy load?
Ans:
- CouchDB performs well in heavy-load situations due to its architecture built for scalability and concurrent access. The database employs An MVCC model that minimizes the conflicts that writing operations can cause and improves reading operations.
- Performance would depend on document size, query complexity, and hardware resources. Index strategies involving views and search indexes significantly improved response times.
- Monitoring and tuning server resources ensure that loads applied keep performance at its optimal level.
85. What does data sharding mean for CouchDB?
Ans:
Data sharding in CouchDB: The traditional data sitting on a single node for better performance and scalability. Horizontal scaling will help to deal with big sets and more traffic. However, it introduces complexity regarding handling data, planning carefully for distribution keys, and balancing loads; it complicates queries because data might need to be retrieved from several shards. Implement proper replication strategies on shards to maintain data consistency across all shards.
86. What is the user-defined function of CouchDB?
Ans:
- CouchDB supports user-defined functions using JavaScript, which allows developers to build their own custom functions for processing data.
- These UDFs can be applied on views when retrieving data for aggregation and transformation.
- Though CouchDB does not support server-side execution of UDFs like other databases, it supports client-side evaluation through design documents.
- This extensibility enables developers to build complex logic well-suited to specific application requirements. Furthermore, one should be careful while developing performance- and security-aware usage of UDFs.
87. What does community support refer to in CouchDB development?
Ans:
It is the project of CouchDB by community support that drives it forward: it provides resources, contributions, and feedback to ensure the continuation of the project. Open-source contributors help to upgrade the software by giving information about issues, applying patches, and developing new features. Community forums, mailing lists, and social media sites facilitate user collaboration. The documentation and tutorials produced by the community members can enhance user onboarding and troubleshooting.
88. How does CouchDB ensure consistency in a distributed environment?
Ans:
- CouchDB ensures consistency in a distributed environment by managing concurrent writes using the MVCC (Multi-Version Concurrency Control) model.
- A version of each document can be tracked to resolve potential conflicts without data loss.
- Mechanisms are devised to ensure that updates are forwarded across nodes to maintain data consistency.
- CouchDB also provides conflict resolution mechanisms in case applications need to decide how to resolve conflicts.
89. What are the environmental considerations for deploying CouchDB?
Ans:
End. Network configurations should be sufficient to offer very low latency and high throughput, particularly in distributed configurations. There also should be considerations for energy efficiency, mainly for cloud installations, due to the cost of resource consumption. There also should be taken safety precautions on data and compliance. Backup planning and disaster recovery are also important to prevent losing data.
90. How does CouchDB interact with message queues or event streaming platforms?
Ans:
CouchDB includes a RESTful API for queues and event streaming platforms, so applications can publish and subsequently consume events. Libraries or frameworks like Apache Kafka or RabbitMQ can ease communication between CouchDB and other systems. When data changes within CouchDB, it creates events and sends them to queues so they may follow real-time processing workflows. Queue messages can be used to update or insert into CouchDB.




