
Last updated on 09th Nov 2021| 5571
Couchbase Server offers robust solutions for high availability in data operations, both for reading and writing. The platform employs a distinctive feature set to ensure data resilience and performance. High availability in Couchbase is achieved through a combination of intra-cluster replication, index replication, and disaster recovery facilitated by cross datacenter replication (XDCR). This set of Couchbase Interview Questions is designed to provide a solid foundation for individuals preparing for interviews in the realm of Couchbase. Interviewers often begin with fundamental concepts and progressively delve deeper based on candidate responses. Our curated list includes top Couchbase Interview Questions, each accompanied by comprehensive answers. Whether you’re a fresher or an experienced professional, these questions cover a spectrum of topics, including scenario-based inquiries. This collection aims to equip you with the knowledge needed to excel in your Couchbase interviews.
1. What is Couchbase?
Ans:
Couchbase is the NoSQL database that provides high-performance, scalable, and flexible data management solutions. It is designed for both the traditional and cloud-native applications and supports the multiple data models, including the document, key-value, and graph.
2. What are the key features of Couchbase?
Ans:
The Key features of Couchbase include the multi-model data management, flexible indexing, powerful query capabilities, strong data durability, and robust security features. Additionally, Couchbase provides the support for distributed architectures, horizontal scalability, and high performance.
3. How does Couchbase differ from other NoSQL databases?
Ans:
- Couchbase differs from the other NoSQL databases in several ways, including multi-model data management capabilities, its flexible query language (N1QL), and its built-in caching layer (Couchbase Server).
- Additionally, The Couchbase provides a strong data durability and robust security features, making it a suitable choice for mission-critical applications.
4. Explain N1QL query language in Couchbase.
Ans:
N1QL is the query language for a Couchbase, which allows for flexible and powerful querying of data stored in the database. N1QL provides the familiar SQL-like syntax, making it simple for developers to learn, while also providing advanced features like join operations and secondary indexing.
5. What is Couchbase Server in Couchbase architecture?
Ans:
- The Couchbase Server is a core component of the Couchbase architecture, providing an underlying database management system.
- The Couchbase Server is responsible for storing and retrieving data, managing the indexes, and processing queries. Additionally, Couchbase Server provides the caching layer to improve performance, as well as the distributed architecture for scalability and high availability.
6. What is the Couchbase Data Model?
Ans:
- The Couchbase Data Model is the multi-model data management solution, which allows the developers to store and manage different types of data, including documents, key-value pairs, and graph data, within the same database.
- This flexible data model makes it simple to adapt to changing application requirements and provides the consistency of data management solutions across all the data types.
7.What is the document in Couchbase?
Ans:
A document in Couchbase is the unit of data that can be stored and retrieved in a database. Documents in the Couchbase are stored in the JSON format, which allows for flexible and dynamic data structures.
8. How does Couchbase ensure data durability?
Ans:
Couchbase ensures data durability through its use of a data replication, which provides the multiple copies of data stored across the multiple nodes in the cluster. In the event of node failure, the data is automatically recovered from one of the other replicas, ensuring that data is always available.
9. How does Couchbase support horizontal scalability?
Ans:
Couchbase supports horizontal scalability by allowing addition of new nodes to the cluster as the volume of data and the number of users increase. The Couchbase cluster automatically distributes data across the nodes, providing a scalable and highly available solution.
10. What is the Couchbase SDK in Couchbase architecture?
Ans:
- The Couchbase SDK provides the high-level API for accessing and manipulating data stored in a Couchbase database.
- The SDK abstracts the underlying database management system and provides the consistent programming interface across the multiple programming languages, making it simple to develop and deploy applications that use Couchbase.
11. Explain Couchbase caching layer.
Ans:
The Couchbase caching layer is the built-in component of a Couchbase Server that improves the performance of a database by caching frequently accessed data in memory. This reduces latency and I/O overhead associated with accessing the data from disk, improving an overall performance of the database.
12. What is Couchbase Server Architecture?
Ans:
- The Couchbase Server Architecture is the distributed architecture that provides a high performance, scalability, and high availability.
- The architecture is based on a cluster of nodes, where each node runs the copy of the Couchbase Server software, providing the highly available and scalable solution.
13. Difference between Couchbase and MongoDB.
Ans:
- Couchbase and MongoDB are both NoSQL databases, but there are some key differences between two. Couchbase provides the multi-model data management solution and has a built-in caching layer, while MongoDB is the document-oriented database that relies on the external caching layer.
- Additionally, Couchbase provides the flexible query language (N1QL) while MongoDB uses MongoDB Query Language.
14. How does Couchbase ensure data consistency?
Ans:
Couchbase ensures data consistency through its use of data replication and consistency protocols. The data is automatically synchronized between the replicas, and consistency protocols ensure that data is always up-to-date and consistent across clusters.
15. What is the Couchbase Cluster Manager in Couchbase architecture?
Ans:
- The Couchbase Cluster Manager is the component of Couchbase architecture that provides a centralized management and monitoring of the Couchbase cluster.
- The Cluster Manager provides the user-friendly interface for managing clusters, monitoring performance and resource utilization, and automating common administrative tasks.
16. What is Couchbase Eventing Service?
Ans:
- The Couchbase Eventing Service is the component of the Couchbase architecture that provides the serverless computing platform for processing data stored in the Couchbase database.
- The Eventing Service allows the developers to create and deploy event-driven functions that automatically process data as it is stored in a database, providing real-time processing capabilities.
17. How does Couchbase support global deployments?
Ans:
- Couchbase supports global deployments through the distributed architecture and cross-data center replication (XDCR) feature.
- XDCR allows for data to be replicated across multiple data centers, providing a highly available and resilient solution for global deployments. This ensures that data is always accessible, even in the event of data center failure.
18. Difference between Couchbase and Redis.
Ans:
| Feature | Couchbase | Redis | |
| Data Model |
Document-oriented |
Key-Value | |
| Query Language | N1QL (SQL-like query language) | No query language; simple commands | |
| Data Persistence | Yes, supports disk-based storage | Optional; can be configured for persistence | |
| Replication |
Multi-dimensional replication (XDCR) |
Master-slave replication |
19. What is Couchbase Data Management Service in Couchbase architecture?
Ans:
The Couchbase Data Management Service is the component of Couchbase architecture that provides a centralized management of the data stored in the Couchbase database. The Data Management Service provides functions like indexing, querying, and backup and restore, making it simple to manage and manipulate data stored in the database.
20. How does Couchbase handle security?
Ans:
- Couchbase handles the security through its support for a range of security features such as SSL encryption for data in transit, role-based access control for data access, and integration with the external authentication systems like LDAP and Active Directory.
- Additionally, Couchbase provides the secure mode that disables all the unsecured ports, ensuring that only secure connections can access the database.
21. Explain how Couchbase indexing works.
Ans:
- Couchbase indexing works by creating the secondary indexes on data stored in the database. The indexing process creates the mapping of the data that allows for an efficient querying and retrieval of data. Couchbase provides the two types of indexes: primary indexes and secondary indexes.
- Primary indexes are created automatically and provide the mapping of unique keys for each document in the database, while secondary indexes allow for more complex queries to be executed efficiently.
22. How does Couchbase support data partitioning and distribution?
Ans:
- Couchbase supports the data partitioning and distribution through its use of data partitioning mechanism called vBuckets. The vBuckets divide data into smaller, more manageable chunks that are distributed across nodes in the cluster.
- The vBuckets provide a way to scale the database horizontally, allowing for more nodes to be added as volume of data grows.
23. Explain Couchbase query language (N1QL).
Ans:
- N1QL (Non-first Normal Form Query Language) is the SQL-like query language for Couchbase that provides a flexible and powerful way to query and manipulate data stored in databases.
- N1QL supports a wide range of query operations, including select, join, and aggregate operations, making it simple to perform complex data analysis and manipulation tasks.
24. What are Couchbase Views in Couchbase architecture?
Ans:
- Couchbase Views are the feature in the Couchbase architecture that provides the way to create custom views of the data stored in the database.
- Views are created using the MapReduce functions, which process data and produce a view that can be queried using Couchbase query language (N1QL).
- Views provide the flexible and efficient way to perform ad-hoc analysis and reporting tasks on data stored in the database.
25. Difference between Couchbase Community Edition and Enterprise Edition.
Ans:
- The Couchbase Community Edition is the free and open-source version of the Couchbase database, while the Enterprise Edition provides additional features and capabilities for enterprise-level deployments.
- The Enterprise Edition includes features like cross-data center replication (XDCR), data tiering, and advanced security features, making it a more suitable choice for large-scale, mission-critical deployments.
26. How Couchbase handles data concurrency and conflicts?
Ans:
- Couchbase handles the data concurrency and conflicts through its use of versioning and conflict resolution mechanisms. Each document in the database has a version number, which is updated whenever a document is modified.
- In the event of conflicting updates, the conflict resolution mechanism determines which version of the document should be stored in the database, ensuring that data remains consistent and up-to-date.
27. Explain Couchbase memory architecture?
Ans:
- The Couchbase memory architecture consists of several components, including RAM and disk storage, the caching layer, and data structures used to store the data.
- The Couchbase database uses the combination of RAM and disk storage to provide the high-performance solution, with frequently accessed data stored in a caching layer for a fast retrieval.
- The data structures used in Couchbase memory architecture, like B-Trees and Hash Tables, are optimized for fast data access and retrieval.
28. What is Couchbase Analytics Service in Couchbase architecture?
Ans:
- The Couchbase Analytics Service is the component of the Couchbase architecture that provides the way to perform complex analytics on data stored in the database.
- The Analytics Service provides the SQL-like query language (CBQL) that allows for the ad-hoc analysis and reporting tasks to be performed efficiently on the large datasets.
- The Analytics Service is designed to work in parallel across multiple nodes in the Couchbase cluster, providing the highly scalable and performant solution for big data analytics.
29. Difference between Couchbase and MongoDB.
Ans:
- Couchbase and MongoDB are both NoSQL databases, but there are some key differences between two. Couchbase provides the multi-model data management solution and has a built-in caching layer.
- While MongoDB is the document-oriented database that focuses on document storage and retrieval. Additionally, Couchbase provides the flexible query language (N1QL) while MongoDB uses MongoDB Query Language (MQL).
30. How does Couchbase handle data durability and availability?
Ans:
Couchbase handles the data durability and availability through its use of data replication and failover mechanisms. The Couchbase database replicates data across the multiple nodes in the cluster, providing a highly available and resilient solution.
In the event of a node failure, the failover mechanism automatically transfers ownership of data to another node, ensuring that data is always accessible.
31. Explain Couchbase Eventing Service and its use cases.
Ans:
- The Couchbase Eventing Service is the feature in the Couchbase architecture that allows for real-time processing of data stored in databases.
- The Eventing Service uses functions written in JavaScript to process data changes, trigger actions, and perform data transformations.
- The Eventing Service is useful for a range of use cases, including real-time analytics, data enrichment, and triggering automated workflow processes.

Learn Advanced Couchbase Certification Training Course to Build Your Skills
Weekday / Weekend BatchesSee Batch Details32. How does Couchbase handle data scaling?
Ans:
- Couchbase handles the data scaling through its use of data partitioning, data replication, and failover mechanisms.
- The data partitioning mechanism, vBuckets, allows for data to be divided into smaller, more manageable chunks that can be distributed across the multiple nodes in the cluster.
- The data replication mechanism ensures that data is always available, even in the event of a node failure, while the failover mechanism automatically transfers ownership of data to another node in the event of a failure.
33. Explain Couchbase backup and restore process.
Ans:
- The Couchbase backup and restore process allows for data stored in the database to be backed up to the persistent storage location, and then restored in the event of disaster or data loss. The backup process can be performed using Couchbase Management Console or through the Couchbase REST API.
- The restore process involves restoring the backed-up data to the new Couchbase cluster, ensuring that data is available and consistent.
34. How does Couchbase handle data consistency?
Ans:
- Couchbase handles the data consistency through its use of data replication and versioning mechanisms.
- The data replication mechanism ensures that data is replicated across the multiple nodes in the cluster, providing a highly available and resilient solution.
- The versioning mechanism ensures that every document in the database has a unique version number, which is updated whenever a document is modified.
- In the event of conflicting updates, the conflict resolution mechanism determines which version of a document should be stored in a database, ensuring that data remains consistent and up-to-date.
35. Can Couchbase be used for real-time data processing?
Ans:
Yes, Couchbase supports the real-time data processing through its Eventing Service, which enables an event-driven processing of data in response to changes in the data stored in the Couchbase.
36. Does Couchbase support data modeling and indexing?
Ans:
Yes, Couchbase provides robust data modeling and indexing capabilities, allowing for an efficient querying and retrieval of data. This includes the ability to define the secondary indexes on data, allowing for the complex querying of JSON data stored in Couchbase.
37. Is Couchbase an open source software?
Ans:
Couchbase can be perceived as the open source software delivered under the Apache 2.0 permit with the endeavor and network version. Couchbase is an appropriately diverse NoSQL record arranged in the database software bundle that is progressed for the aggregate applications and open-source software.
38. What is Couchbase Server?
Ans:
- Couchbase server is an easy, fast, elastic NoSQL database. It is also known as a Membase, distributed, multi-model NoSQL file oriented database software package that is advanced for the collective applications.
- It is an open-source, document-oriented database that provides high-performance, scalability, and flexibility.
- Couchbase is particularly well-suited for applications that require real-time data updates and low-latency access to information.
39. Distinguish between CouchDB and Couchbase server.
Ans:
- CouchDB: Apache CouchDB is a fit for putting away the JSON records and furthermore gives office to connect the non-JSON documents to those documents.
- Couchbase server: Couchbase server is fit for putting away certifications and key-values, subsequently, it will have option to store double data or some other sort of data and furthermore JSON archives. The couchbase server takes assistance from the Memcached paired convention for key-esteem functionalities and REST API’s SQL and view inquiries.
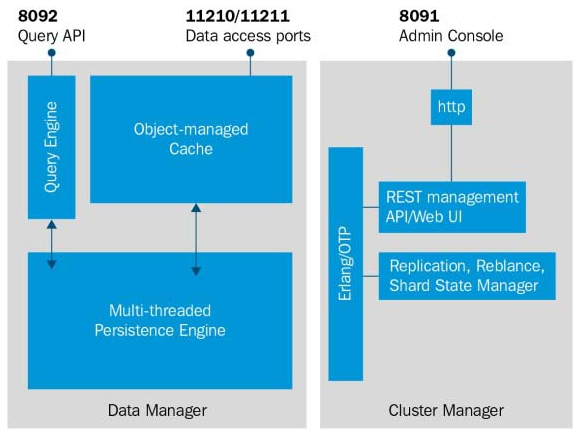
40. How many functional blocks are involved in Couchbase server?
Ans:
- Data Manager
- Cluster Manager
There are the two different functional blocks of Couchbase server and are
41. What is Data Manager?
Ans:
- Data Manager is responsible for the storing and extracting the data from applications in answer to data processing requirements.
- Data Manager will disclose 2 “memcapable” docks to set of connections.
- 1 port guides non-vBucket aware client libraries and the another one will guide to vBucket aware client libraries. The most of the Data manager code is written in C and C++ programming languages.
42. What are Cluster Managers?
Ans:
Cluster manager is made to look after arrangement plus the performance of all nodes in couchbase server cluster. The manager’s code will run on each lump in the cluster and selects a one node for aggregation. Most Cluster Manager code is written in Erlang/OTP.
43. What is vBucket?
Ans:
Vbucket is one of the methods of legitimately dividing data as a result of this nature, it can be appropriate everywhere on hubs in the group. Each couchbase kind basin that gets created in the group is consequently separated into a static arrangement of cuts, later guided to the singular servers. They are utilized to designate the data adequately alongside all through a bunch.
44. What are the 4 subsystems which functions on every node?
Ans:
- Pulses: Watchdog develops the regularly exchange a few words with presently designated cluster head to offer wellbeing revisions.
- Progression Monitor: This is a subsystem to monitor on carrying out of limited information executive, resuming the unsuccessful procedures as needed and contributing condition data to pulsing pieces.
- Pattern Manager: It is known that each node in the cluster has a pattern. This subsystem will receive, monitor and process the local configuration. Example: vBucket map, intention map, etc.
- Worldwide Singleton Supervisor: This is of subsystems and its task is to select a cluster head if previously voted head dies and monitoring “per-cluster” carries if a neighboring lump is present chief.
45. What does vBucket Map represent?
Ans:
- The vBucket map is responsible for representing the state of the cluster once a currently running rebalance operation completes.
- The process called Rebalance Orchestrator correlates target current maps to conclude which movement Tap Streams to create and administer.
- The operation of the Rebalance will get exhaustive when the current and Target vBucket Maps are alike.
46. What are the TCP ports used to listen to requests?
Ans:
- Port 11210: It is the port which is openly accessible to clients implementing version 2.0 of memcapable API. Those are “vBucket aware” clients and are depending on a hashing algorithm to map keys to one of the suitable numbers of “vBuckets”. The vBuckets later will get mapped to the server, providing the layer of indirection enabling vibrant cluster rebalancing, non-disruptive cluster expansion or contraction, replication and failover.
- Port 11211: The usual Memcached port number processes are requests from clients guiding version 1.0 of memcapable API requirement. Those clients will be depending on the consistent hashing algorithm to map keys openly to the servers in the variable-length server catalog.
The port numbers are configurable. The default ports are as below:
47. What is the importance of creating a Data Bucket?
Ans:
- It is important to create the Data Bucket since the couchbase server stores data in Data Buckets. The Default bucket is created when couchbase server is installed.
- The capacity of the data bucket to store data is up to 20MB. If required, additional data buckets can be added.
- The bucket creation will have the limit when there is no sufficient space in the RAM. Ex: limit the RAM/ Quota usage for a default bucket to 100 MB.
48. Explain data access model in Couchbase.
Ans:
- Couchbase supports the key-value and N1QL data access concepts. The key-value structure allows the users to access data by using a unique key, whereas the N1QL (pronounced “nickel”) query language allows the users to run ad hoc queries on the JSON documents.
49. How does indexing work in Couchbase?
Ans:
Couchbase makes the optimal use of secondary indexes to facilitate N1QL queries. These indexes can be created based on a certain document field, allowing for a faster query execution. Depending on the query requirements, users can create different sorts of indexes, like simple, composite, and array indexes.
50. Explain bucket concept in Couchbase.
Ans:
In Couchbase, a bucket is the logical container that holds data. In basic relational databases, it is similar to the database. Every bucket can have its own set of configuration options, such as data replication factor, memory quota, and eviction policies.
51. How does data eviction work in Couchbase?
Ans:
To manage data in-memory, Couchbase uses a variety of eviction policies. When memory quota is reached, the system can evict data using the Least Recently Used (LRU), Full Eviction, or Value Eviction rules, ensuring that only the most appropriate data is kept in memory.
52. What is Couchbase Administrator?
Ans:
The Couchbase Administrator is in charge of managing and maintaining the Couchbase clusters, as well as guaranteeing the high availability, monitoring performance, and performing the administrative activities like backup, recovery, and security configuration.
53. Explain rebalancing works in Couchbase.
Ans:
When adding or removing the nodes from a Couchbase cluster, the process of distributing data and cluster resources is referred to as a rebalancing. This guarantees that data is distributed equally and that cluster maintains its performance and availability.
54. What is a Memcached bucket in Couchbase?
Ans:
The Memcached bucket is used to provide high-performance and low-latency access to the simple key-value data. It has an appropriate interface with the Memcached protocol, which makes it useful for caching.
55. Explain Views in Couchbase.
Ans:
Views are used in the Couchbase to generate and store pre-defined, indexed queries that can be later run for a data retrieval. Views are the built-in MapReduce functions, which enable the users to define maps and reduce operations on data in order to create indexes.
56. How does data consistency work in Couchbase?
Ans:
- Couchbase provides the configurable consistency levels, allowing to specify the level of consistency necessary for the given operation.
- Depending on application requirements, users can pick between the Eventual Consistency Read Own Writes and Strong Consistency to balance performance and data integrity.
57. What are security mechanisms in Couchbase?
Ans:
- To protect data and provide safe communication between the clients and servers, Couchbase includes security features like role-based access control, SSL encryption for data transmission, auditing, and IP filtering.
- Couchbase employs robust security mechanisms to protect data integrity and confidentiality.
- Authentication is ensured through methods such as username/password, LDAP, and Role-Based Access Control (RBAC).
- Encryption is implemented both in transit using SSL/TLS and at rest with Full Disk Encryption.
- Network security is maintained through configurable settings, permitting control over IP access.
58. How does Couchbase handle conflicts in document updates?
Ans:
For managing the conflicts during document updates, Couchbase uses the mechanism known as “Last Write Wins” (LWW). When multiple changes occur at the same time, updating with the most recent timestamp is considered to be correct, while others are handled as the conflicts.
59. What is a shared server and a dedicated server?
Ans:
- Organizations and businesses these days have the option to consider a server that is only dedicated to them. No other organization or the business shares the same. On the other hand, a shared server is distributed among the many businesses and it hosts a lot of businesses.
- The shared hosting has a low price for obvious reasons as compared to the dedicated server. Both have their own pros and cons associated with each other. For businesses with small data needs and basic applications, the shared server is a good option to be considered.
60. Do you think it’s vital to create a data bucket in a system? If so, why?
Ans:
- Yes, it is important. This is generally done because the server only prefers the data buckets when it comes to storing the data. When the server is installed, the default bucket gets created automatically.
- Organizing and storing data in a structured manner within a system is crucial for efficient data management, retrieval, and analysis.
- It enhances data security, scalability, and ensures consistency and integrity.
- A well-designed data storage system also promotes interoperability with other systems and applications, contributing to overall system performance.
61. What is the data manager in Couchbase Server?
Ans:
It is actually the functional block with some useful applications. Actually, it is responsible for the purpose of extracting, as well as storing data from the applications. There are certainly other important tasks which it performs and without making the impact on overall functionality of the software.
62. What is data Format in Couchbase server?
Ans:
- The most basic unit of data man manipulation in a Couchbase Server is a document.
- Documents get stored in JSON document format without any predefined schemas.
63. Name elements which are present in Couchbase Node.
Ans:
- Index Service
- Data Service
- Cluster Manager component
- Query Service
Every Couchbase Node contains four elements. The elements have been mentioned below point-wise.
64. What is the term data replication?
Ans:
Replication is the term that defines that the same type of data is present at multiple locations in the server. The same can put unnecessary burden on the performance and sometimes, it takes an additional cost for the organization.
65. What is Role-based access control authentication approach in Couchbase?
Ans:
Role-Based Access Control is capable enough of the ensuring cluster-resources to gbe exclusively accessed by a customer with suitable privileges. Talking about privileges, these are gathered in the Couchbase-defined groups. Each set or group is associated with the individual role. Users are ensured to assign one or many roles, and privileges are granted which are associated with every role.
66. What are the chances of Couchbase server failure?
Ans:
- Failure of power
- No maintenance of a server
- Presence of inauspicious data
- Improper Integration
- Hacking related issues
- Slow bandwidth
- Improper allocation of same
The chances for failure of the server are very less and the best thing is the overall number of failures reported about Couchbase are less. Some of the factors that can cause this issue are the listed below
67. What is Cross Datacenter Replication?
Ans:
- XDCR or Cross Datacenter Replication helps in providing the seamless mode to replicate data from one set to another. Cross Datacenter Replication involves replicating the active data to N+1 Server clusters, or even external apps like Spark, Elastic, Storm, and so forth.
- The sets are used for the various geographically diverse data centers. They are used either for bringing data closer to customers for a fast-paced data access or recovery of any disaster.
68. What are Couchbase Servers can easily satisfy?
Ans:
- There are certain needs Couchbase server can fulfill. The first is assuring a unified programming Interface can handle the queries and searches.
- In addition to this, mobile and Internet of Things demands can simply be fulfilled through this. Also,the various tasks like core database engine, analytics, SQL integrations, scale-out architecture, core database engine, as well as memory first architecture can simply be fulfilled.
69. How Couchbase Data Platforms are useful in building applications that are scalable?
Ans:
- It provides the uniform, simple, quick, and in fact powerful application development API that always makes sure of the applications that are good enough to be considered.
- As it can simply be deployed, the application needs can be fulfilled in the very short span of time. Intelligence can easily be added to the applications, time delays can be avoided and overall downtime can be reduced upto the great extent.
70. What are the capabilities of the core database engine?
Ans:
- There are certain abilities of the same which are more useful when it comes to managing the data of applications. In addition to this, it is also good enough to be trusted for document applications.
- The users can simply deploy its architecture anywhere they want. Other capabilities include the caching of data, data persistence, as well as a database management.
71. Is Couchbase amultiform NoSQL file oriented database software package?
Ans:
yes, Couchbase is the distributed multiform NoSQL file-oriented database software package. Couchbase is generally defined as open-source software that was released under the Apache license that consisted of community and enterprise editions.
72. What are the important advantages of including Couchbase and CouchDB into a single product?
Ans:
- First and foremost, Couchbase server happens to be a super-fast and highly scalable key-value store which is known for high-end scalability as well as performance.
- Secondly, CouchDB, on the contrary, is an excellent document database that comes with the powerful querying as well as indexing capabilities. So combining the aforementioned two would be beneficial.
- Not only will it create high-end performance, but also a highly elastic NoSQL database that will scale out linearly.
- At same time, it will also provide the indexing, querying as well as the other document-oriented features. Hence, including Couchbase and CouchDB will be beneficial.
73. What is the storage engine in Couchbase?
Ans:
- Couchbase Server features a design philosophy of tail-append storage. It is immune to data corruption, sudden power loss, or even OOM killers. Data happens to be written in a data file that enables Couchbase to mostly do sequential write-ups for an update. Also, it provides optimized and enhanced access patterns for a disk I/O.
74. What is sharding, and how does Couchbase implement it?
Ans:
- Sharding involves partitioning data across the multiple nodes to achieve horizontal scalability. Couchbase uses a mechanism called vBuckets (virtual buckets) to share data.
- Every vBucket is responsible for the subset of the data, and the distribution of the vBuckets across nodes allows for an effective data distribution and load balancing.
75. Explain Active-Active and Active-Passive replication in Couchbase.
Ans:
- Active-Active Replication: In Active-Active setup, multiple Couchbase clusters in the different locations actively serve read and write operations. This is suitable for scenarios where low-latency access is critical.
- Active-Passive Replication: In Active-Passive setup, one cluster actively serves read and write operations, while the others act as passive backups. This is often used for disaster recovery.
76. How does Couchbase handle schema evolution in JSON documents?
Ans:
Couchbase accommodates a schema evolution by allowing JSON documents within the bucket to have different structures. New fields can be added to the documents without affecting existing ones, providing the flexibility in data modeling.
77. Explain Couchbase Full-Text Search Service.
Ans:
The Couchbase Full-Text Search Service allows the developers to perform efficient text searches on JSON documents. It uses an indexing engine based on the open-source search engine, Elasticsearch, to provide fast and accurate search capabilities.
78. How does Couchbase handle conflicts in multi-node environments?
Ans:
Couchbase uses the conflict resolution mechanism to handle conflicts that may arise during a data replication. Developers can define the custom conflict resolution functions or let Couchbase automatically resolve the conflicts based on the predefined rules.
79. How does Couchbase maintain consistency in a distributed environment?
Ans:
- Couchbase uses the combination of techniques such as eventual consistency, vector clocks, and tunable consistency levels to maintain consistency in a distributed environment.
- Developers can choose a level of consistency that suits application requirements.
80. Explain Tunable Consistency in Couchbase.
Ans:
- Tunable Consistency in the Couchbase refers to the ability to configure a level of consistency for read and write operations.
- Developers can choose between the eventual consistency for higher availability and lower latency or strong consistency for situations where immediate and guaranteed consistency is crucial.
81. How does Couchbase handle data compression, and why is it important?
Ans:
Couchbase uses data compression to reduce storage and network overhead. By compressing the data before storing and transmitting it, Couchbase optimizes resource utilization and improves the overall performance.
82. What are the advantages of using the Couchbase Mobile solution?
Ans:
- Couchbase Mobile extends the Couchbase to mobile and edge devices. Advantages include the offline data access, synchronization capabilities, and a NoSQL database on the device.
- It’s beneficial for the applications that require seamless data access across the various platforms and network conditions.
83. Explain Couchbase Query Workbench.
Ans:
The Couchbase Query Workbench is the web-based tool that allows the developers to interactively query and explore data using N1QL. It provides a convenient interface for the testing and optimizing queries.
84. Explain Couchbase Analytics Service.
Ans:
The Couchbase Analytics Service is responsible for executing analytical queries on the large datasets. It allows the developers to perform complex analytical queries without impacting performance of the operational data store.
85. Describe Couchbase Multi-Dimensional Scaling (MDS) feature.
Ans:
- MDS in Couchbase allows separation of services (Data, Index, Query) onto the different nodes. This enables fine-tuning of resources based on the workload requirements.
- For example, if a system requires more query processing power, additional nodes with Query service can be added independently.
86. What is the Couchbase Auto-Compaction feature?
Ans:
- Auto-Compaction is the Couchbase feature that automatically manages removal of old or unused data files, optimizing disk space.
- It helps to prevent performance degradation and ensures efficient storage usage.
87. How does Couchbase handle security at network level?
Ans:
- Couchbase uses various security measures, including the encrypted communication (SSL/TLS) between nodes, client-to-server encryption, and network segmentation.
- This ensures that data transmission is secure and protected from unauthorized access.
88. What are the considerations for upgrading a Couchbase cluster to a new version?
Ans:
- Upgrading a Couchbase cluster involves careful planning to minimize downtime and potential issues.
- Considerations include the checking compatibility with existing applications, reviewing the release notes, and following recommended upgrade procedures provided by Couchbase.
89. Explain Couchbase Document TTL (Time-To-Live) and its use cases.
Ans:
Document TTL allows the developers to set a time limit on how long a document should be retained in a database. After the specified TTL expires, the document is automatically removed. This feature is useful for managing temporary or cached data.
90. Explain Couchbase Query Plan Cache and how it influences query performance.
Ans:
The Query Plan Cache stores execution plans for previously executed queries, allowing for a faster query execution. It helps reduce overhead of generating execution plans for frequently used queries, improving the overall system performance.
91. Explain Couchbase Query Memory Quota.
Ans:
The Query Memory Quota is the allocated memory for a Couchbase Query Service. It influences the amount of memory available for the query execution and can impact performance of the N1QL queries.




