
Last updated on 04th Jul 2020| 2670
These DATA WAREHOUSE Interview Questions have been designed specially to get you acquainted with the nature of questions you may encounter during your interview for the subject of DATA WAREHOUSE. As per my experience good interviewers hardly plan to ask any particular question during your interview, normally questions start with some basic concept of the subject and later they continue based on further discussion and what you answer.
1. In a data warehouse, what is an aggregate table?
Ans:
An aggregate table in a data warehouse is a precomputed summary table that contains aggregated data derived from one or more base tables. It is designed to enhance query performance by providing faster access to summarized information, reducing the need to compute aggregates on the fly. Aggregate tables store pre-aggregated measures like sums, averages, or counts, and are particularly useful in scenarios where complex and resource-intensive calculations are required for large datasets.
2. What does the term “metadata” mean in a data warehouse?
Ans:
In a data warehouse, metadata refers to data about the data. It includes information about the structure, definition, relationships, and attributes of the data stored in the warehouse. Metadata provides crucial details about how data is sourced, transformed, and loaded, facilitating data management, governance, and understanding. It plays a vital role in data lineage, data quality, and overall metadata management within the context of a data warehouse.
3. Define the data warehousing ER diagram.
Ans:
The Data Warehousing Entity-Relationship (ER) diagram is a graphical representation illustrating the entities, attributes, and relationships within a data warehouse. It typically includes entities such as facts (measurable business events), dimensions (contextual information), and relationships depicting how facts are associated with dimensions. The diagram visually outlines the structure of the data warehouse, aiding in the design and understanding of the underlying data model.
4. Identify the strategies the optimizer employed for the execution plan.
Ans:
The optimizer in a database system employs various strategies for generating an efficient execution plan for SQL queries. Some common strategies include cost-based optimization, rule-based optimization, index selection, join order optimization, and access path optimization. The goal is to determine the most efficient way to retrieve and process data based on factors like query complexity, available indexes, and statistical information about the data.
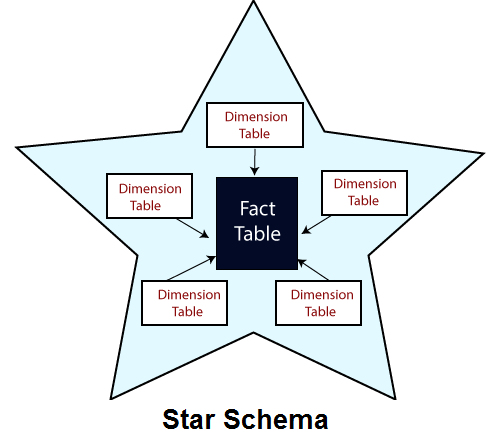
5. What does the term “Star Schema” mean to you?
Ans:
In data warehousing, a star schema is a type of database schema where a central fact table is connected to one or more dimension tables through foreign key relationships. The fact table contains quantitative data (metrics or measures), while dimension tables store descriptive information (attributes or context).
6. Which stages of a project do tests go through?
Ans:
| Testing Stage | Objective | Scope | |
| Unit Testing |
Verify individual units or components |
Smallest parts of the code in isolation | |
| Integration Testing | Ensure units work together correctly | Testing interactions between components. | |
| System Testing | Validate the entire system’s behavior | Testing the complete, integrated system. | |
| Acceptance Testing | Confirm system meets user requirements | Validate end-to-end functionality |
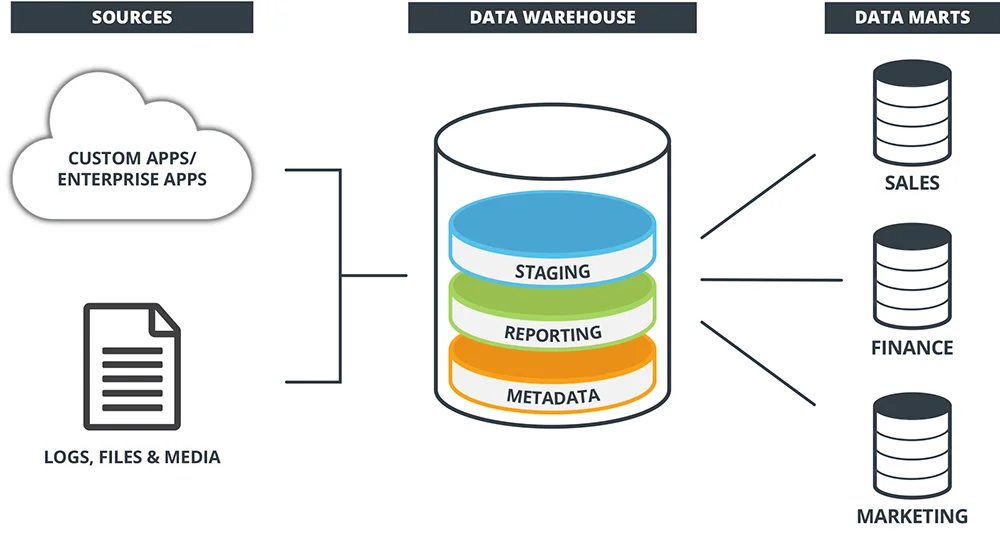
7. What does the term “data mart” mean to you?
Ans:
A data mart is a specialized subset of a data warehouse that focuses on specific business functions or user groups within an organization. It contains a curated collection of data relevant to the particular needs of a specific department or business unit, making it a more targeted and accessible repository compared to the broader scope of a data warehouse.
8. Give justifications for the division.
Ans:
Data mart division is justified to enhance performance, scalability, and user accessibility. By focusing on specific business areas, data marts can provide quicker access to relevant data for decision-makers, reduce data redundancy, and improve overall system efficiency. This division also allows for better customization and control over data, tailoring it to meet the unique requirements of different departments.
9. What roles do warehouse managers play?
Ans:
Warehouse managers in the context of data warehousing are responsible for overseeing the design, implementation, and maintenance of data warehouses. Their roles include data modeling, ETL (Extract, Transform, Load) process management, ensuring data quality and security, and collaborating with various stakeholders to meet organizational data needs effectively.
10. What does virtual data warehousing mean?
Ans:
Virtual data warehousing involves creating a logical view of data from multiple sources without physically consolidating it into a single repository. This approach allows organizations to access and analyze data in real-time without the need for extensive data movement or replication. It provides a flexible and agile solution for businesses dealing with diverse and distributed data sources.
11. What does hybrid SCD mean to you?
Ans:
Hybrid SCD refers to a combination of different techniques for managing changes to dimension data in a data warehouse. It typically involves using both Type 1 (overwrite) and Type 2 (historical) dimension handling methods, allowing for a balance between maintaining history and updating current values efficiently.
12. Describe a snapshot of data warehousing?
Ans:
Hybrid SCD refers to a combination of different techniques for managing changes to dimension data in a data warehouse. It typically involves using both Type 1 (overwrite) and Type 2 (historical) dimension handling methods, allowing for a balance between maintaining history and updating current values efficiently.
13. What kinds of tasks does OLAP perform?
Ans:
Hybrid SCD refers to a combination of different techniques for managing changes to dimension data in a data warehouse. It typically involves using both Type 1 (overwrite) and Type 2 (historical) dimension handling methods, allowing for a balance between maintaining history and updating current values efficiently.
14. What does ODS mean to you?
Ans:
Hybrid SCD refers to a combination of different techniques for managing changes to dimension data in a data warehouse. It typically involves using both Type 1 (overwrite) and Type 2 (historical) dimension handling methods, allowing for a balance between maintaining history and updating current values efficiently.
15. Give an explanation of summary data?
Ans:
Summary data refers to aggregated or condensed information derived from detailed, often raw, data. Instead of presenting individual transactional records, summary data provides a high-level overview or statistical representation of the underlying data. This condensed form is valuable for quick analysis, trend identification, and decision-making, as it distills complex information into more manageable and understandable insights.
16. What is meant by dimensional modelling?
Ans:
Dimensional modeling is a design concept used in data warehousing and business intelligence. It involves structuring databases in a way that optimizes the retrieval of information for analytical queries. Central to dimensional modeling are two types of tables: fact tables that contain quantitative data, and dimension tables that store descriptive information, creating a star or snowflake schema that simplifies complex queries and enhances performance.
17. List the three main purposes of dimensions?
Ans:
Filtering : Dimensions enable the filtering of data, allowing users to focus on specific subsets of information relevant to their analysis.
Grouping and Aggregation : Dimensions provide the basis for grouping and aggregating data, facilitating the generation of meaningful summaries and insights.
Navigation and Drill-Down : Dimensions allow users to navigate through data hierarchies and drill down to more detailed levels, supporting a comprehensive understanding of the information.
18. Describe the Galaxy Schema?
Ans:
A Galaxy Schema is a hybrid data warehouse schema that combines elements of both star and snowflake schemas. It allows for more flexibility in representing relationships between dimensions while maintaining some level of normalization. In a Galaxy Schema, certain dimension tables may be normalized, resembling a snowflake, while others remain denormalized, resembling a star schema. This design balances the advantages of both approaches, aiming for improved efficiency and maintainability.
19. Give three definitions for SCD?
Ans:
Filtering : Dimensions enable the filtering of data, allowing users to focus on specific subsets of information relevant to their analysis.
Grouping and Aggregation : Dimensions provide the basis for grouping and aggregating data, facilitating the generation of meaningful summaries and insights.
Navigation and Drill-Down : Dimensions allow users to navigate through data hierarchies and drill down to more detailed levels, supporting a comprehensive understanding of the information.
20. A dice operation has how many dimensions?
Ans:
The term “dice operation” is not standard terminology in mathematics or other fields. However, if you are referring to rolling a standard six-sided die, then the outcome is typically one of the numbers 1 through 6. In this context, you could say that the possible outcomes form a one-dimensional space.
21. Explain the main benefit of normalisation?
Ans:
The term “dice operation” is not standard terminology in mathematics or other fields. However, if you are referring to rolling a standard six-sided die, then the outcome is typically one of the numbers 1 through 6. In this context, you could say that the possible outcomes form a one-dimensional space.
22. What tasks must be completed by the query manager?
Ans:
The term “dice operation” is not standard terminology in mathematics or other fields. However, if you are referring to rolling a standard six-sided die, then the outcome is typically one of the numbers 1 through 6. In this context, you could say that the possible outcomes form a one-dimensional space.
23. What do you mean when you refer to “active data warehousing”?
Ans:
The term “dice operation” is not standard terminology in mathematics or other fields. However, if you are referring to rolling a standard six-sided die, then the outcome is typically one of the numbers 1 through 6. In this context, you could say that the possible outcomes form a one-dimensional space.
24. What distinguishes a data warehouse from a database?
Ans:
The term “dice operation” is not standard terminology in mathematics or other fields. However, if you are referring to rolling a standard six-sided die, then the outcome is typically one of the numbers 1 through 6. In this context, you could say that the possible outcomes form a one-dimensional space.
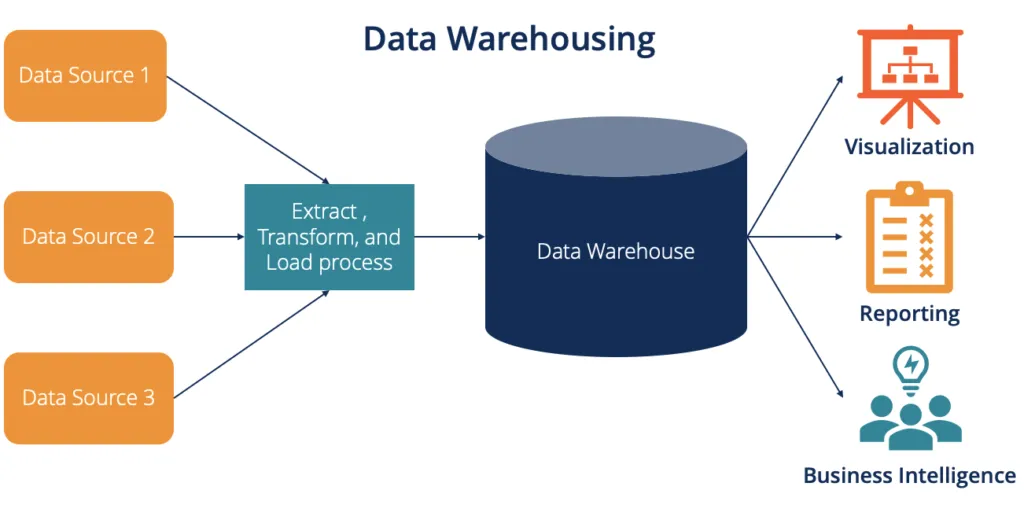
25. What are the key components of a data warehouse architecture?
Ans:
The key components of a data warehouse architecture include:
- Data Sources
- ETL (Extract, Transform, Load) Process
- Data Warehouse Database
- Metadata Repository
- OLAP (Online Analytical Processing) Engine
- Query and Reporting Tools
26. Describe the ETL process in the context of data warehousing.
Ans:
The ETL (Extract, Transform, Load) process in data warehousing involves extracting data from source systems, transforming it to meet the data warehouse’s requirements, and loading it into the data warehouse. It ensures data consistency, accuracy, and relevance by cleaning, aggregating, and integrating data from diverse sources.
27. What is dimensional modeling and how is it used in data warehousing?
Ans:
Dimensional modeling is a data modeling technique used in data warehousing to organize and structure data for efficient querying and reporting. It involves designing data models with “facts” (measurable business metrics) surrounded by “dimensions” (contextual information). This approach simplifies complex queries and enhances performance.
28. Explain the concept of a star schema and a snowflake schema?
Ans:
A star schema is a type of dimensional modeling where a central fact table is connected to multiple dimension tables. It resembles a star when visualized, with the fact table in the center and dimensions radiating outwards. In contrast, a snowflake schema extends the star schema by normalizing dimension tables, breaking them into multiple related tables, creating a structure that resembles a snowflake.
29. What is a fact table and how is it different from a dimension table?
Ans:
A fact table in a data warehouse is a table that contains quantitative data (facts) that can be analyzed. It typically includes numerical measures, metrics, or facts related to a business process. In contrast, a dimension table contains descriptive attributes or dimensions that provide context to the data in the fact table. Fact tables are often surrounded by dimension tables to enable multidimensional analysis.
30. What is a slowly changing dimension and how is it managed in a data warehouse?
Ans:
A slowly changing dimension (SCD) refers to a type of dimension in a data warehouse that evolves over time. Changes to the dimension data, such as updates, inserts, or deletes, are managed in a way that preserves historical information. SCDs are categorized into different types (Type 1, Type 2, Type 3) based on how they handle changes, and their management involves versioning or creating new records to maintain historical accuracy.
31. Explain the distinction between a data warehouse and a data mart?
Ans:
For business intelligence and reporting needs, structured data from multiple sources is centralised and kept in a data warehouse. In contrast, a data mart is a subset of a data warehouse that is tailored to particular user groups or business functions. A data mart is made to meet the needs of a specific team or department, whereas a data warehouse caters to the needs of the entire company.
32. What advantages come with utilising a data warehouse?
Ans:
A centralised view of organisational data, support for historical analysis, enhanced data quality and consistency, better decision-making through data analysis, and the capacity to combine and analyse data from various sources for thorough insights are just a few advantages of adopting a data warehouse.
33. Explain the concept of data granularity in the context of a data warehouse?
Ans:
Data granularity in a data warehouse refers to the level of detail or specificity in the data. It involves determining how finely data is stored or reported. Choosing the right granularity is crucial, as it affects the level of analysis that can be performed. Higher granularity provides more detailed information but may lead to increased storage requirements and processing complexity.
34. What is a surrogate key and why is it used in data warehousing?
Ans:
A surrogate key is a unique identifier assigned to a record in a database, typically used as the primary key. In data warehousing, surrogate keys are often artificially generated and have no business meaning. They are used to efficiently manage relationships between tables, particularly in cases where natural keys may change or when dealing with complex data integration scenarios.
35. How do you handle data quality issues in a data warehouse?
Ans:
Handling data quality issues in a data warehouse involves implementing data cleansing, validation, and transformation processes. This includes identifying and correcting errors, ensuring consistency across different data sources, and establishing data quality standards. Regular monitoring and maintenance are essential to address issues and maintain high data quality.

Learn On-Demand Data Warehousing Course from Real Time Experts
Weekday / Weekend BatchesSee Batch Details36. How does metadata function within a data warehouse?
Ans:
Data about data is referred to as metadata in a data warehouse. It contains details regarding the arrangement, interpretation, connections, and application of the data within the warehouse. Because it provides context and makes data discovery, integration, and analysis more efficient, metadata is essential to data governance, data lineage, and data management.
37. Explain the concept of data lineage?
Ans:
Data lineage refers to the tracking and visualization of the flow and transformation of data throughout its lifecycle within a system or across systems. It provides a detailed understanding of how data moves from its origin, through various processes and transformations, to its final destination. Data lineage is crucial for data governance, compliance, and troubleshooting as it helps organizations maintain transparency and accountability in their data processes.
38. What are the different types of indexing used in data warehouses?
Ans:
In data warehouses, common indexing types include bitmap indexing, B-tree indexing, and cluster indexing. Bitmap indexing is effective for low-cardinality columns, B-tree indexing is suitable for range queries, and cluster indexing organizes data physically to match the index, enhancing performance for certain types of queries.
39. How do you optimize query performance in a data warehouse?
Ans:
Query performance in a data warehouse can be optimized by designing efficient data models, using appropriate indexing strategies, partitioning large tables, denormalizing for specific queries, caching frequently accessed results, and employing query optimization techniques such as rewriting queries or using materialized views.
40. What is a star join and how does it impact query performance?
Ans:
A star join is a type of query in a data warehouse where a central fact table is joined with multiple dimension tables. While star joins are common in data warehousing, they can impact query performance, especially when involving large datasets. Proper indexing, denormalization, and optimization techniques are crucial to mitigate the performance impact of star joins.
41. Describe the role of aggregates in data warehousing.
Ans:
Aggregates in data warehousing are summarized or precomputed values derived from detailed data. They play a vital role in improving query performance by reducing the amount of data that needs to be processed. Aggregates are particularly useful for complex queries and reporting, as they provide quick access to summarized information without the need for extensive calculations.
42. What is a slowly changing dimension and how is it different from a rapidly changing dimension?
Ans:
A slowly changing dimension refers to a type of data in a data warehouse that changes infrequently, and historical records are maintained. In contrast, a rapidly changing dimension undergoes frequent changes, and historical data may not be preserved. SCDs are designed to capture and retain historical changes, whereas RCDs may only keep the current state of the data.
43. How do you design a data warehouse for scalability and performance?
Ans:
To design a data warehouse for scalability and performance, consider factors such as partitioning large tables, using distributed architectures, employing parallel processing, optimizing storage and indexing strategies, and leveraging cloud-based solutions. Horizontal and vertical scaling, along with efficient hardware and software configurations, contribute to a scalable and high-performance data warehouse.
44. Explain the concept of partitioning in a data warehouse?
Ans:
Partitioning in a data warehouse involves dividing large tables into smaller, more manageable pieces based on certain criteria (e.g., range, list, hash). This enhances query performance and facilitates data management. Partitioning can improve parallelism, reduce I/O, and optimize data retrieval by allowing the system to access only the relevant partitions rather than scanning the entire table.
45. What is the difference between a data warehouse and a data lake?
Ans:
A data warehouse is a structured, relational database optimized for query and analysis, typically containing historical data for business intelligence. In contrast, a data lake is a vast, flexible repository that can store structured and unstructured data in its raw format. While data warehouses emphasize structured data and predefined schemas, data lakes accommodate diverse data types and support exploratory analytics.
46. How do you handle historical data in a data warehouse?
Ans:
Historical data in a data warehouse is managed through the use of slowly changing dimensions (SCDs). Different SCD types, such as Type 1 (overwrite), Type 2 (add new version), and Type 3 (add new attribute), help track changes over time, preserving historical context for analysis.
47. In a data warehouse, what is the function of a conformed dimension?
Ans:
In a data warehouse, a conformed dimension serves to guarantee uniformity and consistency amongst various data marts and data warehouses. Standardised, shared dimensions known as “conformed dimensions” make it possible to integrate data seamlessly and accurately, enabling cross-functional and cross-departmental analysis.
48. Describe the idea of data scrubbing in relation to the ETL procedure?
Ans:
In the ETL (Extract, Transform, Load) process, data scrubbing entails enhancing the quality of data by cleaning and validating it. This includes handling missing values, correcting errors, and ensuring data accuracy and integrity before it is loaded into the data warehouse.
49. How do you handle incremental loads in a data warehouse?
Ans:
Incremental loads in a data warehouse involve updating only the new or modified data since the last ETL run. This process is more efficient than full loads, reducing processing time and resource utilization. Techniques like change data capture (CDC) or timestamp comparisons are commonly used for incremental loading.
50. What is the role of surrogate keys in a data warehouse?
Ans:
Surrogate keys in a data warehouse serve as unique identifiers for records, ensuring data integrity and simplifying data management. Unlike natural keys, surrogate keys have no business meaning and are solely used for internal referencing and linking across tables.
51. Describe the process of data extraction in ETL?
Ans:
Data extraction in ETL is the process of retrieving data from source systems, which can be databases, files, or external applications. This involves selecting relevant data based on defined criteria, transforming it into a suitable format, and loading it into the data warehouse for analysis and reporting.
52. What is a star schema and when is it appropriate to use?
Ans:
A star schema is a database design where a central fact table is connected to multiple dimension tables, forming a star-like structure. It is appropriate for scenarios where simplicity and query performance are critical, making it easier to navigate and analyze data. Star schemas are commonly used in data warehousing for business intelligence applications.
53. Explain the concept of slowly changing dimensions and provide examples?
Ans:
Slowly changing dimensions (SCDs) refer to the handling of historical changes in data over time in a data warehouse. There are three types: Type 1 (overwrite), Type 2 (add new row), and Type 3 (add new attribute). For example, in retail, if the price of a product changes, SCDs ensure that historical sales records reflect the correct price at the time of the sale.
54. What is the significance of data profiling in data warehousing?
Ans:
Data profiling in data warehousing is crucial as it involves analyzing and understanding the quality, structure, and content of data. It helps identify inconsistencies, missing values, and anomalies in data, ensuring data integrity and reliability for effective decision-making.
55. How do you handle slowly changing dimensions in ETL?
Ans:
Handling slowly changing dimensions in ETL involves detecting changes in source data and updating the data warehouse accordingly. Techniques include the use of effective dating, surrogate keys, and maintaining historical records to capture changes over time.

Advance your Career with Data Warehousing Training By World Class Faculty
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
56. What are the challenges of data warehousing in a cloud environment?
Ans:
Challenges of data warehousing in a cloud environment include data security concerns, integration complexities, performance issues, and ensuring compliance with regulations. Scalability and cost management are also critical considerations.
57. How is data security in a data warehouse ensured?
Ans:
In a data warehouse, enforcing encryption, access controls, and routine audits are necessary to ensure data security. Sensitive information can be protected by adhering to industry regulations, securing data during transmission, and storing data securely.
58. How does a data warehouse architect function?
Ans:
The general architecture of a data warehouse is the job of a data warehouse architect. They make sure the system satisfies business requirements and plan data models and integration procedures. They also work together with stakeholders to maximise scalability and performance.
59. Describe data mining as it relates to data warehousing.
Ans:
In data warehousing, data mining is the process of identifying patterns, trends, and connections within big datasets. It assists in revealing important information for making decisions, including market trends, abnormality detection, and customer behaviour analysis.
60. How are data transformations handled in ETL?
Ans:
In ETL (Extract, Transform, Load), data transformation is the process of transforming unprocessed source data into a data warehouse-ready format. It involves making sure the data adheres to the intended structure and quality standards by cleaning, filtering, and aggregating it.
61. What distinguishes a physical data warehouse from a logical data warehouse?
Ans:
Warehouse of Logical Data: It is a conceptual layer that makes the physical data sources underneath it invisible. Users can access and analyse data more easily and without having to worry about where it is stored because it offers a unified view of data from multiple sources. Physical Data Warehouse: This describes how the data warehouse is actually put into practice, including the hardware, software, storage, and particular setups needed for processing and storing data. It addresses the technical facets of retrieving and storing data.
62. Explain the steps involved in loading data into a data warehouse.
Ans:
Extraction : Information is taken out of external files, databases, and other source systems.
Transformation : Cleaning, validating, and transformation procedures are applied to data to
63. How do you choose between a normalized and denormalized data model for a data warehouse?
Ans:
Normalized Model : Suitable when maintaining data consistency and minimizing redundancy is crucial. It involves organizing data into separate related tables.
Denormalized Model : Preferred for read-heavy operations, where performance is a priority. It involves combining tables and storing redundant data for quicker query performance.
64. What is the purpose of a data warehouse surrogate key?
Ans:
- It’s a unique identifier for each record in a data warehouse table.
- Provides a stable reference to data, even when natural keys change.
- Simplifies data integration and ensures consistency in data warehousing environments.
65. How do you handle slowly changing dimensions in a star schema?
Ans:
Use techniques like Type 1 (overwrite), Type 2 (add new record), or Type 3 (maintain both old and new values) to handle changes in dimension attributes. Maintain historical data for accurate reporting and analysis.
66. Explain the concept of a junk dimension in data warehousing.
Ans:
- It’s a grouping of random, unrelated attributes into a single dimension table.
- Reduces the number of joins in queries and simplifies the schema.
- Typically contains low-cardinality and non-meaningful attributes.
67. How do you manage data consistency in a data warehouse?
Ans:
- Establish and enforce data quality standards during the ETL process.
- Use validation rules and data cleansing techniques.
- Implement error handling and logging mechanisms.
68. What is the role of OLAP in a data warehouse?
Ans:
- OLAP (Online Analytical Processing) enables multidimensional analysis of data.
- Facilitates complex querying and reporting for business intelligence.
- Supports activities like data slicing, dicing, drilling up or down for in-depth analysis.
69. How do you handle data lineage in a data warehouse environment?
Ans:
- Maintain metadata that tracks the flow of data from source to destination.
- Use data lineage tools to visualize and document the data movement process.
- Ensure transparency and traceability for data transformations.
70. What are the key considerations when designing a data warehouse for performance?
Ans:
- Optimize data storage and indexing for fast query performance.
- Use partitioning and indexing strategies on large tables.
- Implement proper caching mechanisms.
- Consider hardware scalability and parallel processing capabilities.
- Regularly analyze and optimize queries for efficiency.
- Utilize aggregate tables and materialized views for pre-aggregated data.
71. Explain the concept of data virtualization in a data warehouse.
Ans:
Data virtualization is the process of abstracting, managing, and presenting data from various sources without physical consolidation. In a data warehouse, it allows users to access and query distributed data as if it were a single, unified source, enhancing agility and reducing the need for physical data movement.
72. How do you handle data extraction from heterogeneous sources in ETL?
Ans:
ETL (Extract, Transform, Load) processes handle data extraction from heterogeneous sources by using connectors, APIs, or middleware to extract data in various formats. Transformation is then applied to standardize and cleanse the data before loading it into the data warehouse.
73. How does data cleansing fit into the ETL process?
Ans:
In ETL, data cleansing is the process of finding and fixing mistakes or inconsistencies in raw data. This avoids problems that could occur from using inconsistent or unreliable data by guaranteeing data accuracy, consistency, and reliability within the data warehouse.
74. Explain the distinction between a data mart and a data warehouse.
Ans:
A data warehouse is a centralised location where information from different sources is kept for analysis. A data mart, on the other hand, is a subset of a data warehouse that focuses on particular departments or business operations. Smaller and more focused than data warehouses are data marts.
75. What is the role of surrogate keys in data warehousing, and how are they generated?
Ans:
Surrogate keys are artificial primary keys assigned to each record in a data warehouse for uniquely identifying rows. They help in maintaining data integrity, facilitating easier updates, and avoiding the use of business keys that might change.
76. Explain the concept of data partitioning and its benefits in a data warehouse
Ans:
Data partitioning involves dividing large tables into smaller, more manageable pieces based on certain criteria (e.g., range or hash). It improves query performance by allowing the database engine to access only the relevant partitions instead of scanning the entire table.
77. How does data compression improve a data warehouse’s performance?
Ans:
Data compression lowers the amount of storage space needed in a warehouse for data, which enhances query performance and minimises I/O operations. It contributes to improving overall data warehouse efficiency and storage cost optimisation.
78. What are the difficulties involved in real-time data loading into a data warehouse?
Ans:
Managing high data velocity, maintaining data consistency, controlling latency, and resolving possible conflicts during concurrent updates are some of the difficulties in loading real-time data. Robust processes are necessary for real-time data loading in order to preserve accuracy and dependability.
79. How do you handle slowly changing dimensions in a snowflake schema?
Ans:
Slowly Changing Dimensions (SCDs) in a snowflake schema involve managing changes in dimension attributes over time. Techniques such as Type 1 (overwrite), Type 2 (add new version), or Type 3 (maintain multiple versions) are employed to handle these changes and maintain historical data accuracy.
80. What is the role of a metadata repository in a data warehouse environment?
Ans:
In a data warehouse environment, a metadata repository plays a crucial role in managing metadata, which is data about the data. It stores information about the structure, usage, and relationships of data within the data warehouse. This includes details about tables, columns, transformations, data sources, and more. The repository aids in data governance, providing a centralized location for metadata management, ensuring consistency, and facilitating effective data lineage tracking and impact analysis.
81. Explain the concept of a junk dimension and provide an example.
Ans:
A junk dimension is a technique in dimensional modeling where multiple low-cardinality attributes, which might not fit well in existing dimensions, are grouped together into a single dimension table. This helps in simplifying the data model by reducing the number of dimensions. For example, in retail, a “promotion” junk dimension could include attributes like promotion type, duration, and target audience, consolidating information that doesn’t warrant individual dimensions.
82. How do you address data latency issues in a data warehouse?
Ans:
Data latency issues in a data warehouse, referring to delays in data availability, can be addressed through various strategies. One approach is to implement real-time data integration processes to minimize the time between data generation and its availability in the warehouse. Additionally, partitioning data, using incremental loading, and optimizing ETL (Extract, Transform, Load) processes can help reduce latency and ensure timely data updates.
83. Describe the process of data aggregation in the context of a data warehouse.
Ans:
Data aggregation in a data warehouse involves combining and summarizing data from various sources or granularities to provide a more concise and informative view. This process typically includes functions such as sum, average, count, etc. Aggregated data is crucial for generating meaningful reports and supporting analytics by providing a higher-level perspective on the data.
84. What is the role of surrogate keys in maintaining referential integrity in a data warehouse?
Ans:
Surrogate keys play a vital role in maintaining referential integrity in a data warehouse. They are unique identifiers assigned to each record in a dimension table, facilitating relationships with fact tables. Surrogate keys shield the data warehouse from changes in the natural key of a dimension, ensuring stability and consistency in the relationships between tables.
85. How do you design a data warehouse to accommodate both structured and unstructured data?
Ans:
Designing a data warehouse to accommodate both structured and unstructured data involves using a hybrid approach. Structured data can be stored in traditional relational databases, while unstructured data, like documents or images, may be stored in NoSQL databases or object storage. Implementing a flexible schema design and utilizing data lakes can also help handle diverse data types effectively.
86. Explain the concept of a bridge table in dimensional modeling.
Ans:
In dimensional modeling, a bridge table is used to resolve many-to-many relationships between dimension tables. It contains the keys from the related dimensions, allowing for the association of multiple values from one dimension to multiple values in another. For instance, in a sales scenario, a bridge table might link a product dimension to a promotion dimension to represent the many-to-many relationship between products and promotions.
87. How do you choose the appropriate data storage format in a data warehouse?
Ans:
Choosing the appropriate data storage format in a data warehouse depends on the specific requirements and workload characteristics. Columnar storage is efficient for analytical queries, as it stores data column-wise, optimizing for data retrieval. On the other hand, row-based storage is suitable for transactional workloads that involve frequent inserts and updates. The choice depends on factors like query patterns, compression requirements, and the nature of the analytical tasks performed on the data.
88. What are the considerations when choosing between a star schema and a snowflake schema?
Ans:
When choosing between a star schema and a snowflake schema for a data warehouse, consider factors such as simplicity, query performance, and maintenance. Star schemas are simpler with fewer joins, leading to better query performance, but snowflake schemas provide more normalized data, facilitating data integrity and reducing redundancy. Choose based on the balance between performance and data integrity requirements, as well as the complexity of your analytical queries.
89. How can you ensure data consistency across different data sources in a data warehouse?
Ans:
Ensuring data consistency across different data sources in a data warehouse involves implementing robust ETL (Extract, Transform, Load) processes. Utilize data profiling tools to understand source data variations, establish data quality rules, and implement data cleansing and transformation procedures. Employ data reconciliation techniques, version control, and metadata management to track changes and maintain consistency. Regularly audit and validate data to address discrepancies and ensure accurate information across diverse sources.
90. Describe the role of indexing in optimizing query performance in a data warehouse.
Ans:
Indexing plays a crucial role in optimizing query performance in a data warehouse. Indexes enhance data retrieval speed by providing a structured way to access data. In a data warehouse, create indexes on columns frequently used in join conditions, filtering, and sorting. However, excessive indexing can impact insert and update performance, so strike a balance. Regularly analyze query execution plans and adjust indexes accordingly to ensure optimal performance based on the specific patterns of data retrieval in your warehouse.




