
Last updated on 25th Jul 2025| 11704
- Introduction Understanding SQL and NoSQL Databases
- Key-Value Stores Explained
- Document-Based NoSQL Databases
- Column-Family Stores Overview
- Graph Databases and Their Applications
- Setting Up a NoSQL Database
- Basic CRUD Operations in NoSQL
- Querying and Indexing in NoSQL
- Data Modeling Best Practices
- Advanced Features and Scaling NoSQL
- Summary and Decision Framework
Introduction to NoSQL Databases
The rapid expansion of digital technologies has generated a vast amount of data in diverse formats and structures. Database Training. Traditional relational databases, while robust and consistent, often fall short when dealing with unstructured, high-velocity, and large-scale data. This is where NoSQL (Not Only SQL) databases have become increasingly relevant. Born from the need for more flexible, distributed, and scalable solutions, NoSQL databases allow for horizontal scaling, relaxed consistency, and support for various data models. NoSQL databases are classified based on how they store and manage data. The most common categories include key-value stores, document databases, column-family stores, and graph databases. Each type offers unique strengths and is suited for different application scenarios from caching and real-time analytics to social networks and IoT systems. This comprehensive guide provides insights into the architecture, use cases, implementation strategies, and best practices of NoSQL databases.
Do You Want to Learn More About Database? Get Info From Our Database Online Training Today!
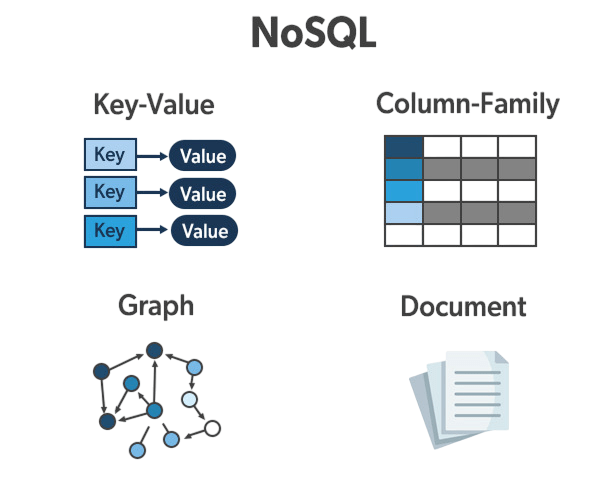
Key-Value Stores Explained
Cassandra Keyspace Key-value databases are the simplest form of NoSQL databases, storing data as pairs of keys and values. These databases are ideal for applications requiring fast lookups, such as session management, caching, and user preferences. Key-value stores are a flexible NoSQL database type where each piece of data is stored as a unique key-value pair. These databases shine in situations that need fast data retrieval, such as managing shopping carts, storing tokens, and real-time recommendation engines.
Document-Based NoSQL Databases
Document databases store data in documents, typically in JSON or BSON format. Each document is a self-contained unit with its own schema, making these databases highly flexible.
- Structure: Stores data in documents, typically in JSON or BSON format, with nested key-value pairs and flexible schema.
- Use Cases: Ideal for content management systems, user profile storage, and inventory management applications.
- Popular Examples: MongoDB, CouchDB, Firebase—each supports dynamic and scalable document handling.
- Advantages: Schema flexibility, support for rich queries and indexing, and solid performance in real-world applications.
- Limitations: Complexity in join operations and risk of data redundancy due to denormalized data models.
Column-Family Stores Overview
Column-family databases organize data into rows and dynamic columns grouped into families. MongoDB vs SQL These systems are optimized for reading and writing large volumes of data across distributed clusters.
- Structure: Organizes data into rows and dynamic columns grouped into families, stored across distributed tables.
- Use Cases: Suited for high-throughput applications like real-time analytics, time-series tracking, and recommendation engines.
- Popular Examples: Apache Cassandra, HBase, and ScyllaDB—each designed for scalability and fault tolerance.
- Advantages: Offers high availability, efficient storage, and excellent horizontal scalability in distributed environments.
- Limitations: Can be challenging to model data correctly; relies on eventual consistency which may affect real-time accuracy.
- Key-Value: GET, PUT, DELETE
- Document: db.collection.insert(), find(), updateOne()
- Column: INSERT, SELECT (using CQL)
- Graph: MATCH, CREATE (using Cypher or Gremlin).
- Document Databases: Use structured query methods such as
- Columnar: Enables slice queries and indexed lookups.
- Graph: Allows complex pattern matching.
- Indexing: Supports single field, compound, full-text, and geospatial indexing depending on the database.
- Real-Time Analytics: Ingest and analyze streaming data from logs, sensors, or user activity.
- Social Networks: Handle dynamic user profiles, relationships, and content feeds with graph or document stores.
- Recommendation Engines: Store user behavior and preferences to generate personalized suggestions.
- Content Management Systems: Flexibly manage articles, images, and metadata without strict schema constraints.
- IoT Data Ingestion: Capture diverse device telemetry in high volumes from edge networks.
- Chat & Messaging Platforms: Prioritize low-latency delivery and scalability for real-time communication.
- Design for Access: Model the data structure based on expected query patterns prioritizing retrieval speed over strict normalization.
- Embed: Nest related data within documents to reduce the need for joins and improve read performance.
- Reference: Use references when data is reused across multiple entities, promoting consistency and modularity.
- Denormalize: Intentionally duplicate data to simplify queries and eliminate costly joins—common in high-read NoSQL workloads.
- Partition Wisely: Select partition (or shard) keys that balance data across nodes evenly, preventing hotspots and enabling horizontal scalability.
- Sharding: Splits and distributes data across multiple servers or partitions to enhance scalability and performance.
- Replication: Maintains copies of data across multiple nodes to provide fault tolerance and high availability.
- In-Memory Caching: Uses memory-based storage (e.g., Redis) to reduce latency and accelerate read/write operations.
- Stream Processing: Enables real-time data handling and transformation through platforms like Apache Kafka and Apache Spark.
- Security: Implements role-based access control, encryption at rest and in transit to ensure data protection and regulatory compliance.
- Horizontal Scaling: Increases capacity by adding more servers or nodes rather than upgrading individual machines.
- Auto-Sharding: Automatically divides data to balance workload across nodes without manual intervention.
- Load Balancing: Distributes incoming traffic effectively to maximize resource utilization and maintain responsiveness.
Would You Like to Know More About Database? Sign Up For Our Database Online Training Now!
Graph Databases and Their Applications
Graph databases are a smart way to manage data. They use graph structures made up of nodes, edges, and properties to show complex data relationships. By organizing information so that nodes represent individual entities and edges show how they connect, these databases do well in situations that require detailed relationship mapping. This includes things like social network analysis, fraud detection, and supply chain management. Database Training Top platforms like Neo4j, JanusGraph, and ArangoDB show how versatile this technology can be. They provide strong tools for effectively navigating and examining related data. Although graph databases offer clear relationship modeling and strong performance in relational queries, they have some downsides. They may not work as well with non-relational data and are often suited for specific types of applications. Still, their special ability to show detailed connections makes them essential for organizations looking for deeper insights into complex, relationship-based datasets.

Setting Up a NoSQL Database
When deploying a NoSQL database, organizations must evaluate several key factors. These include hardware requirements, data modeling strategies, and performance goals. Modern database systems provide flexible deployment options. Choosing an Enterprise Data Strategy These range from cloud-native services like MongoDB Atlas and Amazon DynamoDB to containerized solutions using Docker and traditional manual installations. The implementation process usually involves choosing the right database platform, downloading necessary binaries or container images, and completing a setup that covers important configuration elements. These elements include replication mechanisms, sharding configurations, solid backup policies, and secure authentication protocols. By carefully navigating these deployment factors, businesses can effectively use NoSQL technologies to improve their data management and support scalable, high-performance computing environments.
To Earn Your Database Certification, Gain Insights From Leading Blockchain Experts And Advance Your Career With ACTE’s Database Online Training Today!
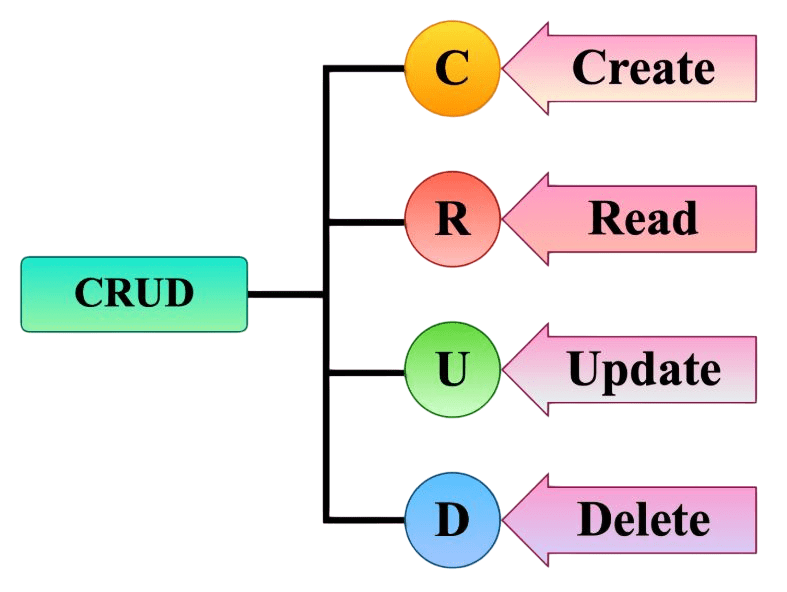
Basic CRUD Operations in NoSQL
CRUD (Create, Read, Update, Delete) operations are fundamental to all database systems. NoSQL databases implement these operations using APIs, query languages, or command-line tools.
Querying and Indexing in NoSQL
Self-Join in SQL Efficient querying and indexing are essential for performance optimization. Although NoSQL systems may not offer SQL-like querying by default, many have their own expressive query languages.
Examples of NoSQL Applications:
Preparing for a Database Job? Have a Look at Our Blog on Database Interview Questions and Answers To Ace Your Interview!
Data Modeling Best Practices
NoSQL data modeling is different from relational databases, as it focuses on optimizing for queries rather than eliminating redundancy.
Managing Consistency and Availability
In the world of NoSQL databases, system designers often face the challenge of managing data consistency. They do this by relaxing traditional ACID guarantees to improve availability and partition tolerance. This trade-off is clearly outlined by the CAP theorem. These systems provide various consistency models. Cassandra The Buzzword in Database. Strong consistency ensures data is synchronized immediately, while eventual consistency allows for gradual updates. Platforms like Cassandra even allow users to set their own consistency levels based on specific application needs. To keep data intact, NoSQL architectures usually use strategies like write-ahead logging and replication. Many systems also use quorum-based read and write methods when strong consistency is essential. By carefully balancing these methods, organizations can create robust and flexible database solutions that meet different performance and reliability needs.
Advanced Features and Scaling NoSQL
NoSQL databases are highly integrable with modern platforms and services. They can be integrated with ETL tools, analytics platforms, machine learning workflows, and microservices architectures.
Advanced Features in NoSQL Databases:
Scaling Techniques:
Conclusion
Database Training NoSQL databases have revolutionized data storage and processing by offering flexible, scalable, and high-performance solutions tailored to modern digital requirements. By understanding the different types of NoSQL databases and aligning them with specific application needs, developers can design systems that are agile, robust, and future-proof. Whether it’s managing millions of sensor inputs, serving dynamic content, or modeling complex relationships in social networks, NoSQL databases provide the tools necessary to harness the power of data in innovative ways. As digital transformation accelerates, mastering NoSQL technology is becoming essential for engineers, architects, and data scientists alike.




