
Last updated on 08th Jul 2025| 10513
- Introduction to HBase and Cassandra
- Data Model and Schema Design
- Architecture Overview
- Read and Write Path Comparison
- Scalability and Distribution
- Consistency and CAP Model
- Performance Considerations
- Ecosystem Integration
Introduction to HBase and Cassandra
In the world of big data, HBase and Cassandra stand out as two powerful NoSQL databases designed to handle massive volumes of structured and semi-structured data with high availability and scalability. Both are distributed systems, but they differ significantly in architecture and use cases, prompting frequent comparisons like HBase vs Cassandra when deciding on the right tool for specific data workloads. HBase, modeled after Google’s Bigtable and tightly integrated with the Hadoop ecosystem, is ideal for batch analytics and real-time read/write access. On the other hand, Cassandra offers a peer-to-peer architecture with no single point of failure, making it well-suited for decentralized and always-on applications. For those looking to specialize in this area, Database Developer Training is crucial to mastering the intricacies of Cassandra and its distributed design. While exploring these technologies, it’s also important to understand how data is structured in traditional warehousing, such as through the Snowflake Schema in Data Warehouse systems, which allows for more normalized and flexible data modeling. When broadening the scope, the debate of Cassandra vs MongoDB vs HBase often arises, each excelling in different aspects MongoDB for its document-oriented design and developer-friendly query language, Cassandra for its write-heavy performance, and HBase for its deep integration with Hadoop for analytics. Choosing the right one depends on the specific needs of the application, data consistency requirements, and overall system architecture.
Are You Interested in Learning More About Database Certification? Sign Up For Our Database Administration Fundamentals Online Training Today!
Data Model and Schema Design
- CAP Model: In distributed systems, the CAP theorem states that a database can only guarantee two of the following three: Consistency, Availability, and Partition Tolerance. Understanding this model helps guide schema decisions, especially when working with NoSQL systems like HBase and Cassandra.
- Database Schema Design: This involves structuring tables, relationships, indexes, and constraints to optimize performance and integrity. A good schema supports current queries while remaining flexible for future needs.
Designing an effective data model and schema is foundational to building scalable, efficient, and reliable data systems. A well-structured schema not only improves query performance but also ensures consistency and maintainability as data grows. When dealing with large-scale or distributed systems, schema design must align with system architecture and business goals. Here’s a breakdown of key concepts and considerations:
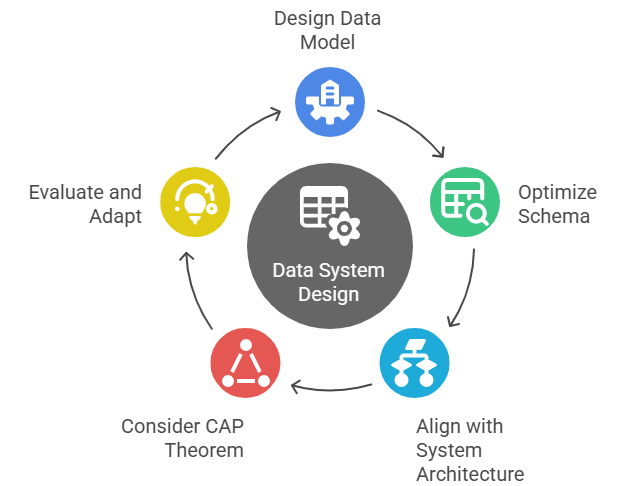
- Snowflake Schema: A type of multidimensional schema often used in data warehouses, where dimension tables are normalized. This approach allows for better data organization and reduced redundancy. What Is Apache Cassandra It is a highly scalable, distributed NoSQL database that is designed for handling large amounts of data across many commodity servers without a single point of failure.
- Ecosystem Integration: Schema design should consider integration with surrounding tools, platforms, and data pipelines, ensuring smooth interoperability across the entire data ecosystem.
- HBase and Cassandra: Both require schema designs tailored to their architecture. Cassandra prefers denormalized, query-based models, while HBase supports sparse, column-oriented schemas best suited for analytical workloads.
Architecture Overview
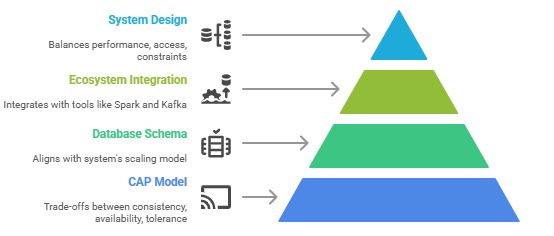
An effective architecture overview is essential for understanding how modern data systems are built to support performance, scalability, and fault tolerance. At the core of distributed systems lies the CAP Model, which highlights the trade-offs between Consistency, Availability, and Partition Tolerance crucial when choosing platforms like HBase and Cassandra. HBase favors consistency and partition tolerance, making it ideal for analytical systems with strict read/write accuracy, whereas Cassandra leans toward availability and partition tolerance, supporting high-speed transactional workloads. A solid Database Schema Design complements the architecture by aligning data structures with application needs and system constraints. In data warehousing, the Snowflake Schema offers a normalized structure that enhances query efficiency and storage management by organizing data into related tables. To maximize performance, a Complete Guide on SQL Optimization Techniques is essential for refining queries and ensuring faster data retrieval in complex systems. Ecosystem Integration plays a vital role in modern architectures, ensuring seamless communication and compatibility between storage systems, processing engines, and analytics tools. Whether integrating with Hadoop, Spark, or real-time dashboards, the system’s components must work cohesively. In this context, HBase integrates deeply with the Hadoop ecosystem, while Cassandra excels in decentralized environments with minimal dependencies. A well-designed architecture balances all these elements schema design, data flow, system roles, and CAP trade-offs to build robust, flexible solutions capable of handling today’s complex data demands.
Are You Interested in Learning More About Database Certification? Sign Up For Our Database Administration Fundamentals Online Training Today!
Read and Write Path Comparison
- Write Path – Cassandra: Writes in Cassandra are fast and efficient. Data is first written to a commit log, then to a memtable, and later flushed to SSTables. This makes it highly optimized for write-heavy workloads.
- Write Path – HBase: HBase follows a similar write pattern but relies heavily on HDFS and is more suited for batch processing. It offers strong consistency but slightly higher write latency compared to Cassandra. Understanding the Types of SQL Indexes can also be crucial for optimizing database performance, especially when working with large-scale systems like HBase or Cassandra.
- Read Path – Cassandra: Reads can be slower due to the need to merge data from multiple SSTables. However, tunable consistency gives flexibility in balancing speed and accuracy.
- Read Path – HBase: HBase performs better in read-heavy analytical scenarios, especially when integrated with Hadoop, but random reads may incur latency.
- Cassandra vs MongoDB vs HBase: MongoDB is document-oriented with faster reads for unstructured data. Cassandra handles high write throughput well, while HBase excels in analytics-driven reads.
- Snowflake Schema in Data Warehouse: Unlike these NoSQL systems, Snowflake schemas in data warehouses focus on normalized relational structures optimized for complex queries, not high-velocity transactional reads/writes.
- HBase vs Cassandra – Consistency Approach: HBase follows a CP (Consistency + Partition Tolerance) model, prioritizing data accuracy even during network splits. Cassandra, by contrast, leans toward AP (Availability + Partition Tolerance), offering high uptime with tunable consistency.
- Strong vs Eventual Consistency:HBase provides strong consistency, making it reliable for financial or audit applications. Cassandra offers eventual consistency by default but allows configuration to balance performance with accuracy. Understanding What is a Transaction Processing System is essential in this context, as these systems are designed to handle high-volume, real-time transactions, which is key to applications requiring strong or eventual consistency.
- Cassandra vs MongoDB vs HBase: MongoDB is flexible, offering strong consistency by default but can scale back for performance. Cassandra is highly available, while HBase ensures strict data correctness.
- Schema Impact on Consistency: Proper database schema design helps manage consistency, especially in distributed writes and reads.
- Snowflake Schema in Data Warehouse: Snowflake schemas use strict relational rules, naturally enforcing consistency in structured analytical workloads.
- Consistency Through Ecosystem Tools: Tools like Zookeeper (in HBase) or Gossip Protocol (in Cassandra) maintain system state and help ensure consistency across nodes.
Understanding the read and write paths of database systems is critical when selecting the right platform for your application’s performance and consistency needs. Each system handles data differently, especially in distributed environments, which leads to performance and design trade-offs. Let’s explore key comparisons with a focus on HBase vs Cassandra and others.

Scalability and Distribution
Scalability and distribution are critical considerations in modern data architecture, especially when working with large-scale, high-availability systems. The CAP Model plays a foundational role in shaping how systems handle scalability, forcing trade-offs between Consistency, Availability, and Partition Tolerance. HBase and Cassandra offer different approaches to distributed scalability. HBase, built on Hadoop, provides strong consistency and is ideal for read-heavy, batch-processing environments, while Cassandra uses a peer-to-peer architecture that supports horizontal scaling and high write throughput, favoring availability and partition tolerance. Effective Database Schema Design must align with each system’s scaling model; for example, Cassandra prefers denormalized, query-driven schemas to minimize joins, while HBase can support sparse, column-family-based schemas for analytical workloads. To master these design principles, Database Administration Fundamentals Online Training is a valuable resource for gaining the expertise needed to work with these systems efficiently. In contrast, the Snowflake Schema used in traditional data warehouses emphasizes normalized data models optimized for complex querying rather than operational scaling. Ecosystem Integration further influences scalability, as both HBase and Cassandra integrate differently with tools like Spark, Kafka, and Hadoop. HBase fits well into Hadoop-native ecosystems, whereas Cassandra integrates flexibly across cloud and on-premise environments. Designing scalable, distributed systems requires balancing performance needs, data access patterns, and architectural constraints, making the understanding of each component essential for long-term success.
Consistency and CAP Model
In distributed systems, consistency refers to ensuring that all nodes see the same data at the same time. The CAP Model Consistency, Availability, and Partition Tolerance explains that a distributed system can only fully guarantee two of the three at any time. This model shapes how databases handle data reliability and user access. Let’s explore how consistency plays out across different systems.
Performance Considerations
When evaluating database systems, performance considerations play a vital role in ensuring optimal responsiveness, scalability, and reliability. Key factors influencing performance include the CAP Model, which highlights trade-offs between Consistency, Availability, and Partition Tolerance. Understanding this helps in choosing the right balance for specific workloads. HBase and Cassandra are perfect examples. HBase favors consistency and is better suited for read-heavy, batch-processing applications, while Cassandra prioritizes availability and excels in high-throughput write scenarios. Understanding What is a Database is fundamental here, as both HBase and Cassandra are types of databases, each designed to meet specific needs based on their architecture and consistency models. Database Schema Design significantly affects performance; for instance, denormalized, query-driven schemas in Cassandra reduce the need for joins, enhancing read speed, whereas HBase’s column-oriented design is ideal for sparse data sets and analytics. In contrast, the Snowflake Schema used in data warehouses is normalized and designed for complex queries, which can affect performance in operational environments but works well for analytical workloads. Ecosystem Integration also impacts performance. Cassandra integrates smoothly with stream processing systems like Apache Kafka and Spark, enabling real-time analytics, while HBase benefits from deep integration with Hadoop and its batch-processing capabilities. Ultimately, choosing between these systems and designing for performance depends on workload patterns, consistency needs, data structure, and integration requirements, making a comprehensive evaluation essential for high-performing data architecture.
Are You Preparing for Database Developer Jobs? Check Out ACTE’s DBMS Interview Questions and Answers to Boost Your Preparation!
Ecosystem Integration
Ecosystem integration is a critical aspect of modern data infrastructure, determining how seamlessly a database system interacts with surrounding tools, platforms, and services. Effective integration enhances scalability, performance, and operational efficiency. For distributed databases like HBase and Cassandra, the CAP Model plays a key role in guiding integration decisions HBase, favoring Consistency and Partition Tolerance, integrates tightly with Hadoop, MapReduce, and Apache Phoenix for batch analytics, while Cassandra, built on an Availability and Partition Tolerance model, pairs well with tools like Apache Kafka, Spark, and Flink for real-time processing and event-driven architectures. Smooth integration also depends heavily on database schema design, as systems with poorly structured schemas can lead to performance bottlenecks when scaling across multiple platforms. In contrast, traditional data warehousing systems often use a Snowflake Schema, which, though optimized for complex queries, may require additional ETL processes to integrate with modern big data tools. For those looking to build expertise in this area, Database Administration Fundamentals Online Training provides essential skills for managing and optimizing these systems. The choice between systems like HBase and Cassandra often comes down to how well they fit into an organization’s existing ecosystem whether it’s a cloud-native stack, an on-premises Hadoop cluster, or a hybrid environment. Ultimately, strategic ecosystem integration ensures that data flows efficiently across services, supporting both operational and analytical use cases without compromising on reliability or performance.




