
Last updated on 05th Sep 2025| 11815
- What is Cursor in SQL?
- Types of Cursors in SQL
- Difference between types of Cursors in SQL
- Why do we need to use Cursors in SQL?
- How to create a Cursor in SQL?
- Advantages of Cursors in SQL
- Disadvantages of Cursors in SQL
- Conclusion
What is Cursor in SQL?
In SQL, a cursor is a database object used to handle one row at a time from the result set. Cursors allow sequential processing of individual rows returned by a standard SQL query, which uses all the data in a collection. Cursors are typically used when complex logic requires processing data row by row, or when iteration is necessary techniques covered in Database Training, where learners gain hands-on experience with procedural SQL, cursor control, and performance-aware query design. Understanding how and when to use cursors empowers developers to handle advanced transactional workflows and row-level operations with precision. They can be declared, opened, fetched, and closed as part of their lifecycle. A cursor can be static, dynamic, and/or forward-only, each with different behavior patterns. Overusing cursors can impact performance, so they must be managed properly.
To Explore Database in Depth, Check Out Our Comprehensive Database Online Training To Gain Insights From Our Experts!
Types of Cursors in SQL
To handle row-by-row processing, SQL supports various types of cursors, each designed for specific purposes techniques outlined in Guide on SQL Optimization Techniques, where learners explore how procedural logic, indexing strategies, and query restructuring can dramatically improve performance. Understanding when to use cursors versus set-based operations is key to balancing flexibility with efficiency in large-scale database systems.
- Implicit Cursor in SQL: Automatically created by the SQL engine for single-row DML statements (INSERT, UPDATE, DELETE). Efficient for single-row tasks but offers limited control over behavior or logic.
- Explicit Cursor in SQL: Programmer-defined cursor for managing rows returned from a query one at a time. Requires declaration, opening, fetching, and closing. Enables custom logic and looping, though less efficient than set-based approaches.
- Static Cursor in SQL: Operates on a snapshot of the result set taken when opened. Changes to the underlying table are not reflected. Ideal for consistent, read-only reporting with predictable datasets.
- Dynamic Cursor in SQL: Reflects real-time changes to the underlying data while open. Sensitive to INSERT, UPDATE, DELETE operations. Suitable for real-time visibility but resource-intensive in high-transaction environments.
- Forward-Only Cursor in SQL: Traverses the result set from first to last row without backward movement. Read-only and does not reflect post-open changes. Most efficient in terms of memory and system resources; ideal for linear data processing.
Difference between types of Cursors in SQL
In SQL, cursors retrieve, manipulate, and navigate the result set row by row, especially when row-level processing is needed. There are different types of cursors, each with unique behaviors and performance implications. Implicit cursors are automatically created by SQL whenever a SELECT statement returns data or when DML operations, like INSERT, UPDATE, or DELETE, are performed. These are simple and do not require explicit statements from the programmer automation principles covered in Database Training, where learners explore how default behaviors, implicit constraints, and system-managed operations streamline database administration. By understanding these built-in mechanisms, developers can reduce manual overhead while maintaining consistency and reliability across data workflows. In contrast, explicit cursors are declared and controlled manually by the developer in procedural SQL (like PL/SQL or T-SQL), providing more control over fetching and manipulating individual rows. Explicit cursors can be further categorized. Static cursors work with a snapshot of data and do not reflect changes made after they are opened, ensuring stability but potentially showing outdated records. Dynamic cursors, on the other hand, reflect all changes made to the underlying data while the cursor is open, offering real-time visibility but at an extra cost. Forward-only cursors can only move from the first to the last row and are quicker and more memory-efficient, whereas scrollable cursors allow movement in both directions, offering flexibility at the expense of performance. Choosing the right type of cursor depends on the specific task requirements, performance considerations, and the need for real-time data visibility.
Do You Want to Learn More About Database? Get Info From Our Database Online Training Today!
Why do we need to use Cursors in SQL?
- Cursors are essential in SQL when you need to implement row-by-row processing with query results, where a traditional set-based SQL processing model wouldn’t be effective yet designing the underlying structure for such operations begins with Data Modelling, where learners explore how entities, attributes, and relationships are defined to support procedural logic and transactional workflows. A well-structured data model ensures that cursor-based operations remain efficient, maintainable, and aligned with business rules.
- SQL is primarily designed to work on a set of records, but many real-world operations require processing each row individually. Several operational challenges include applying conditional logic, using sequential calculations, or invoking external procedures.
- For example, consider a company that wants to send personalized emails to employees based on their department. In such cases, a cursor allows you to loop through each row, examine values, and act accordingly.
- Cursors are often used or required in stored procedures, batch jobs, and triggers where procedural control is necessary. However, cursors can consume significant resources and may be slower, so it’s advisable to avoid them unless necessary, especially if performance is a concern and a suitable, efficient set-based alternative is unavailable.
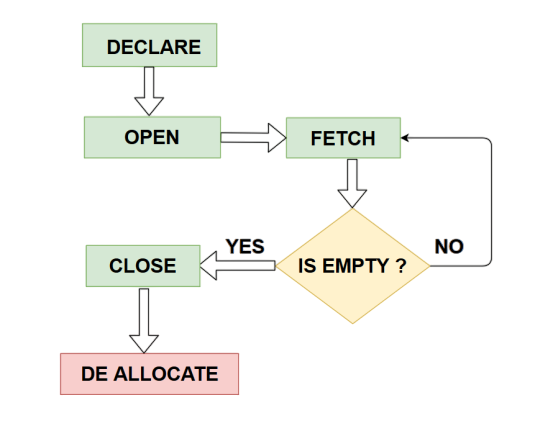
- DECLARE: Creates the cursor based on a SELECT statement.
- OPEN: Executes the query and positions the cursor before the first row.
- FETCH: Retrieves the current row and advances the cursor position.
- @FETCH_STATUS: System function that checks whether the last FETCH was successful.
- CLOSE and DEALLOCATE: Releases the cursor and frees associated resources.
- Cursor processing is slower than set-based operations that handle data as a group rather than individual operations, processing one row at a time.
- While the equivalent of a SELECT statement may seem the same as the existing standard SQL SELECT, writing, managing, and debugging a cursor is more complex than standard SQL especially when working with document-based databases, as explored in What is MongoDB and its Queries. This guide introduces MongoDB’s query language (MQL), cursor operations, and indexing strategies, helping developers navigate the nuances of NoSQL data retrieval and manipulation with precision and flexibility.
- A cursor holds locks for longer periods, leading to blocking and issues with concurrency in environments with multiple users.

How to create a Cursor in SQL?
To create a cursor in SQL, several steps must be followed to define, manage, and process data row by row procedural logic that builds upon foundational concepts introduced in What is a Database, where learners explore how structured data is stored, accessed, and manipulated within relational systems. Understanding how databases organize information into tables, rows, and columns is essential before implementing row-level operations like cursors for transactional workflows.
Would You Like to Know More About Database? Sign Up For Our Database Online Training Now!
Advantages of Cursors in SQL
Cursors are a useful tool for developers when it comes to handling data within databases. They allow for manipulation of result sets in ways that regular SQL queries might not support techniques that build upon foundational principles covered in What is Database Management, where learners explore how DBMS platforms enable structured data control, transaction handling, and multi-user access. Understanding how cursors fit into broader database operations helps developers implement precise, row-level logic while maintaining system integrity and performance.

While using cursors usually involves writing a bit more code compared to standard SQL, their ability to integrate with control flow statements like IF and WHILE makes them quite powerful, especially within stored procedures. Cursors can handle multiple rows of data, which is ideal when each row requires specific attention or when an external procedure needs to be executed for each row of the result set. Understanding how to implement cursors effectively can enhance your ability to manage data dynamically and improve application performance.
Disadvantages of Cursors in SQL
Want to Learn About Database? Explore Our Database Interview Questions and Answers Featuring the Most Frequently Asked Questions in Job Interviews.
Conclusion
SQL cursors are very useful for performing row-by-row operations when set-based processing cannot meet the needs of data transformation, especially in analyzing or manipulating procedural aspects of the data. Using cursors can add a great deal of flexibility to your queries, but be cautious of potential performance impacts on large datasets. Cursors can be used in many scenarios, including payroll processing and updating order statuses, making it easier to perform complex logic that cannot be easily expressed in standard SQL techniques explored in Database Training, where learners gain hands-on experience with procedural SQL, transaction control, and performance-aware query design. Understanding when and how to use cursors effectively is key to building scalable, maintainable database solutions. Gaining a complete understanding of SQL cursors will give you an advantage in analyzing and working with procedural logic in a relational database system, especially in enterprise applications.




