
Last updated on 04th Jul 2020| 1983
A relational database can be accessed using a command or set of commands called a SQL (Structured Query Language) query. Structured sets of data kept in tables, relational databases are managed and worked with using SQL, a standard programming language. SQL queries are strong instruments for data retrieval, updating, insertion, and deletion from databases.
1. What is the meaning of a database and what does it contain?
Ans:
Structured and arranged data that is routinely managed and stored makes up a database. It functions as an information repository that enables effective data management, updating, and retrieval for users. To specify the structure and relationships within the data, databases usually include tables, relationships, and metadata.
2. What do you mean by DBMS and RDBMS?
Ans:
Relational database management systems, or RDBMSs, are distinguished from database management systems, or DBMSs. An RDBMS is a particular kind of database management system that uses tables with rows and columns to create relationships between data elements in order to manage data in a relational model. More broadly, a database management system (DBMS) is any system that maintains databases, even non-relational ones.
3. Explain the query and its language.
Ans:
Users can retrieve, modify, and manage data by using query language, a specialised language used to communicate with databases. Written in a query language such as SQL (Structured Query Language), a query is a targeted request for data from a database to carry out operations like SELECT, INSERT, UPDATE, and DELETE.
4. How would you define “subquery”?
Ans:
- Definition: A subquery is a nested SQL query embedded within another query.
- Purpose: It is used to retrieve data based on specified conditions and criteria.
- Types: There are two main types—single-row subquery (returns one value) and multiple-row subquery (returns multiple values).
- Usage: Subqueries can be employed in various parts of a query, such as the SELECT, WHERE, or HAVING clauses.
5. Describe SQL and enumerate its uses.
Ans:
Relational database management and manipulation are done with the help of a domain-specific language called SQL, or Structured Query Language. Data definition (CREATE, ALTER, DROP), data retrieval (SELECT), data manipulation (INSERT, UPDATE, DELETE), and data control (GRANT, REVOKE) are some of its uses. Database management systems like MySQL, PostgreSQL, and Microsoft SQL Server all make extensive use of SQL.
6. What is the definition of dynamic SQL and how can one use it?
Ans:
The process of creating and executing SQL statements dynamically at runtime is known as dynamic SQL. As a result, creating queries depending on various circumstances or user inputs is made more flexible. When a query’s structure is unknown until runtime, dynamic SQL is frequently utilised.
7. What do you mean when you talk about a database’s tables and fields?
Ans:
Tables in a database are structures that organize and store data in rows and columns. Fields, also known as columns, represent the attributes or properties of the data, while rows contain the actual data records.
8. What kinds of tables are there that SQL uses?
Ans:
SQL uses different types of tables, including base tables, which store the actual data, and views, which are virtual tables based on the result of a query. Temporary tables are also used to store temporary data during a session.
9. What do you mean by temporary tables?
Ans:
Temporary tables are tables that exist only for the duration of a session or a specific operation. They are useful for storing intermediate results during complex queries or for temporary storage of data that does not need to be permanently stored in the database.
10. What does the term “primary key” and “foreign key” in SQL mean?
Ans:
In SQL, a “primary key” is a unique identifier for a record in a table. It ensures that each row in the table is uniquely identified and helps enforce data integrity. A “foreign key,” on the other hand, is a field in a table that is a primary key in another table. It establishes a link between the two tables, enforcing referential integrity.
11. What do candidate key and superkey mean?
Ans:
Well, let me give you a condensed version of this:
- A set of one or more characteristics known as a superkey allows a record in a table to be uniquely identified.
- A candidate key is a minimal superkey that is selected to be a table’s primary key in order to uniquely identify records.
12. Explain the various kinds of SQL subsets or commands.
Ans:
- SQL subsets or commands include Data Query Language (DQL) for retrieving
- data (SELECT), Data Definition Language (DDL) for defining and managing
- database objects (CREATE, ALTER, DROP), Data Manipulation Language
- (DML) for manipulating data (INSERT, UPDATE, DELETE), and Data Control
- Language (DCL) for managing access and permissions (GRANT, REVOKE).
13. Could you give me an overview of a few DDL commands?
Ans:
Data Definition Language (DDL) commands are used to define, modify, and manage the structure of database objects. Key commands include “CREATE” (for creating tables, views, etc.), “ALTER” (for modifying existing objects), and “DROP” (for deleting objects). DDL commands focus on the database schema.
14. What Different Commands Are Employed in SQL Subsets?
Ans:
SQL subsets often refer to specific categories of commands. Common subsets include DDL (Data Definition Language), DML (Data Manipulation Language), DCL (Data Control Language), and TCL (Transaction Control Language). Each subset serves a distinct purpose in managing databases.
15. Describe the SQL JOIN operation and its various types.
Ans:
SQL JOIN operation combines rows from two or more tables based on a related column between them. The types of JOIN include INNER JOIN (returns only matching rows), LEFT JOIN (returns all rows from the left table and matching rows from the right table), RIGHT JOIN (opposite of LEFT JOIN), and FULL JOIN (returns all rows when there is a match in either table).
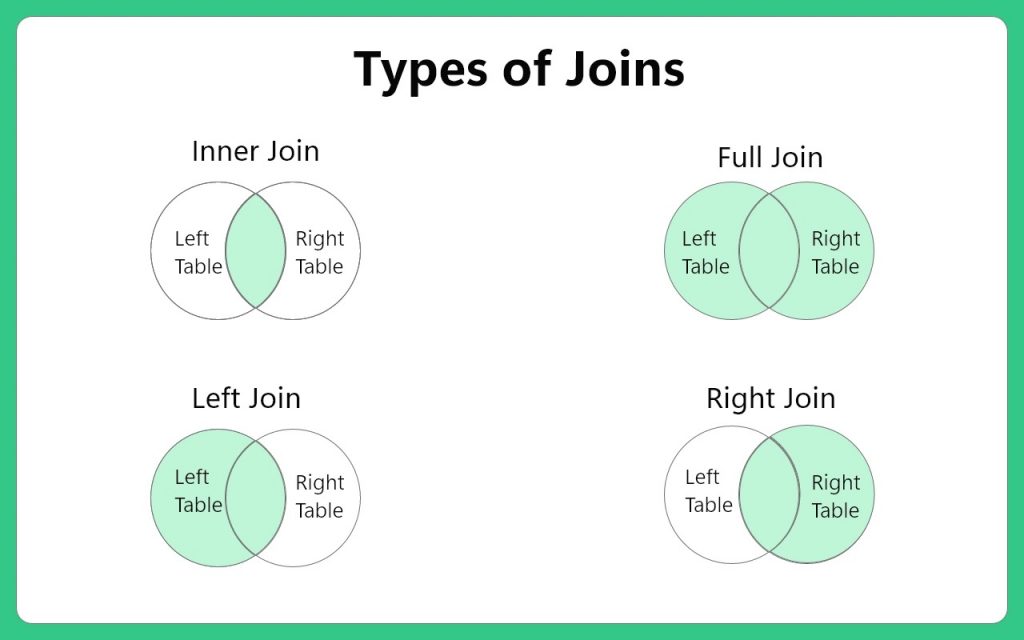
16. Could you describe the various kinds of operators that SQL uses?
Ans:
SQL uses various operators, including arithmetic operators (+, -, *, /), comparison operators (=, <>, <, >, <=, >=), logical operators (AND, OR, NOT), and more. These operators are essential for formulating conditions and expressions in SQL queries.
17. What do composite keys entail?
Ans:
Composite keys in SQL refer to a primary key that consists of more than one column. Instead of a single column, a composite key uses a combination of columns to uniquely identify a record in a table.
18. What does the term “self join” mean?
Ans:
A “self join” in SQL occurs when a table is joined with itself. It involves creating two instances of the same table and relating them with a JOIN operation, often using aliases to differentiate between the instances.
19. What does the term “cross join” mean?
Ans:
A “cross join” in SQL produces the Cartesian product of two tables, meaning it combines each row from the first table with every row from the second table. It results in a table with all possible combinations of rows from both tables.
20. What limitations exist in SQL?
Ans:
Limitations in SQL include the inability to perform complex mathematical calculations directly, limited support for handling hierarchical data, and potential security concerns such as SQL injection if input is not properly sanitized.
21. What does a SQL JOIN operation accomplish?
Ans:
In SQL, a JOIN operation serves to merge rows from multiple tables by utilizing a related column, thereby creating connections between the tables. The various JOIN types (INNER, LEFT, RIGHT, FULL) determine the approach to handling unmatched rows in the merging process.
22. What do you mean by global and local variables?
Ans:
Global variables in SQL are accessible throughout an entire program or script, while local variables are limited to the scope in which they are declared, often within a specific block or function.
23. Describe the types of SQL indexes and what they are.
Ans:
Types of SQL indexes include clustered indexes (determines the order of data rows in the table based on the indexed column), non-clustered indexes (creates a separate structure for the index), unique indexes (ensures the uniqueness of values in the indexed column), and composite indexes (created on multiple columns).
24. Could you summarise the commands for DML?
Ans:
Data Manipulation Language (DML) commands are employed to interact with the data stored in the database. Common DML commands include “SELECT” (retrieving data), “INSERT” (adding new records), “UPDATE” (modifying existing data), and “DELETE” (removing records). DML ensures the manipulation of data within the database.
25. Could you give me an overview of a few DCL commands?
Ans:
Data Control Language (DCL) commands are concerned with the access and permissions of users. Key DCL commands are “GRANT” (providing access privileges) and “REVOKE” (removing access privileges). DCL ensures the security and integrity of the database.
26. Could you give me some TCL command overview?
Ans:
Transaction Control Language (TCL) commands manage transactions in a database. Common TCL commands include “COMMIT” (to save changes), “ROLLBACK” (to undo changes), and “SAVEPOINT” (to set a point within a transaction). TCL commands ensure the consistency and reliability of transactions.
27. List the different kinds of dependencies and provide your definition of dependency.
Ans:
- In computer science, dependency describes the relationship between two entities where a change in one could have an impact on the other.
- There are three types of dependencies: transitive (an indirect relationship between attributes), multivalued (dependency between two sets of attributes), and functional (one attribute uniquely determines another).
28. What do stored procedures entail?
Ans:
Stored procedures in SQL are precompiled sets of one or more SQL statements that can be stored and executed on demand. They enhance reusability, maintainability, and security by encapsulating logic. Stored procedures can accept parameters and return values, making them powerful tools for database management.
29. What are the purposes of a SQL database?
Ans:
SQL databases serve various purposes, including data storage, retrieval, and manipulation. They provide a structured and efficient way to manage large datasets, ensure data integrity through constraints, support transactions for reliability, and allow for easy querying and reporting.
30. What Do Set Operators Mean?
Ans:
Set operators in SQL, such as “UNION”, “INTERSECT”, and “EXCEPT”, are used to combine or compare the result sets of two or more SELECT statements. They allow for set operations, enabling the retrieval of specific data from multiple sources.
31. Explain what you mean by a buffer pool and list its advantages.
Ans:
A buffer pool in a database system is a cache area in memory where frequently accessed data is stored temporarily. Its advantages include improved performance by reducing disk I/O, faster data retrieval, and efficient utilization of system resources, ultimately enhancing the overall responsiveness of the database.
32. Write a query to find the average salary for each department.
Ans:
- Select Columns: Use the SELECT statement to choose the relevant columns, such as “Department” and “Salary.”
- Calculate Average: Apply the AVG() function to the “Salary” column to calculate the average salary for each department.
- Group Data: Implement the GROUP BY clause on the “Department” column to group the results by department, ensuring distinct averages.
33. In your opinion, what does “data integrity” mean?
Ans:
The precision, consistency, and dependability of the data in a database are referred to as data integrity. It guarantees that information is stored, retrieved, and processed without change. This entails preserving the accuracy and dependability of data throughout its whole lifecycle.
34. What Does a Database’s Cardinality Mean?
Ans:
By indicating the number of instances in one table that are connected to the number of instances in another, cardinality in a database establishes the relationship between tables. One to many, one to one, or many to many can be the mode.
35. Describe Cursor and explain how to use it.
Ans:
A cursor in a database is a pointer or an iterator used to navigate through the rows of a result set. It is essential for interacting with database records. To use a cursor, you typically open it, fetch data, perform operations, and close it after completion.
36. What kinds of database normalization and normalization are there?
Ans:
- First Normal Form, or 1NF: Make sure that every table cell has a single value and that every column represents an atomic attribute to get rid of duplicate rows.
- Second Normal Form, or 2NF: Make sure that every non-key attribute depends on the primary key in its entirety for functionality in order to remove any partial dependencies and redundancies.
- Third Normal Form, or 3NF: To further reduce redundancy and improve data integrity, eliminate transitive dependencies by making sure that non-key attributes are independent of one another.
- Boyce-Codd Normal Form, or BCNF: Eliminate non-trivial functional dependencies on attributes not included in the candidate key in order to address some anomalies.

Get In-Depth Knowledge in SQL Query Training from Expert Trainers
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
37. Could you mention the various kinds of cursors?
Ans:
Types of cursors include Forward-Only (can only move forward), Scrollable (can move in both directions), Static (shows a snapshot of data), and Dynamic (reflects changes made during cursor movement). The choice depends on the specific requirements of the database operation.
38. What Do Relationship and Entity Mean?
Ans:
In a database, an entity is a real-world object or concept, and a relationship is an association between entities. Entities have attributes describing their properties, while relationships define connections between entities.
39. What is SQL?
Ans:
Relational databases are managed and altered using a domain-specific language called SQL (Structured Query Language). It gives users a consistent interface to work with databases, enabling them to add, remove, update, and retrieve data.
40. Explain the SELECT statement and its syntax.
Ans:
The SELECT statement in SQL retrieves data from a database. Its syntax involves specifying the desired columns with “SELECT,” the table source with “FROM,” and optional conditions using “WHERE.” For example, “SELECT column1, column2 FROM table WHERE condition;”. This statement allows users to customize their queries, fetching specific data based on defined criteria. It is a fundamental component for data retrieval and forms the backbone of SQL queries for various database operations.
41. What is the purpose of the FROM clause in a SELECT statement?
Ans:
The FROM clause specifies the table from which data should be retrieved in a SELECT statement. It indicates the source of the data, allowing the database to locate and retrieve information from the specified table.
42. How are rows in a SELECT statement filtered?
Ans:
The WHERE clause in a SQL SELECT statement is used to filter rows. You can specify a condition that the rows must satisfy in order for them to be included in the result set using the WHERE clause. To define your filtering criteria, you can use logical operators (AND, OR, NOT), comparison operators (like ‘=’, ‘<>‘, ‘<', '>‘, ‘<=', '>=’), and other functions. Each row has its condition assessed, and the result set only contains rows that meet the predetermined standards.
43. Which kinds of SQL statements are there?
Ans:
- Language for Data Query (DQL): This includes the ability for users to retrieve data from the database using SELECT statements.
- Language for Data Definition (DDL): The database’s structure, including its tables, indexes, and constraints, is defined and modified using DDL statements like CREATE, ALTER, and DROP.
- Data Manipulation Language (DML): DML statements allow data to be managed and manipulated within databases. Examples of these statements are INSERT, UPDATE, and DELETE.
- Data Control Language (DCL): DCL statements are used to manage security and permissions, as well as to control access to data and database objects.
44. Describe the distinctions between NoSQL and SQL databases.
Ans:
Relational SQL databases:
- Follow a formalized schema.
- impose a predetermined data structure.
- Ideal for intricate searches and transactions.
- Give the ACID qualities (Atomicity, Consistency, Durability, and Isolation).
Non-relational NoSQL databases:
- non-relational and frequently lacking schemas.
- Give yourself some leeway when managing unstructured or semi-structured data.
- scalable and ideal for situations involving distributed data.
- Give speed and adaptability a higher priority than rigid structure.
- ideal for managing substantial data volumes.
45. Explain the difference between INNER JOIN and LEFT JOIN.
Ans:
INNER JOIN returns only the rows where there is a match in both tables, while LEFT JOIN returns all rows from the left table and the matching rows from the right table. If there is no match in the right table for a row, NULL values are returned.
46. What is normalization and denormalization in databases?
Ans:
Normalization is the process of organizing data in a database to reduce redundancy and improve data integrity. Denormalization, on the other hand, involves introducing redundancy to improve query performance by reducing the need for joins.
47. Write a query to find the second highest salary from an Employee table.
Ans:
To retrieve the second-highest salary from an Employee table, a SQL query is utilized. The query employs the MAX() function to identify the highest salary and a nested subquery to find the maximum salary below this maximum. The WHERE clause filters out salaries equal to the highest, ensuring the result represents the second-highest salary. This concise approach allows for efficient extraction of the required information from the database.
48. What is an index, and why is it important in databases?
Ans:
An index is a data structure that improves the speed of data retrieval operations on a database table. It is important because it allows the database management system to locate and access specific rows quickly, reducing the time needed to perform queries and increasing overall database performance.
49. Describe the distinction between a foreign key and a primary key.
Ans:
Primary key:
- Uniqueness: Assures that every record in a table has a distinct identity.
- Single Attribute: Consists of one or more columns that give each row a distinct identity.
- Maintains Data Integrity: Keeps Null and Duplicate Values Out of the Selected Column(s).
Foreign key
- Creates Relationships: Connects the primary key of one table to a column or group of columns in another.
- Citations Primary Key: Establishes a logical connection by pointing to the primary key of another table.
- Encourages Joins: Enables JOIN operations to retrieve related data more easily.
50. Explain the GROUP BY clause and its purpose.
Ans:
The GROUP BY clause in SQL is used to group rows that have the same values in specified columns into summary rows, like getting the total count or average. It is often used with aggregate functions such as COUNT, SUM, AVG, etc., to perform operations on each group.
51. What is the purpose of the HAVING clause?
Ans:
The HAVING clause is used in conjunction with the GROUP BY clause to filter the results of a grouped query. It allows you to apply conditions to the rows in the result set after they have been grouped, similar to the WHERE clause for individual rows.
52. What is a stored procedure?
Ans:
A stored procedure is a precompiled collection of one or more SQL statements that can be stored and executed on the database server. It is used for encapsulating a series of SQL statements into a single unit, providing modularity and ease of execution.
53. What distinguishes a subquery from a join, and what does it mean?
Ans:
Subquery:
- A query that is integrated into another SQL statement.
- surrounded by parenthesis.
- operates separately inside the primary query.
- can be applied to FROM, WHERE, or SELECT clauses.
JOIN:
- involves applying predetermined criteria to combine data from several tables.
- specifies the columns and requirements for the data combination in explicit terms.
- improves structured data retrieval from related tables.
54. What is a trigger in SQL?
Ans:
A trigger in SQL is a set of instructions that automatically runs (or “fires”) in response to specified events on a particular table or view. Triggers are used to enforce business rules, integrity constraints, or automate actions when certain events occur.
55.Explain the concept of ACID properties in database transactions.
Ans:
ACID properties (Atomicity, Consistency, Isolation, Durability) ensure the reliability of database transactions. Atomicity guarantees that a transaction is treated as a single, indivisible unit. Consistency ensures that the database remains in a valid state before and after a transaction. Isolation prevents interference between concurrent transactions, and Durability ensures that committed transactions are permanently saved even in the event of a system failure.
56. How do you handle NULL values in SQL?
Ans:
NULL values in SQL can be handled using the IS NULL or IS NOT NULL conditions in WHERE clauses to filter results based on the presence or absence of NULL values. COALESCE and CASE statements can also be used to replace or handle NULL values in SELECT queries.

Enroll in SQL Query Certification Course to Build Your Skills & Advance Your Career
Weekday / Weekend BatchesSee Batch Details57. Write a query to find duplicate records in a table
Ans:
- Use the “SELECT” statement to choose the column you want to check for duplicates, let’s call it “duplicate_column”.
- Use the “FROM” clause to specify the table name, let’s call it “your_table”.
- Utilize the “GROUP” BY clause to group records based on the chosen column “(duplicate_column)”.
- Apply the “COUNT(*)” function to count the occurrences of each value in the specified column.
58. Write a query to count the number of rows in a table.
Ans:
To determine the total number of rows in a table, a simple SQL query can be employed. The query uses the COUNT(*) function, which counts all rows in the specified table. The result is provided under the alias “RowCount,” offering a clear representation of the table’s size. Simply replace “YourTableName” with the actual table name in the query.
59. Explain the concept of a view in SQL.
Ans:
A view in SQL is a virtual table based on the result of a SELECT query. It does not store the data itself but provides a way to represent the result of a query as if it were a table. Views can simplify complex queries, enhance security by restricting access to specific columns or rows, and encapsulate complex logic for better maintainability.
60. What is the purpose of the COMMIT and ROLLBACK statements?
Ans:
COMMIT and ROLLBACK are SQL statements used with transactions. COMMIT saves the changes made during a transaction to the database, making them permanent. ROLLBACK, on the other hand, undoes the changes made during a transaction, reverting the database to its state before the transaction began. These statements help ensure the integrity and consistency of the database.
61. What distinguishes UNION from UNION ALL?
Ans:
UNION:
- merges the result sets from two or more SELECT queries.
- eliminates redundant rows from the final set of results.
- demands that the data types of the columns in every SELECT statement match.
UNION ALL:
- additionally merges the result sets from several SELECT queries.
- retains every row—duplicates included—from the merged result sets.
- keeps duplicate rows in place, producing a bigger set of results.
62. How do you update data in a table using SQL?
Ans:
To update data in a table, you use the SQL UPDATE statement. The basic syntax is “UPDATE table_name SET column1 = value1, column2 = value2 WHERE condition;”. This statement modifies existing records in the table that satisfy the specified condition by setting new values to the specified columns.
63. What is a self-join, and when would you use it?
Ans:
A self-join is a SQL query in which a table is joined with itself. This is useful when dealing with hierarchical data or when you need to compare rows within the same table. It involves aliasing the table with different names to distinguish between the two instances of the same table.
64. Explain the concept of a foreign key cascade.
Ans:
Foreign key cascade is a referential integrity constraint in which changes to the parent table’s primary key are automatically reflected in the child table. If a record in the parent table is updated or deleted, the corresponding records in the child table will also be updated or deleted automatically. This ensures data consistency across related tables.
65. How can you prevent SQL injection in your queries?
Ans:
To prevent SQL injection, use parameterized queries or prepared statements. These techniques separate SQL code from user input, making it difficult for attackers to inject malicious SQL code. Additionally, input validation, proper error handling, and using least privilege principles contribute to a more secure SQL environment.
66. What distinguishes a clustered index from a non-clustered index?
Ans:
Clustered Index:
- Physical Sorting: Using the indexed columns as a guide, this process establishes the table’s physical row order.
- Reorganizing tables: To conform to the clustered index’s order, the actual table data is rearranged.
- Every table one: For each table, only one clustered index is permitted.
Non-Clustered Index:
- Separate Structure: Establishes an index with a different structure from the table’s physical order.
- Permits Multiple Indexes: A single table may have more than one non-clustered index.
- Has No Effect on the Physical Order: The physical order of the table is preserved; a mapping between the rows and the index is stored there.
67. Explain the concept of a temporary table.
Ans:
A temporary table is a short-lived database object used for storing intermediate results during a session or transaction. It helps optimize complex queries, breaks them into simpler steps, and is automatically dropped when the session or transaction ends. Temporary tables provide data isolation, allowing different sessions to use their own temporary tables without interference. Syntax for creating temporary tables varies among databases, often using statements like “CREATE TEMPORARY TABLE”.
68. How do you perform a case-insensitive search in SQL?
Ans:
Performing a case-insensitive search in SQL can be achieved using the “COLLATE” clause, allowing you to specify a case-insensitive collation in the “WHERE” clause. Alternatively, you can use functions like “UPPER()” or “LOWER()” to convert both the column and the search value to the same case. Configuring the database collation to be case-insensitive during creation is another approach. For PostgreSQL, the “ILIKE” operator simplifies case-insensitive searches. Choose the method that aligns with your database system and query needs.
69. What is the purpose of the ORDER BY clause in a SELECT statement?
Ans:
The ORDER BY clause in a SELECT statement is used to sort the result set of a query in a specified order. It allows you to arrange the rows based on one or more columns in ascending (ASC) or descending (DESC) order. This clause is crucial when you want to present the query results in a meaningful and organized manner, making it easier for users to analyze and interpret the data. For example, you might use ORDER BY to sort a list of employees by their names alphabetically or to display products based on their prices from lowest to highest.
70. Describe the distinctions between data types VARCHAR and CHAR.
Ans:
CHAR:
- Fixed-Length: Regardless of the content, this type of storage holds a predetermined amount of characters.
- Padding: Spaces are used to fill in any content that is shorter than the allotted length.
- Storage Size: Needs to be kept in storage for each value’s maximum length specified.
VARCHAR:
- Variable-Length: Does not store trailing spaces; only the characters that are actually used are stored.
- No Padding: This maximizes storage capacity by removing any unnecessary spaces.
- Storage Size: Just the actual length of the data requires storage.
- Performance: Because of the variable-length structure, there may be a little bit more overhead.
71. Explain the concept of normalization and provide an example.
Ans:
Normalization is a database design technique used to organize and structure relational database tables to reduce redundancy and dependency. The goal is to eliminate data anomalies, such as insertion, update, and deletion anomalies, by breaking down large tables into smaller, well-defined tables. There are different normal forms (e.g., 1NF, 2NF, 3NF), each with specific rules to achieve a higher level of normalization. For instance, in 1NF, each column should contain atomic values, and in 2NF, a table should be in 1NF, and all non-prime attributes should be fully functionally dependent on the primary key.
72. Explain the concept of a transaction in SQL.
Ans:
In SQL, a transaction is a sequence of one or more SQL statements that are executed as a single unit of work. The concept of transactions is based on the ACID properties: Atomicity, Consistency, Isolation, and Durability. Atomicity ensures that a transaction is treated as a single, indivisible unit, and either all of its changes are applied, or none of them are. Consistency guarantees that a transaction brings the database from one valid state to another. Isolation ensures that the execution of a transaction is independent of other transactions, and Durability guarantees that once a transaction is committed, its changes are permanent.
73. Why is the LIKE operator in SQL used?
Ans:
In SQL, rows can be filtered according to a specified pattern in a column by using the LIKE operator. With wildcard characters like ‘%’, which matches any character sequence, and ‘_’, which matches any single character, you can use it to perform pattern matching. This is especially helpful when looking for and getting data that matches certain textual requirements.
74. How do you add a new column to an existing table in SQL?
Ans:
- Start with ALTER TABLE: Begin the statement with ALTER TABLE.
- Specify Table Name: Indicate the name of the existing table you want to modify.
- Use ADD COLUMN: Follow with ADD COLUMN to signify you’re adding a new column.
- Specify Column Name: State the name of the new column you want to add.
75. How can duplicate records be removed from a table?
Ans:
The DELETE statement can be used in conjunction with a subquery or a common table expression (CTE) to remove duplicate records from a table. Based on predetermined criteria, the subquery or CTE finds duplicate records; the DELETE statement then eliminates those duplicates from the table, retaining only one instance of each unique record.
76. Give an explanation of what a SQL injection attack is.
Ans:
By injecting or modifying SQL code into a web application’s input fields, an attacker can take advantage of weaknesses in the program’s user input handling mechanism. This technique is known as SQL injection. This may result in data in the database being accessed improperly, manipulated, or even removed. An effective defence against SQL injection attacks is the use of parameterized queries and proper input validation.
77. What does a SELECT statement’s DISTINCT keyword do?
Ans:
Unique values can be retrieved from a given column or set of columns using the DISTINCT keyword in a SELECT statement. Every possible combination of values is represented only once thanks to the removal of duplicate rows from the result set. When you wish to, this is useful.
78. Create a query to identify staff members who are not part of any department.
Ans:
Choosing records from the “employees” table where the value in the “department_id” column is NULL is how a SQL query to find employees who are not assigned to any department is done. This presupposes that the “employees” table and the “departments” table are related by means of the database schema’s “department_id” column. The employee is not linked to any department, as indicated by the NULL value in the “department_id” column.
79. Write a query to find the third highest salary from an Employee table.
Ans:
- Select Distinct Salary: Choose unique salary values.
- Order by Descending: Arrange them in descending order.
- Limit 2: Exclude the top two salaries.
- Offset 1: Start from the third-highest salary.
- Retrieve Result: Get the one remaining row.
- Final Result: Obtain the third-highest salary.
80. Explain the concept of a primary key constraint.
Ans:
The primary key constraint in a relational database ensures the uniqueness of a column or a set of columns in a table. It serves as a unique identifier for each record in the table, and no two records can have the same primary key value. Additionally, a primary key column cannot contain NULL values, guaranteeing data integrity and providing a basis for establishing relationships between tables.
81. How do you create an index on a table column?
Ans:
To create an index on a table column in SQL, you use the CREATE INDEX statement. For example: “CREATE INDEX index_name ON table_name (column_name);” This enhances query performance by allowing the database engine to quickly locate rows based on the indexed column. Indexing is particularly useful for columns involved in search conditions and joins.
82. What is the purpose of the TRUNCATE statement in SQL?
Ans:
The TRUNCATE statement in SQL is used to quickly delete all rows from a table, but it differs from the DELETE statement. TRUNCATE is a more efficient operation as it doesn’t log individual row deletions and doesn’t generate as much overhead. However, TRUNCATE is unable to delete specific rows based on a condition, making it a suitable choice for removing all data from a table.
83. How do you retrieve the current date and time in SQL
Ans:
- MySQL: Retrieve the current date and time with SELECT NOW();.
- SQL Server: Obtain the current date and time using SELECT GETDATE();.
- Oracle: Fetch the current date and time with SELECT SYSDATE FROM DUAL;.
- PostgreSQL: Obtain the current timestamp through SELECT CURRENT_TIMESTAMP;.
- SQLite: Use SELECT DATETIME(‘now’); to get the current date and time.
84. Explain the concept of the CASE statement.
Ans:
The CASE statement in SQL is a conditional expression allowing the execution of different actions based on specified conditions. It is commonly used in SELECT, WHERE, and ORDER BY clauses. The syntax includes WHEN conditions with corresponding results, and an optional ELSE clause for a default result. It enhances query flexibility and readability, allowing dynamic decision-making within the query.
85.What is the difference between the RANK() and DENSE_RANK() functions?
Ans:
RANK():
- Assigns a unique rank to each distinct row.
- Skips ranks in case of ties.
- Next rank determined by adding the number of tied rows to the tied rank.
DENSE_RANK():
- Assigns a unique rank to each distinct row.
- Does not skip ranks in case of ties.
- Next rank determined by adding 1 to the tied rank.
86. Explain the difference between a candidate key, primary key, and super key.
Ans:
- Super Key: Any set of columns that uniquely identifies a record.
- Candidate Key: A minimal super key, chosen to be the primary key.
- Primary Key: The selected candidate key used to uniquely identify records in a table.
87. What is a CTE (Common Table Expression), and when would you use it?
Ans:
A Common Table Expression (CTE) is a named temporary result set in SQL, defined using the WITH clause. It enhances query readability, promotes modularity, and supports recursive queries. CTEs are beneficial for breaking down complex SQL queries into manageable and reusable components.
88. Explain the concept of a cross join.
Ans:
- Definition: A cross join in SQL, also known as a Cartesian join, combines every row from one table with every row from another table, producing the Cartesian product of the two tables.
- Use with Caution: Cross joins can generate large result sets, and their use should be approached with caution. They may lead to performance issues if the tables involved have a significant number of rows.
- No Join Condition: Unlike other join types, a cross join does not require a join condition based on common columns between the two tables. It simply combines all rows with all other rows.
89. Why is the SQL Server XML data type there?
Ans:
The SQL Server XML data type is utilized for the storage and manipulation of XML (eXtensible Markup Language) data inside the database. It makes it possible to store semi-structured and hierarchical data in a common format. When data must be represented in a nested or hierarchical structure, SQL Server’s ability to query and modify XML data makes it a valuable tool.
90. Describe what a composite key is.
Ans:
To uniquely identify a record in a table, two or more columns are combined to create a composite key in a relational database. A composite key, in contrast to a single-column primary key, consists of several columns, and the values in each of these columns must be distinct throughout the table. This idea is especially helpful in situations where no single column can ensure uniqueness on its own.




