
Last updated on 10th Oct 2025| 3245
- Deep Learning
- How do Spark and TensorFlow Simplify Deep Learning
- Large-Scale Feature Engineering and Data Preprocessing
- Two use cases and explain how you can use Spark
- Hyperparameter Tuning
- How do you choose the Right Hyperparameter?
- Monitoring and Debugging Distributed Deep Learning Jobs
- Deploying the Model and scale
- Evaluating deployments in spaces
- Important Lesson
Deep Learning
The last few years have seen deep Learning grow by leaps and bounds, and they are now at the forefront of automatic translation and image identification. Google recently launched TensorFlow, a new framework for numerical computation. In this blog post, we will demonstrate how to train and deploy deep learning models with TensorFlow and Spark combined. Networks are employed for deep learning, a subcategory of machine learning, to derive knowledge from data. Artificial intelligences, modeled after the human brain, can be applied to solve a variety of problems, including speech recognition, image recognition, and natural language processing core areas often explored in Machine learning training. Deep learning is more advanced and computationally expensive compared to conventional methods because it is a type of artificial intelligence with several layers of hidden layers. For faster training speeds, they perform efficiently with GPU-based designs and are applied in many applications. An artificial intelligence (AI) method known as deep learning teaches computers to process information in much the same way as the human brain. Deep learning models can produce accurate predictions and insights by recognizing subtle patterns in text, sounds, images, and more.
Ready to Get Certified in Machine Learning? Explore the Program Now Machine Learning Online Training Offered By ACTE Right Now!
How do Spark and TensorFlow simplify Deep Learning
The last few years have seen neural networks grow by leaps and bounds, and they are now at the forefront of automatic translation and image identification. Google recently launched TensorFlow, a new framework for neural networks and numerical computation. In this blog post, we will demonstrate how to train and deploy deep learning models with TensorFlow and Spark SQL combined. They are employed for deep learning, a subcategory to derives knowledge from data. Modeled after the human brain, it can be applied to solve a variety of problems, including speech recognition, image recognition, and processing. Deep neural networks are more advanced and computationally expensive compared to conventional networks because they are a type of artificial network with several layers of hidden layers a hallmark of modern Machine Learning Techniques.
- Organisations can effectively process enormous volumes of data with Deep Learning with Apache, allowing for better forecasts and more intelligent decision-making. In today’s data-driven environment, professionals who want to improve their abilities must learn Deep Learning with Apache methods.
- For faster training speeds, they perform efficiently with GPU-based designs and are applied in many applications. An artificial intelligence (AI) method known as deep learning teaches computers to process information in much the same way as the human brain.
Deep learning models can produce accurate predictions and insights by recognizing subtle patterns in text, sounds, images, and more. A Deep Learning Pipelines library created by Databricks cooperated very well with the ML Pipelines of Apache Spark. This was a solution to these issues. The best thing about these ML pipelines is that they automatically include APIs for saving your model, reloading it later, evaluating it, and finding parameters on multiple models.
Large-Scale Feature Engineering and Data Preprocessing
Data must be effectively cleaned, processed, and prepared before any deep learning model is trained. This section would discuss:
- Using Spark to handle missing data and normalisation.
- Utilising Spark MLlib to extract and convert features.
- Using the TensorFlow Data API to stream big data.
- Combining TensorFlow input pipelines with Spark pipelines to enable scalable preprocessing .
- Hyperparameter Tuning: Find the optimal set of hyperparameters to train a model on with Spark, which will lead to a 34% reduction in error rate and a 10X decrease in training time key outcomes often discussed when exploring What is Logistic Regression? Working through finding the optimal values of parameters that control a model’s learning process but aren’t learned from data itself is referred to as hyperparameter tuning in These parameters, or hyperparameters, are set before training and can significantly affect the performance of the model.
- Deploying Model and Scale: Run a trained model on a large dataset with Spark. Deploying at scale is when you can get enterprise-level deployments and top-tier development status within a small team of people running your CI/CD toolset.
To Explore Machine Learning in Depth, Check Out Our Comprehensive Machine Learning Online Training To Gain Insights From Our Experts!
Two use cases and explain how you can use Spark

Hyperparameter Tuning
Using Spark, there is a process called hyperparameter tuning. With the assistance of this technology, the ideal set of hyperparameters for training can be determined, resulting in a tenfold decrease in the training time. There is also a 34% reduction in the error rate, a result that highlights the impact of effective Machine learning training. ANNs, or AI, are what are applied when doing deep learning. Complex images are the inputs that experience intense mathematical transformations.
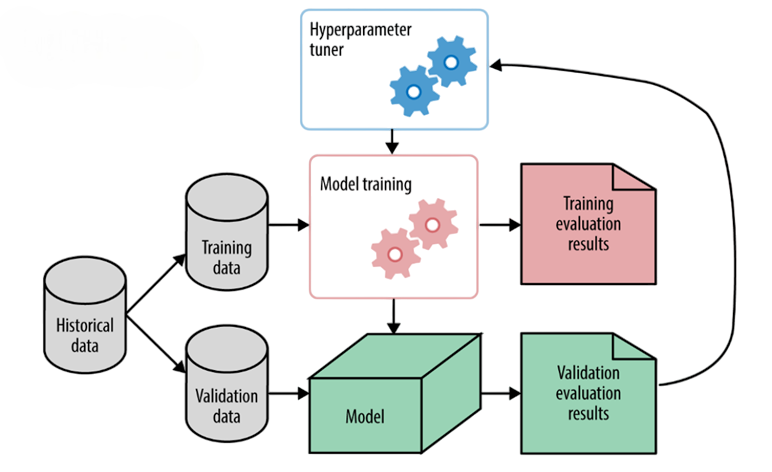
The final product is a vector of signals that machine learning algorithms can easily adjust. Artificial intelligence provides this transformation by duplicating the man how the human brain operates. The TensorFlow library facilitates automating training algorithm development for objects of varying sizes and shapes. Creating a model is a more sophisticated task than just applying a function to a dataset. Several hyperparameters can be used to enhance performance. To determine the best fit, professionals keep retraining the same model with multiple hyperparameters. Hyperparameter tuning.
How do you choose the Right Hyperparameter
When choosing the right hyperparameter, there are several things to consider.
- Number of neurons: A network with not enough neurons will contain less expression power, while a network with too many neurons will contain noise.
- Learning rate: They will only read the latest states when the learning rate is too high. But if it is too low, it will take a long time to reach a good state.
While TensorFlow itself is not distributed, the process of hyperparameters is a concept that also plays a key role in understanding Bagging vs Boosting in Machine Learning . This is why Apache Spark is used. It can be made possible to organize single repetitive computations across a collection of machines in a fault-tolerant manner using Spark to broadcast shared parts such as data and model description. With the standard set of hyperparameters, the accuracy is around 99.2%. As the number of nodes in the cluster increases, computations can be linearly scaled. Let us assume we can train 13 models in parallel with a 13-node cluster. Compared to training the models one machine at a time, this will lead to up to seven times higher performance.
Monitoring and Debugging Distributed Deep Learning Jobs
Training deep learning models on distributed systems can lead to complex issues. This section focuses on:
- Tools like TensorBoard for monitoring model performance.
- Logging and debugging in a Spark-TensorFlow hybrid setup.
- Handling memory, latency, and GPU utilization issues.
- Best practices for error tracking in distributed environments.
Deploying the Model and scale
TensorFlow models can be readily incorporated into pipelines to carry out intricate dataset recognition tasks, much like traditional approaches such as Support Vector Machine (SVM) . We demonstrate how to label a set of photographs from a pre-trained stock model as an example. A single copy of the asset is distributed by default when you establish a Python online deployment for a model, function, or Shiny app programmatically or from a deployment area. By modifying the deployment configuration, you can increase the number of copies (replicas) to improve scalability and availability. A higher volume of score requests is possible with more copies.
In a deployment space, update the deployment’s configuration. Programmatically, either the Watson Machine Learning REST APIs or the Watson Python client library.
Preparing for Machine Learning Job Interviews? Have a Look at Our Blog on Machine Learning Interview Questions and Answers To Ace Your Interview!
Evaluating deployments in spaces
To activate all of the monitoring capabilities, create a deployment space and associate an instance with it. If you require it, you can choose a space type, such as PyTorch production or pre-production.
- Create an online deployment for a trained machine Learning model and upload input (payload) data to the deployment area.
- The deployment: Select the Test tab, input the data, and get the predictions.
- Set up the evaluation to monitor the quality, fairness, and explainability of your deployment from the Evaluations tab.
- Provide Watson OpenScale with all model information it requires to communicate with the model, training, and payload data, and a store for assessment results in PyTorch.
To make sure your model is producing fair results, establish a monitor for fairness. Define thresholds to compare predictions for a monitored group with a reference group after selecting the fields to monitor for fairness. For example, you can put your PyTorch model to the test to make sure it is producing gender-blind predictions.
Important Lesson
The notion that deep learning is the future of artificial intelligence is being reasserted. No one had ever thought before that driverless cars would be possible. They are a cruel reality now! Several large players in the IT sector are enhancing the TensorFlow library, further emphasizing the growing importance of Machine learning training. MXNet, which can be accessed through Amazon, runs smoothly on multiple nodes. Deep learning research is continuous, so it should not be surprising that TensorFlow and Deep Learning Pipelines provide an easy way to develop increasingly sophisticated Deep Learning applications when new libraries become available. Spark will have the spotlight in order to satisfy the high-speed parallel processing needs of such applications.




