
Last updated on 08th Jul 2020| 2588
In Apache Cassandra data modelling play a vital role to manage huge amount of data with correct methodology. Methodology is one important aspect in Apache Cassandra. Data modelling describes the strategy in Apache Cassandra.
Conceptual Data Model:
Conceptual model is an abstract view of your domain. It is Technology independent. Conceptual model is not specific to any database system.
Purpose:
- To understand data which is applicable for data modeling.
- To define Essential objects.
- To define constraints which is applicable for data modeling.
Cassandra data Models Rules
- Cassandra doesn’t support JOINS, GROUP BY, OR clause, aggregation etc. So you have to store data in a way that it should be retrieved whenever you want.
- Cassandra is optimized for high write performances so you should maximize your writes for better read performance and data availability. There is a trade off between data write and data read. So, optimize you data read performance by maximizing the number of data writes.
- Maximize data duplication because Cassandra is a distributed database and data duplication provides instant availability without a single point of failure.
- The Cassandra data model and on disk storage are inspired by Google Big Table and the distributed cluster is inspired by Amazon’s Dynamo key-value store. Cassandra’s flexible data model makes it well suited for write-heavy applications.
Cassandra Data Modeling – Best Practices
- Picking the right data model helps in enhancing the performance of the Cassandra cluster. In order to come up with a good data model, you need to identify all the queries your application will execute on Cassandra.
- You should model Cassandra data model around your queries, but not around objects or relations.
Choose the Proper Row Key
- The critical part of Cassandra data modeling is to choose the right Row Key (Primary Key) for the column family. The first field in Primary Key is called the Partition Key and all other subsequent fields in primary key are called Clustering Keys.
- The Partition Key is useful for locating the data in the node in a cluster, and the clustering key specifies the sorted order of the data within the selected partition. Selecting a proper partition key helps avoid overloading of any one node in a Cassandra cluster.
- CREATE TABLE Employees (
- emp_id uuid,
- first_name text,
- last_name text,
- email text,
- phone_num text,
- age int PRIMARY KEY (emp_id, email, last_name)
- )
Here the Primary Key has three fields:
- emp_id is the partition key, and email and last_name are clustering keys. Partitioning is done by emp_id and within that partition, rows are ordered by the email and last_name columns.
Determine queries first, then model it
- In relational databases, the database schema is first created and then queries are created around the DB Schema. In Cassandra, schema design should be driven by the application queries.
Duplicate the data
- In relational databases, data normalization is a best practice, but in Cassandra data duplication is encouraged to achieve read efficiency.
Garbage collector
- Garbage collection (GC) is the process by which Java removes objects that don’t have any references in the heap memory. Garbage collection pauses (Stop-the-world events) can create latencies in read and write queries.
- There are two major types of garbage collection algorithms, G1 garbage collector and CMS (Concurrent Mark and Sweep) garbage collector. G1 GC gives better performance than CMS for large heap sizes but the tradeoff is longer GC times as better explained in this page. Choose right GC for your use case.
Keyspace replication strategy
Use SimpleStrategy for single data center replication.
Use NetworkTopologyStrategy for multi-data center replication.
Payload
- If your query response pay load size is over 20 MB, consider additional cache or change in query pattern. Cassandra is not great at handling larger payloads.
Data Modeling Goals
You should have following goals while modeling data in Cassandra:
- Spread Data Evenly Around the Cluster: To spread equal amount of data on each node of Cassandra cluster, you have to choose integers as a primary key. Data is spread to different nodes based on partition keys that are the first part of the primary key.
- Minimize number of partitions read while querying data: Partition is used to bind a group of records with the same partition key. When the read query is issued, it collects data from different nodes from different partitions.
- In the case of many partitions, all these partitions need to be visited for collecting the query data. It does not mean that partitions should not be created. If your data is very large, you can’t keep that huge amount of data on the single partition. The single partition will be slowed down. So you must have a balanced number of partitions.

Get Apache Cassandra Training From Real-Time Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
How to model the data in Cassandra?
A good data modelling follows these steps
- Conceptualize the queries required by your application
- Creating tables to satisfy those queries
- Before we apply these rules, one thing to keep in mind is, “We focus on optimizing our read operations even if it requires data duplication”. We can have many tables that may contain almost similar data.
- Now, consider we want a database that stores information on restaurants. Let us put a constraint that restaurant names have to be unique.
- The table below can be used when we want to lookup based on the restaurant name:
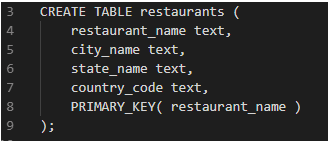
- Now if we want to look up the restaurants for a particular location, we would write a query that iterates through all the rows and retrieves restaurant names.
- Instead, keeping in mind #2 rule, we can easily create another table that will serve our need.
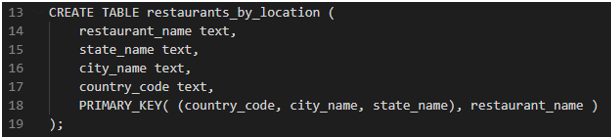
- Now our data will be partitioned in a way that a node in the cluster will have restaurants for a particular location. This will optimize our read queries, as query lookup will only happen on one node with much lesser rows than the first table we created.
- What if we wanted to search restaurants in a particular city we can make another table rather than iterating through all the rows in a single partition of the above table.
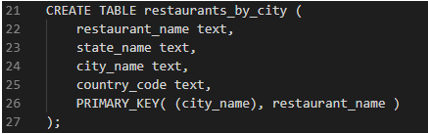
Good Primary Key
Let’s take an example and find which primary key is good.
Here is the table MusicPlaylist.
- Create table MusicPlaylist
- (
- SongId int,
- SongName text,
- Year int,
- Singer text,
- Primary key(SongId, SongName)
- );
In above example, table MusicPlaylist,
- Songid is the partition key, and
- SongName is the clustering column
- Data will be clustered on the basis of SongName. Only one partition will be created with the SongId. There will not be any other partition in the table MusicPlaylist.
Data retrieval will be slow by this data model due to the bad primary key.
Here is another table MusicPlaylist.
- Create table MusicPlaylist
- (
- SongId int,
- SongName text,
- Year int,
- Singer text,
- Primary key((SongId, Year), SongName)
- );
Handling One to One Relationship
- One to one relationship means two tables have one to one correspondence. For example, the student can register only one course, and I want to search on a student that in which course a particular student is registered in.
- So in this case, your table schema should encompass all the details of the student in corresponding to that particular course like the name of the course, roll no of the student, student name, etc.

- Create table Student_Course
- (
- Student rollno int primary key,
- Student_name text,
- Course_name text,
- );
Handling one to many relationships
- One to many relationships means having one to many correspondence between two tables.
- For example, a course can be studied by many students. I want to search all the students that are studying a particular course.
- So by querying on course name, I will have many student names that will be studying a particular course.
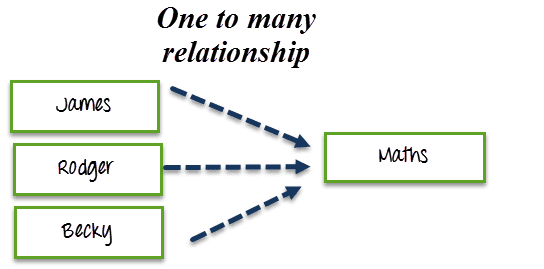
Create table Student_Course
- Create table Student_Course
- (
- Student_rollno int,
- Student_name text,
- Course_name text,
- );
I can retrieve all the students for a particular course by the following query.
- Select * from Student_Course where Course_name=’Course Name’;
Handling Many to Many Relationship
- Many to many relationships means having many to many correspondence between two tables.
- For example, a course can be studied by many students, and a student can also study many courses.
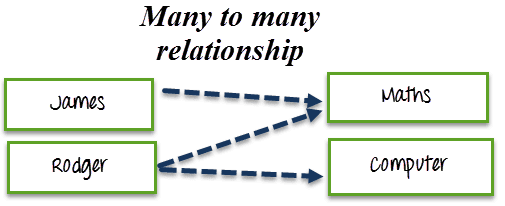
- I want to search all the students that are studying a particular course. Also, I want to search all the course that a particular student is studying.
- So in this case, I will have two tables i.e. divide the problem into two cases.
- First, I will create a table by which you can find courses by a particular student.
- Create table Student_Course
- (
- Student_rollno int primary key,
- Student_name text,
- Course_name text,
- );
I can find all the courses by a particular student by the following query.
- –>
- Select * from Student_Course where student_rollno=rollno;
- Second, I will create a table by which you can find how many students are studying a particular course.
Create table Course_Student
- (
- Course_name text primary key
- Student_name text,
Upcoming Batches
| Name | Date | Details |
|---|---|---|
27 - July - 2026(Weekdays) Weekdays Regular |
||
29 - July - 2026(Weekdays) Weekdays Regular |
||
01 - Aug - 2026(Weekends) Weekend Regular |
||
02 - Aug - 2026(Weekends) Weekend Fasttrack |




