
Last updated on 29th Sep 2025| 12306
- Introduction to Ensemble Learning
- Understanding Decision Trees
- What is the Random Forest Algorithm?
- How Random Forest Works
- Key Parameters in Random Forest
- Advantages of Using Random Forest
- Implementing Random Forest Algorithm in Python
- Feature Importance
- Real-World Use Cases
- Summary
Introduction to Ensemble Learning
In the world of machine learning, achieving high prediction accuracy is a key goal. One of the ways to boost model performance is by using ensemble learning techniques. Ensemble learning involves combining predictions from multiple machine learning algorithms to produce a more accurate and reliable output. This approach leverages the wisdom of crowds by aggregating the decisions of multiple models, we can often outperform a single model. Ensemble methods are typically classified into two major types: bagging and boosting. Bagging, or Bootstrap Aggregating, focuses on reducing variance by training multiple models independently on random subsets of data. To implement these techniques effectively, exploring Python Training reveals how mastering libraries like scikit-learn and XGBoost empowers learners to build robust ensemble models and fine-tune performance across diverse datasets. Boosting, on the other hand, focuses on reducing bias by training models sequentially, where each new model tries to correct errors made by the previous one. Random Forest is one of the most powerful and widely used bagging ensemble algorithms. It combines the predictions of multiple decision trees to provide a stable and accurate prediction model.
Interested in Obtaining Your Python Certificate? View The Python Developer Course Offered By ACTE Right Now!
Understanding Decision Trees
To understand Random Forest, we must first understand decision trees. A decision tree is a flowchart-like structure where internal nodes represent a feature (attribute), branches represent decisions or conditions, and leaf nodes represent an output label. It splits the dataset into subsets based on feature values and continues splitting recursively to build a tree structure.
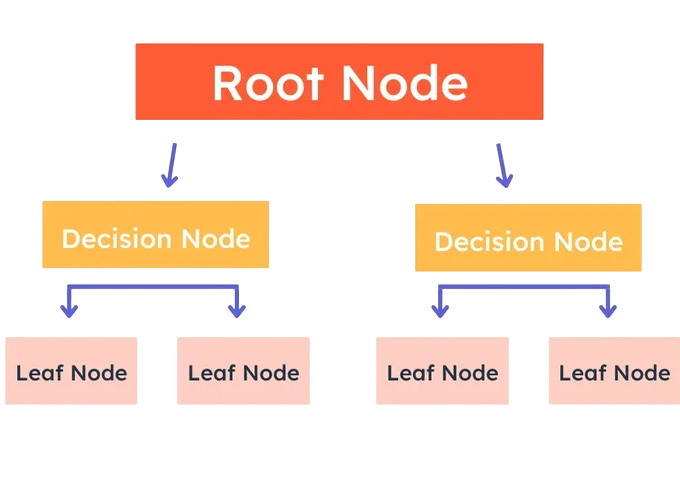
To understand how such models mirror foundational concepts in computer science, exploring Types of Trees in Data Structure reveals how binary trees, AVL trees, and B-trees organize hierarchical data providing the backbone for decision-making algorithms like Random Forest. Although decision trees are easy to understand and visualize, they are prone to overfitting, especially when the tree becomes too deep and complex. Overfitting means the model performs well on training data but poorly on unseen data. This is where Random Forest offers a solution.
What is the Random Forest Algorithm?
Random Forest Algorithm is an ensemble algorithm that builds multiple decision trees and merges their results to get a more accurate and stable prediction. It uses two main techniques to introduce randomness: bootstrapping and feature selection. To ensure these models remain resilient under sudden load conditions, exploring What is Spike Testing reveals how systems are evaluated for performance and stability when exposed to abrupt, extreme traffic surges critical for maintaining reliability in real-time prediction environments.
- Bootstrap Sampling: Each tree is trained on a different random subset of the original data (with replacement).
- Random Feature Selection: At each split in a tree, only a random subset of features is considered.
This approach reduces the correlation between individual trees, leading to improved model generalization. By aggregating the predictions of many uncorrelated trees, Random Forest reduces variance and avoids overfitting.
Gain Your Master’s Certification in Python Developer by Enrolling in Our Python Master Program Training Course Now!
How Random Forest Works
The Random Forest algorithm is based on the bagging technique. Here’s how it works: it creates multiple decision trees using random subsets of data and features, then aggregates their outputs for improved accuracy. To manage collaborative development and track changes in machine learning projects, exploring Git and Version Control reveals how tools like Git streamline code management, enable branching strategies, and ensure reproducibility across data science workflows.
- From the original dataset: Create n random samples (bootstrap datasets).
- Train a decision tree: On each of these bootstrap samples.
- At each node: Instead of evaluating all features, evaluate a random subset of features.
- Aggregate the predictions: Use majority voting for classification. Use the average of all the predictions for regression.
The diversity introduced by bootstrapping and random feature selection ensures that the ensemble model is less likely to overfit and performs better on test data.

Develop Your Skills with Python Developer Certification Course
Weekday / Weekend BatchesSee Batch DetailsKey Parameters in Random Forest
Random Forest Algorithm in Python can be fine-tuned using several key parameters: the number of trees (n_estimators), maximum depth (max_depth), and minimum samples per leaf (min_samples_leaf). These adjustments help balance bias and variance, improving model accuracy. To master such techniques and apply them confidently, exploring Python Training reveals how hands-on experience with machine learning libraries like scikit-learn empowers learners to build, tune, and deploy predictive models effectively.
- n_estimators: Number of trees in the forest. Higher values improve performance but increase computational cost.
- max_depth: Maximum depth of each tree. Limits the number of splits to prevent overfitting.
- min_samples_split: Minimum number of samples required to split a node.
- min_samples_leaf: Minimum number of samples required at a leaf node.
- max_features: Number of features to consider for the best split. Common options are auto, sqrt, and log2.
- bootstrap: Whether to use bootstrap samples for training.
- random_state: Controls randomness for reproducibility.
Tuning these hyperparameters allows the model to adapt to different datasets and balance bias-variance tradeoffs.
Are You Preparing for Python Jobs? Check Out ACTE’s Python Interview Questions and Answers to Boost Your Preparation!
Advantages of Using Random Forest
Random Forest is a popular tool among machine learning users because of its many benefits. First, it has high accuracy and often outperforms other models, even with default settings. This model is also resistant to noise, greatly lowering the chances of overfitting compared to single decision trees.

Additionally, Random Forest ranks features by their importance, helping users see how they affect the model’s predictions. It can handle large datasets with thousands of input features and can manage missing values in some cases. To integrate such predictive models into enterprise applications, exploring What is WSDL in Web Services reveals how the Web Services Description Language defines service endpoints and operations enabling seamless communication between machine learning APIs and distributed systems.
Implementing Random Forest Algorithm in Python
Here is a basic example of implementing Random Forest for classification using scikit-learn: import the dataset, split it into training and testing sets, fit the model, and evaluate accuracy. While Python handles model logic, Java-based projects often rely on build tools for automation and dependency management. Exploring Gradle vs Maven reveals how these tools differ in configuration style, performance, and flexibility helping developers choose the right build system for integrating machine learning workflows into enterprise applications.
- from sklearn.ensemble import RandomForestClassifier
- from sklearn.datasets import load_iris
- from sklearn.model_selection import train_test_split
- from sklearn.metrics import accuracy_score
- # Load dataset
- iris = load_iris()
- X = iris.data
- y = iris.target
- # Train-test split
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
- # Create Random Forest model
- model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=42)
- model.fit(X_train, y_train)
- # Predict and evaluate
- y_pred = model.predict(X_test)
- print(“Accuracy:”, accuracy_score(y_test, y_pred))
For regression, you can use RandomForestRegressor with similar syntax.
Feature Importance
Random Forest provides a way to assess the importance of each feature: it helps identify which inputs most influence the model’s predictions. While Random Forest handles decision-making through ensemble learning, mastering algorithmic problem-solving techniques is equally vital. Exploring Dynamic Programming Explained reveals how breaking problems into overlapping subproblems and storing intermediate results leads to optimized solutions essential for tackling complex challenges in data science and software engineering.
- import matplotlib.pyplot as plt
- import numpy as np
- features = iris.feature_names
- importances = model.feature_importances_
- indices = np.argsort(importances)[::-1]
- plt.figure()
- plt.title(“Feature Importances”)
- plt.bar(range(X.shape[1]), importances[indices], align=”center”)
- plt.xticks(range(X.shape[1]), [features[i] for i in indices], rotation=45)
- plt.tight_layout()
- plt.show()
This feature ranking can help with feature selection and understanding model behavior.
Real-World Use Cases
Random Forest is widely used across various domains: healthcare for disease prediction, finance for fraud detection, and marketing for customer segmentation. These models often run in automated pipelines or scheduled tasks. To manage execution timing and simulate delays in such workflows, exploring Python Sleep Method reveals how developers can pause program execution using time.sleep() a simple yet powerful tool for throttling requests, pacing loops, and coordinating asynchronous operations.
- Healthcare: Disease prediction, patient risk analysis.
- Finance: Credit scoring, fraud detection, loan approval.
- Marketing: Customer segmentation, churn prediction.
- E-commerce: Product recommendation, inventory forecasting.
- Cybersecurity: Threat detection, intrusion classification.
- Agriculture: Crop yield prediction, soil quality classification.
Its ability to handle both classification and regression, combined with high accuracy, makes it a go-to solution for diverse applications.
Summary
Random Forest Algorithm is a flexible algorithm known for its strong performance and ease of use. It performs well with large datasets that have many features or when the data is noisy. This model gives solid results right away, making it a good option for setting a baseline in both classification and regression tasks. It also offers useful insights through feature importance reports, which help you see which variables are most important for your predictions. To build and deploy such models effectively, exploring Python Training reveals how mastering libraries like scikit-learn, pandas, and NumPy equips learners with the skills needed for data analysis, machine learning, and real-world problem solving. However, you should avoid using Random Forest Algorithm if you need clear model interpretation or if your application requires real-time predictions. It is less effective for sparse and text-heavy data. Overall, with its mix of simplicity, flexibility, and strong results, Random Forest is a popular choice in data science and machine learning.




