
Last updated on 24th Sep 2025| 12311
- Introduction to HashMap
- Structure and Working
- Hash Function and Buckets
- Key-Value Pair Management
- Null Keys and Values
- Iterating a HashMap
- Performance Considerations
- Collision Handling in Java
- Conclusion
Introduction to HashMap
A HashMap is a part of Java’s java.util package and is one of the most commonly used data structures for storing key-value pairs. It provides an efficient way to store, retrieve, and manipulate data based on unique keys. Internally, HashMap uses a technique called hashing, where the key is processed through a hash function to determine the index in a bucket array where the value will be stored. HashMap allows constant-time complexity (O(1)) for most operations like get() and put(), making it ideal for scenarios Java Training where fast data access is critical. It does not maintain any order of keys or values and allows one null key and multiple null values. When multiple keys produce the same hash (a collision), HashMap handles it using chaining (via a linked list or tree structure, depending on the version of Java). It’s widely used in caching, database indexing, and applications where data is retrieved frequently using keys. Unlike Hashtable, HashMap is not synchronized, which means it is not thread-safe unless externally synchronized or used with ConcurrentHashMap in multithreaded environments. Understanding how HashMap works internally is essential for writing efficient and optimized Java applications.
To Earn Your Java Training Certification, Gain Insights From Leading Web Developer Experts And Advance Your Career With ACTE’s Java Training Today!
Structure and Working
- Key-Value Pairs: HashMap stores data as pairs, where each unique key maps to a specific value.
- Hash Function: A hash function is used to convert the key into a hash code, which determines the index in the internal array.
- Bucket Array: Internally, Exploring Software Engineering HashMap uses an array of buckets where each bucket can hold one or more entries.
- Collision Handling: When multiple keys hash to the same index, collisions are handled using chaining (linked lists or trees in Java 8+).
- Dynamic Resizing: When the number of entries exceeds the load factor threshold, the HashMap resizes (doubles its capacity) and rehashes the entries.
Hash Function and Buckets
A hash function is crucial to the working of HashMap. It determines the distribution of keys across the array of buckets. Java’s HashMap uses the hashCode() method of the key object to calculate the hash, and then applies a supplemental hash function to reduce collisions and evenly distribute entries. The result is then mapped to an index in the bucket array using the modulo operation. For instance, if the array length is 16, the index is computed as hash % 16. A good hash function minimizes collisions StringBuilder , thereby improving the performance of the HashMap. The quality of the hash function directly affects the time complexity of put and get operations.
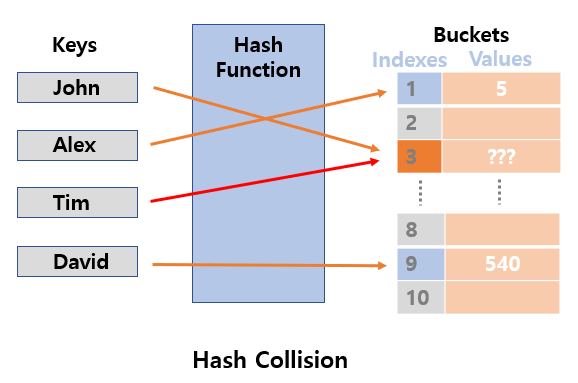
In a HashMap, a hash function converts a key into a fixed-size integer known as a hash code. This hash code determines the index in an internal array called buckets, where the key-value pair will be stored. Each bucket can hold multiple entries, especially in cases of collisions, where different keys generate the same index. Efficient hash functions aim to distribute keys uniformly across buckets to minimize collisions. When collisions do occur, Java handles them using chaining with linked lists or balanced trees. This mechanism ensures quick access, insertion, and deletion of elements within the HashMap.
Would You Like to Know More About Java Training? Sign Up For Our Java Training Now!
Key-Value Pair Management
- Insertion (put() method): Stores a value associated with a unique key. If the key already exists, the value is updated.
- Retrieval (get() method): Retrieves Pointers in C the value mapped to a specific key using hashing for fast access.
- Updating Values: Using the same key with a new value replaces the existing value in the map.
- Deletion (remove() method): Removes the key and its associated value from the HashMap.
- Key Uniqueness: Each key in a HashMap must be unique; duplicate keys are not allowed.

Null Keys and Values
Unlike some map implementations, HashMap allows one null key and multiple null values. When a null key is inserted, it is always placed in the first bucket (bucket[0]). This is because the hashCode() method cannot be called on a null key. Instead, HashMap uses a special case to handle null keys by assigning them a hash value of 0. This feature can be useful but requires careful consideration, especially in applications where nulls are used frequently, as it could lead to bugs or misunderstandings about the behavior of the map Java Training. A HashMap in Java allows one null key and multiple null values. When a null key is inserted, it is always placed in the first bucket (index 0), as it doesn’t go through the standard hash function. This special handling ensures that only one null key can exist at a time. However, values in a HashMap can be null without restrictions, allowing multiple keys to map to null. While convenient, excessive use of nulls can lead to NullPointerException during operations like iteration or key comparisons, so careful handling is recommended in production code.
Iterating a HashMap
- Using entrySet() with for-each loop – Iterate over key-value pairs efficiently.
- Using keySet() – Iterate only through the keys of the map Linux Operating System .
- Using values() – Iterate through only the values in the map.
- Using Iterator with entrySet() – Allows safe removal of entries during iteration.
- Using forEach() with Lambda (Java 8+) – A concise, functional way to iterate.
Are You Interested in Learning More About FullStack With Java Training? Sign Up For Our Java Training Today!
Performance Considerations
- Load Factor: Controls when resizing occurs; a lower load factor reduces collisions but increases memory usage.
- Initial Capacity: Setting an appropriate initial size minimizes costly resizing operations.
- Hash Function Quality: A good hash function distributes keys uniformly, React Hooks reducing collisions and improving performance.
- Collision Handling: Excessive collisions degrade performance from O(1) to O(n); modern Java uses balanced trees for high-collision buckets.
- Thread Safety: HashMap is not synchronized; using it in concurrent scenarios without proper synchronization can cause data inconsistency and performance issues.
Collision Handling in Java
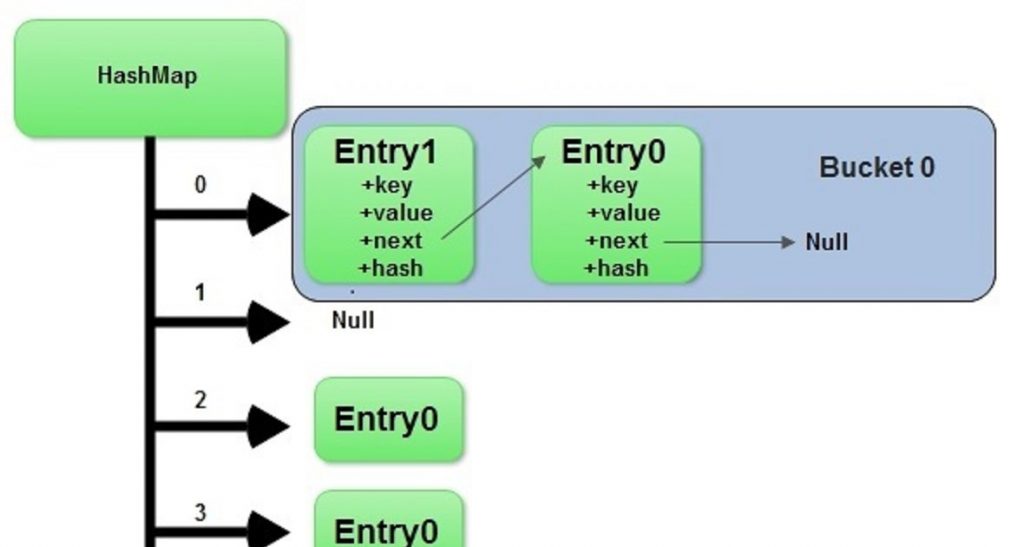
Collision Handling in Java occur when different keys produce the same hash index. HashMap handles collisions using chaining, where each bucket contains a list (or tree) of entries. In Java versions prior to 8, this was a simple linked list, which could lead to poor performance with many collisions. Java 8 improved this by using balanced trees (red-black trees) when the number of entries in a bucket exceeds 8 and the total number of buckets is at least 64. This transition ensures O(log n) time complexity for those buckets. Collision handling is vital for the robustness and Break and Continue In C efficiency of HashMap, and understanding it helps developers design better-performing applications. In Java’s HashMap, a collision happens when two different keys produce the same hash code, mapping to the same bucket. To handle collisions, HashMap uses chaining, where collided entries are stored in a linked list within that bucket. Starting from Java 8, Iterating a HashMap if the number of collisions in a bucket exceeds a threshold (typically 8), the linked list transforms into a balanced red-black tree to improve lookup performance from O(n) to O(log n). Additionally, when the load factor exceeds a set limit, the HashMap resizes and rehashes entries to spread data evenly, minimizing collisions and maintaining efficiency.
Preparing for Java Job Interviews? Have a Look at Our Blog on Java Training Interview Questions and Answers To Ace Your Interview!
Conclusion
HashMap in Java is a powerful and flexible tool for handling key-value pairs efficiently. Understanding its internal structure, behavior, and best use practices can greatly improve the performance and reliability of Java applications. With proper implementation and attention to performance and thread-safety considerations, HashMap remains one of the most effective data structures in the Java programmer’s toolkit. In conclusion, Java Training HashMap is a powerful and widely used data structure in Java that offers efficient key-value storage with fast access times. Understanding its internal workings including hashing, collision handling, load factors, and resizing is essential for writing optimized and reliable applications. While HashMap excels in speed, proper management of collisions and awareness of thread safety are crucial. By mastering these concepts, developers can effectively leverage HashMap to build scalable and high-performance software.




