
Last updated on 26th Sep 2025| 12583
- Hash Table Defined
- Explanation of Hash Functions
- Handling Collisions (Chaining, Open Addressing)
- Understanding Load Factor
- Hash Table vs Array vs Map
- Implementation in Java (HashMap)
- Operations: Insert, Search, Delete
- Rehashing Mechanics
- Real-World Applications
- Conclusion
Hash Table Defined
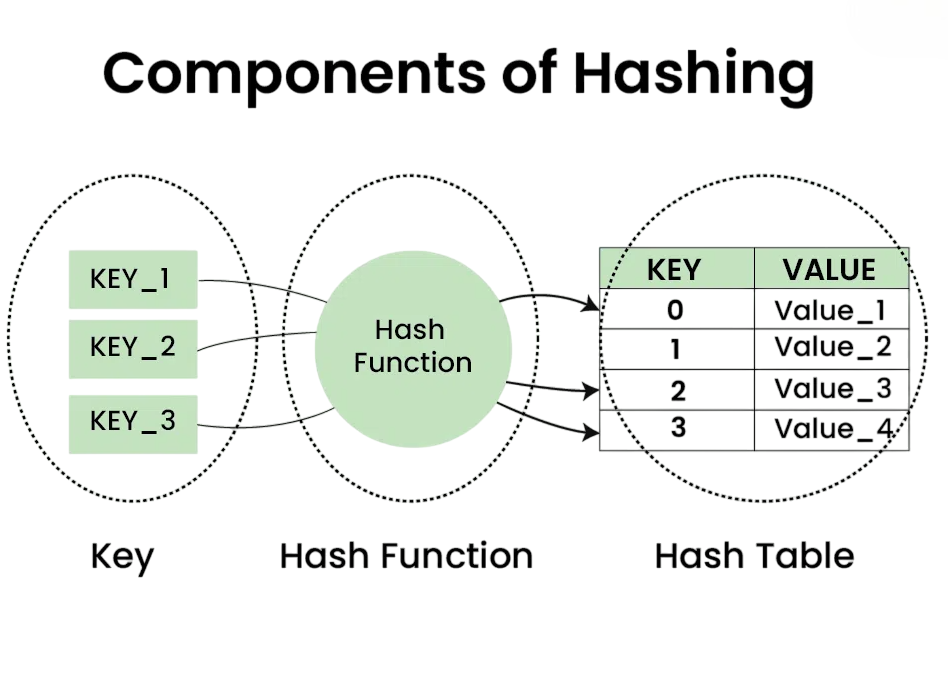
Hash tables are an important tool in computer science. They are valued for their efficiency in storing and retrieving data. They combine arrays with hash functions, which allow for nearly constant time access, or O(1) on average. Consider how you search in a dictionary or look up a contact on your phone. This is similar to how hash tables link unique keys to their corresponding values for quick lookups. In a hash table, each key acts as a unique identifier that points to its associated value, which holds the actual data you want to access. To master such data structures and their practical applications, exploring Python Training reveals how dictionaries, sets, and other built-in types enable efficient storage, retrieval, and manipulation of data making Python a powerful tool for both beginners and professionals.
Example:
- Key → “apple”
- Hash → 42
- Index → 42 % table_size = 2
- Value → “A sweet red fruit”
Interested in Obtaining Your Python Certificate? View The Python Developer Course Offered By ACTE Right Now!
Explanation of Hash Functions
A hash function is important in computer science because it converts a key, such as a string, number, or object, into a unique integer called a hash code. This hash code is then turned into a valid index for a hash table using modulo division. A good hash function makes sure that keys are evenly spread throughout the table, which helps keep things efficient. To explore hierarchical alternatives to flat hashing, Types of Trees in Data Structure reveals how binary trees, AVL trees, and B-trees organize data for faster search, balanced storage, and scalable indexing across complex systems. It also reduces collisions, which happen when different keys mistakenly point to the same index. This prevents data overlap and loss. Furthermore, an effective hash function is quick to compute, making data retrieval faster and more efficient. By focusing on these qualities, developers can build strong systems that improve performance and reliability.
Example:
- int hashCode = key.hashCode(); // Java’s built-in method
- int index = Math.abs(hashCode) % tableSize;
Handling Collisions
Even with a good hash function, collisions are inevitable because multiple keys may map to the same index. To understand how such scenarios are handled in real-world applications, exploring Python Training reveals how dictionaries resolve collisions using techniques like chaining and open addressing empowering developers to build efficient, reliable data structures for scalable software systems.
Collision resolution strategies include:
- Chaining: Each table slot stores a linked list (or another dynamic structure) of entries. If multiple keys hash to the same index, they are added to the list.
- Open Addressing: Instead of using linked lists, it searches for another open slot in the array.
Example:
- Index 2 → (“apple”, “A fruit”) → (“mango”, “Another fruit”).
- If index 5 is full, try 6, then 7, etc. (linear probing).
Common techniques:
- Linear Probing: Move sequentially until an empty slot is found.
- Quadratic Probing: Jump in quadratic intervals to reduce clustering.
- Double Hashing: Use a second hash function to find new positions.
- loadFactor = numberOfElements / tableSize
- More collisions.
- Possible performance degradation.
- import java.util.HashMap;
- public class HashTableExample {
- public static void main(String[] args) {
- HashMap<String, String> fruitMap = new HashMap<>();
- // Insert
- fruitMap.put(“apple”, “A sweet red fruit”);
- fruitMap.put(“banana”, “A yellow fruit”);
- // Search
- String value = fruitMap.get(“apple”);
- System.out.println(“Value: ” + value);
- // Delete
- fruitMap.remove(“banana”);
- }
- }
- In a hash table, inserting a key-value pair starts with calculating the hash code of the key. This hash code helps find the index where the pair will be stored. If needed, collision handling methods are used to ensure that all entries can be stored correctly, even when different keys map to the same index. The average time complexity for this insertion process is O(1), but it can drop to O(n) in the worst case if many keys collide.
- When searching for a key, the index is quickly calculated using the hash code, allowing for fast comparisons of keys until a match is found. This search operation usually keeps an average time complexity of O(1), making it a quick process.
- To understand how such efficient lookup mechanisms scale across distributed systems, exploring What are Microservices reveals how loosely coupled services communicate via lightweight protocols, enabling rapid data access, modular deployment, and fault-tolerant architecture in modern applications.
- For deletion, the first step is to find the key in the table. After locating it, the entry is removed, and any necessary updates are made to the structure, whether by updating pointers in a method that uses chaining or marking the slot as empty in open addressing. This structured approach helps hash tables stay efficient for different operations and effective in managing data.
- Databases: Indexing for quick record retrieval.
- Compilers: Symbol tables for variable/function lookups.
- Caching: Storing recent computations or web data.
- Password storage: Using cryptographic hash functions.
- Routers: IP address lookups in routing tables.
Gain Your Master’s Certification in Python Developer by Enrolling in Our Python Master Program Training Course Now!
Understanding Load Factor
The load factor is an important concept in data structures, especially for hash tables. It represents the ratio of stored elements to the total capacity. For instance, if a hash table holds 10 items but currently stores 4, the load factor is 0.4. Knowing this ratio helps manage hash table performance. A low load factor means the table is underused, leading to wasted memory. On the other hand, a high load factor raises the chance of collisions, where multiple items try to fit into the same index, causing slower performance. To optimize such operations at the binary level, exploring Guide to Bitwise Operators in C Programming reveals how AND, OR, XOR, and shift operators enhance performance, enable efficient indexing, and support low-level data manipulation in hash-based systems.
Formula:

Develop Your Skills with Python Developer Certification Course
Weekday / Weekend BatchesSee Batch DetailsHash Table vs Array vs Map
| Feature | Array | Map | Hash Table |
|---|---|---|---|
| Key Type | Index only (int) | Key-Value | Key-Value |
| Lookup Time | O(1) | Depends on type | O(1) avg |
| Flexibility | Fixed index type | Flexible | Flexible |
| Collision Handling | N/A | Depends | Needed |
Are You Preparing for Python Jobs? Check Out ACTE’s Python Interview Questions and Answers to Boost Your Preparation!
Implementation in Java (HashMap Example)
Java’s HashMap is well-known as the most common hash table in the Java programming language. It lets developers store key-value pairs, making data retrieval quick and efficient. When you add a value to a HashMap, you link it with a unique key. This setup allows you to access that value easily when you need it. Essentially, HashMap uses a hashing method to handle the data efficiently, so actions like adding, removing, and looking up data typically happen in constant time. To understand how optimal choices at each step can lead to efficient outcomes, exploring Greedy Algorithms Work reveals how this strategy simplifies problem-solving in areas like resource allocation, scheduling, and data lookup often aligning with the constant-time efficiency seen in hash-based structures. However, keep in mind that the order of elements in a HashMap is not guaranteed, which can matter in some cases. Knowing how HashMap works can improve your programming efficiency and performance.
Example:
Operations: Insert, Search, Delete
Rehashing Mechanics
Rehashing is an important part of managing hash tables. This process becomes necessary when the load factor goes over a certain limit and performance starts to decline due to collisions.
First, you need to create a new array that is usually double the size of the original. A larger size helps lower the chance of collisions and improves efficiency. Next, you must recompute the hash values for each key in the old table. To manage such iterative changes with precision, exploring Git and Version Control reveals how branching, commits, and rollback mechanisms help developers track modifications, optimize workflows, and maintain consistency across evolving codebases. This step ensures that each key is placed correctly in the new, larger array. Finally, you will insert the keys into the new table based on their newly calculated hashes. By following these steps, you can effectively improve the performance of your hash table and keep it running smoothly as your data increases.
Real-World Applications
Conclusion
Hash tables are a useful tool in programming for storing and retrieving data efficiently. They map unique keys to specific values, which allows for quick lookups. One of the key benefits of hash tables is their average time complexity of O(1) for operations like adding, removing, or finding items, making them some of the fastest data structures available. They find applications in various areas, such as compilers and caching systems. To build and optimize such systems using modern programming tools, exploring Python Training reveals how Python’s simplicity, rich libraries, and versatility make it ideal for developing efficient compilers, managing cache logic, and streamlining backend processes across diverse domains. To effectively use hash tables, it’s important to grasp key concepts like hash functions, which convert keys into indices.




