
Last updated on 13th Aug 2025| 12618
- Introduction to Random Forest Algorithm
- Ensemble Learning Basics
- Working of Random Forest Algorithm
- Decision Trees in Random Forest Algorithm
- Feature Importance and Selection
- Implementing Random Forest in Python (scikit learn)
- Hyperparameter Tuning
- Evaluation Metrics (Accuracy, ROC, etc.)
- Use Cases (Finance, Healthcare, etc.)
- Comparisons with Other Algorithms
- Summary
Introduction to Random Forest
Random Forest is one of the most powerful and widely-used machine learning algorithms due to its high accuracy, versatility, and robustness against overfitting. It belongs to the family of ensemble learning techniques and is applicable for both classification and regression tasks concepts thoroughly covered in Machine Learning Training, where learners explore algorithms like Random Forest, Gradient Boosting, and AdaBoost to build robust, generalizable models across diverse datasets. This guide aims to provide a comprehensive overview of Random Forest, including its working mechanism, implementation, evaluation, and practical applications.
Ensemble Learning Basics
Ensemble learning is a powerful machine learning method that uses the combined strength of multiple models to improve predictive performance. By carefully joining weak learners, this method builds a strong and more accurate predictive system. Two main ensemble methods stand out: bagging and boosting. To complement these strategies with scalable cloud infrastructure, exploring Overview of ML on AWS reveals how Amazon’s machine learning services like S3, Redshift, SageMaker, and Textract enable developers to build predictive models, automate workflows, and deploy intelligent applications across industries such as healthcare, retail, and finance.
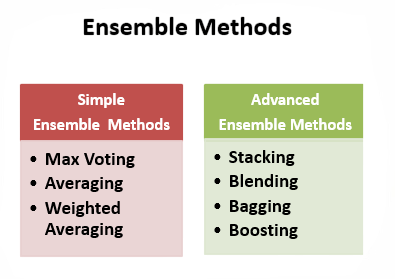
Bagging, as seen with Random Forest, focuses on training several models separately and then combining their results through averaging or voting. This method effectively lowers variance without losing model quality. In contrast, boosting methods like AdaBoost and Gradient Boosting train models one after another, with each new model aimed at correcting the mistakes of the previous ones. Random Forest particularly showcases the benefits of ensemble learning by utilizing bagging with decision trees, which improves model generalization and capability. This teamwork in machine learning changes how algorithms analyze and understand complex datasets, creating a more detailed and dependable predictive system.
Ready to Get Certified in Machine Learning? Explore the Program Now Machine Learning Online Training Offered By ACTE Right Now!
Working of Random Forest Algorithm
The Random Forest algorithm operates by constructing multiple decision trees during training and outputting the mode of the classes (classification) or mean prediction (regression) of the individual trees. To complement this ensemble method with flexible deep learning frameworks, exploring Keras vs TensorFlow reveals how Keras simplifies model building with a user-friendly API ideal for small datasets and rapid prototyping, while TensorFlow offers scalable, high-performance capabilities suited for large-scale applications and advanced customization.
Steps in Random Forest:
- Draw n bootstrap samples from the original dataset.
- For each sample, grow a decision tree.
- At each node, a random subset of m features is selected.
- The best split is chosen from this subset.
- Repeat the process to build a forest of k trees.
- Classification: Majority voting.
- Regression: Average prediction.
This method reduces variance and increases the model’s generalization capabilities. Each tree in a Random Forest votes, and the class with the majority vote becomes the prediction. This technique is particularly effective at reducing overfitting, a common issue with decision trees.
Decision Trees in Random Forest
A decision tree is a flowchart-like structure in which each internal node represents a decision based on a feature, each branch represents the outcome, and each leaf node represents a class label or value. To connect this interpretable model with real-world career impact, exploring Machine Learning Engineer Salary reveals how mastering algorithms like decision trees, SVMs, and neural networks can lead to compensation ranging from ₹7.5 to ₹8 lakh annually in India, with global averages exceeding $120K highlighting the value of applied ML expertise in today’s data-driven industries.
- Each tree is trained on a different random subset of the data.
- Feature selection at each node is random, which introduces diversity.
- Pruning is typically not performed, allowing trees to grow deep.
A decision tree is a flowchart-like structure in which each internal node represents a decision based on a feature, each branch represents the outcome, and each leaf node represents a class label or value.
To Explore Machine Learning in Depth, Check Out Our Comprehensive Machine Learning Online Training To Gain Insights From Our Experts!
Feature Importance and Selection
Random Forest provides a strong way to understand feature importance. It gives important insights into data behavior and model improvement. By using methods like Gini Importance and Permutation Importance, data scientists can systematically assess how each feature contributes to model performance a core skill developed in Machine Learning Training, where learners gain hands-on experience with feature selection, model interpretability, and performance optimization techniques. Gini Importance looks at the weighted reduction of impurity in decision trees. On the other hand, Permutation Importance checks how model scores change when the feature values are shuffled randomly. These advanced metrics not only help spot and remove irrelevant or redundant features but also significantly aid in feature engineering and selection. This ultimately improves the effectiveness and accuracy of the entire machine learning process.

Implementing Random Forest in Python (scikit learn)
Here’s a basic implementation using scikit learn: from data preprocessing to model training and evaluation, scikit-learn offers a streamlined interface for building robust ML pipelines. To complement this hands-on approach with a broader toolkit overview, exploring Machine Learning Tools reveals top frameworks like TensorFlow, Accord.NET, Apache Mahout, and Google Cloud ML Engine each designed to support scalable model development, deep learning workflows, and real-time deployment across diverse platforms.
- from sklearn.ensemble import RandomForestClassifier
- from sklearn.datasets import load_iris
- from sklearn.model_selection import train_test_split
- from sklearn.metrics import accuracy_score
- # Load dataset
- data = load_iris()
- X, y = data.data, data.target
- # Split data
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
- # Initialize and train model
- clf = RandomForestClassifier(n_estimators=100, random_state=42)
- clf.fit(X_train, y_train)
- # Predict and evaluate
- y_pred = clf.predict(X_test)
- print(“Accuracy:”, accuracy_score(y_test, y_pred))
This code trains a Random Forest on the Iris dataset and evaluates its performance using accuracy. scikit learn also allows customization of the Random Forest model through hyperparameter tuning.
Looking to Master Machine Learning? Discover the Machine Learning Expert Masters Program Training Course Available at ACTE Now!
Hyperparameter Tuning
To improve performance, several hyperparameters can be tuned:
- n_estimators: Number of trees in the forest.
- max_depth: Maximum depth of each tree.
- min_samples_split: Minimum number of samples required to split an internal node.
- max_features: Number of features to consider when looking for the best split.
Grid Search Example:
- from sklearn.model_selection import GridSearchCV
- param_grid = {
- ‘n_estimators’: [50, 100, 200],
- ‘max_depth’: [None, 10, 20],
- ‘max_features’: [‘auto’, ‘sqrt’]
- grid_search = GridSearchCV(RandomForestClassifier(), param_grid, cv=5)
- grid_search.fit(X_train, y_train)
- print(“Best Parameters:”, grid_search.best_params_)
Hyperparameter tuning can significantly improve the model’s accuracy and generalization capabilities.
Evaluation Metrics (Accuracy, ROC, etc.)
Depending on the task, different evaluation metrics are used:
- Accuracy: Proportion of correct predictions.
- Precision, Recall, F1-Score: For imbalanced datasets.
- ROC AUC: Measures the ability of the model to distinguish between classes.
- Confusion Matrix: Visual tool for classification performance.
- Mean Absolute Error, MSE, R^2 Score: For regression tasks.

These metrics give a comprehensive view of the model’s strengths and weaknesses in various scenarios.
Preparing for Machine Learning Job Interviews? Have a Look at Our Blog on Machine Learning Interview Questions and Answers To Ace Your Interview!
Use Cases (Finance, Healthcare, etc.)
Random Forest is used across various industries:
- Finance: Credit scoring, fraud detection, risk management.
- Healthcare: Disease diagnosis, patient classification.
- Retail: Customer segmentation, recommendation systems.
- Manufacturing: Predictive maintenance, quality control.
- Marketing: Churn prediction, campaign analysis.
- E-commerce: Personalized recommendations, demand forecasting.
- Insurance: Claim prediction and fraud analysis.
Its robustness and interpretability make it ideal for sectors requiring high accuracy and reliability.
Comparisons with Other Algorithms
- Random Forest vs Decision Trees: RF reduces overfitting by averaging multiple trees.
- Random Forest vs SVM: SVM works better with high-dimensional data; RF is faster and easier to interpret.
- Random Forest vs Gradient Boosting: GB often achieves higher accuracy but is sensitive to hyperparameters.
- Random Forest vs Neural Networks: RF is less computationally intensive and requires less data preprocessing.
- Random Forest vs KNN: RF generalizes better and is more scalable.
Each algorithm has its strengths; the best choice depends on the specific use case and data characteristics. To deepen your understanding of these strengths and trade-offs, exploring Deep Learning Books to Read reveals expert-curated titles that balance theory and implementation covering neural network design, optimization strategies, and real-world applications across domains like computer vision, natural language processing, and time-series forecasting.
Summary
Random Forest is a flexible, easy-to-use machine learning algorithm that produces great results even without extensive hyperparameter tuning. It works well on both structured and unstructured data, provides useful insights via feature importance, and can be applied to a wide range of real-world problems capabilities thoroughly explored in Machine Learning Training, where learners tackle diverse datasets and build models that drive actionable insights across industries. Despite its limitations in interpretability and computational complexity, Random Forest remains a go-to algorithm for many data scientists and ML practitioners. Its ensemble approach mitigates overfitting and enhances accuracy, making it suitable for mission-critical applications in industries such as finance, healthcare, and retail. As machine learning continues to evolve, Random Forest remains a reliable baseline model and a strong contender in the toolkit of any data scientist. With thoughtful application and careful tuning, it can deliver excellent predictive performance, making it one of the most powerful algorithms in the current landscape of machine learning.

