
Last updated on 09th Jul 2020| 1976
SCALA is a statically typed programming language that incorporates both functional and object-oriented programming. It primarily runs on the JVM platform, but it can also be used to write software for multiple platforms, including native platforms using Scala-Native and JavaScript runtimes through ScalaJs.
Apache Spark
- Apache Spark is a lightning-fast cluster computing designed for fast computation. It was built on top of Hadoop MapReduce and it extends the MapReduce model to efficiently use more types of computations which includes Interactive Queries and Stream Processing. This is a brief tutorial that explains the basics of Spark Core programming.
Initializing Spark
- There are several approaches to initialize a Spark application depending on the use case, the application may be one that leverages RDD, Spark Streaming, Structured SQL with Dataset or DataFrame. Therefore, it is important to understand how to initialize these different Spark instances.
1. RDD with Spark Context:
- Operations with spark-core are initiated by creating a spark context, the context is created with a number of configurations such as the master location, application names, memory size of executors to mention a few.
- Here are two ways to initiate a spark context as well as how to make an RDD with the created spark context.
2. DataFrame/Dataset with Spark Session:
- As observed above, an entry point to Spark could be by using the Spark Context, however, Spark allows direct interaction with the Structured SQL API with Spark Session. It also involves specifying the configuration for the Spark app.
- Here is the approach to initiate a Spark Session and create a Dataset and DataFrame with the Session.
3. DStream with Spark Streaming:
- The other entry point to Spark is using the Streaming Context when interacting with real-time data. An instance of Streaming Context can either be created from a Spark Configuration or a Spark Context.
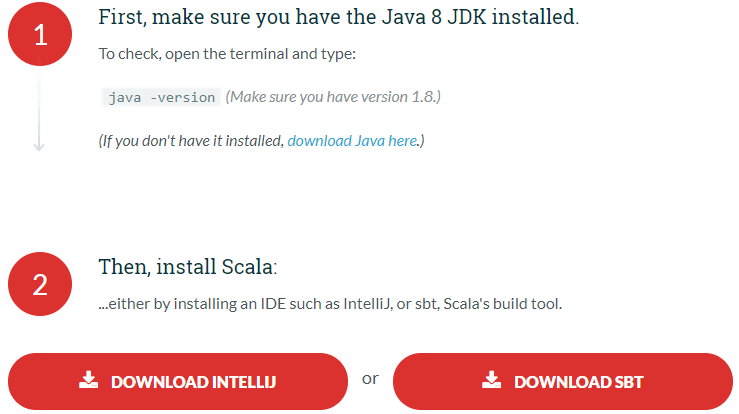
Install Scala
- To begin writing Scala programs, you need to have it installed on your computer. In order to do this, you will need to visit their site https://www.scala-lang.org/download/ in order to download the latest version of Scala.
Following the link, we’re led to two options which we can choose to install Scala on our machines. For this tutorial, we’ll download the IntelliJ IDE.
- Once you visit the download link, you’ll find two versions of the IntelliJ IDE.

- Step 1) on the page, click on the dropdown on the Community Edition.
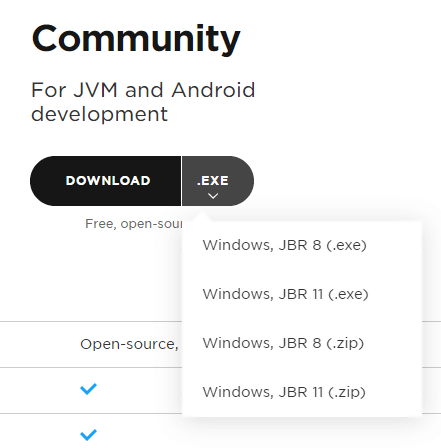
- It presents us with an option to download the IntelliJ IDE together with JBR which contains a JDK implementation(Java Development Kit) OpenJDK which Scala needs to compile and run the code.
- Step 2) Once you download IntelliJ, double click it in order to run the installation wizard and follow the dialog.
- Step 3) Choose a location to install the IDE.
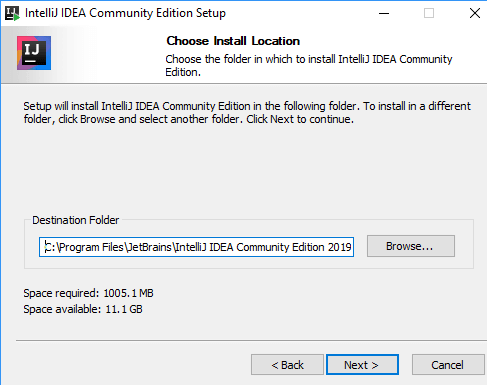
- If by chance you didn’t download the one with the JDK, we still get a prompt where that we can check to download it by selecting the checkbox.
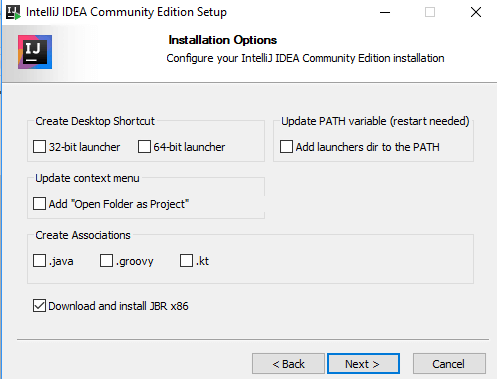
- Step 4) Leave the other defaults as they are and click next.
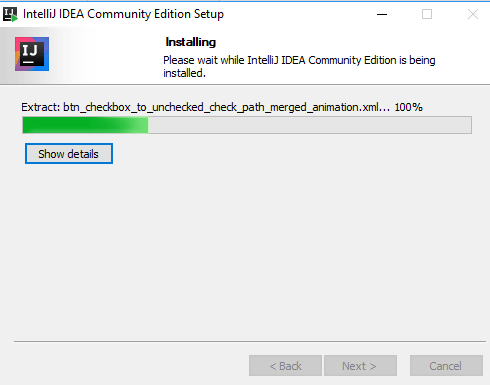
- Step 5) Once the installation completes, run the IntelliJ IDE by clicking its startup icon in the startup menu like a regular application.
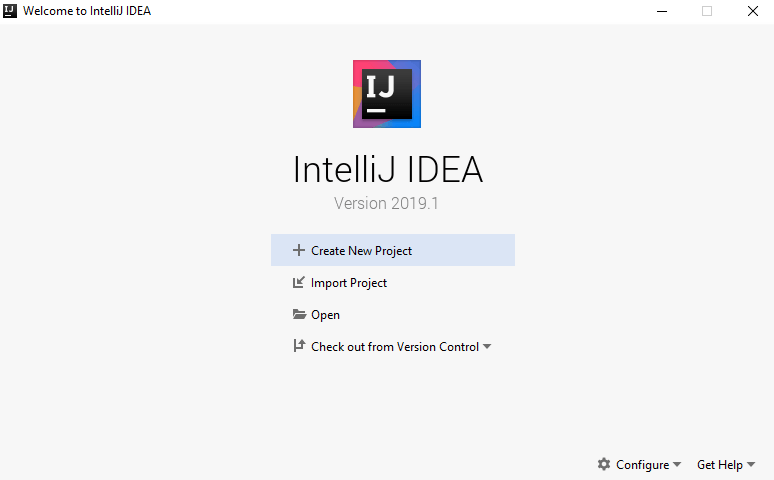
- You still need to go through an additional step of adding the Scala plugin to IntelliJ; you do so by clicking the dropdown on the configure menu located at the bottom right of the screen and selecting the plugin option.
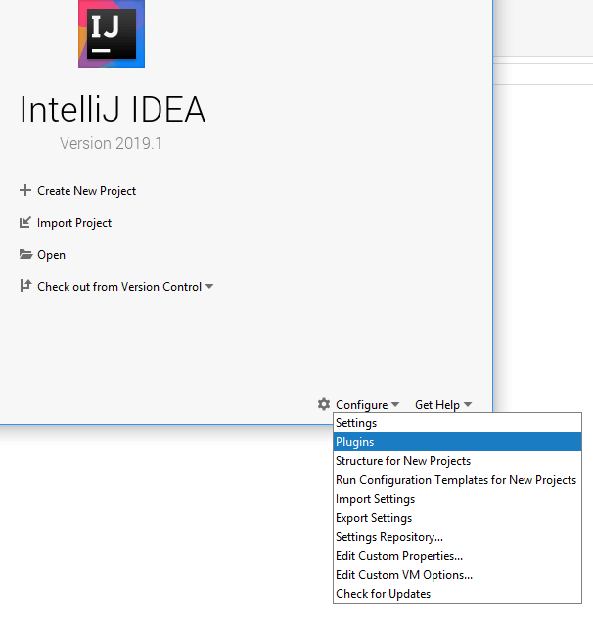
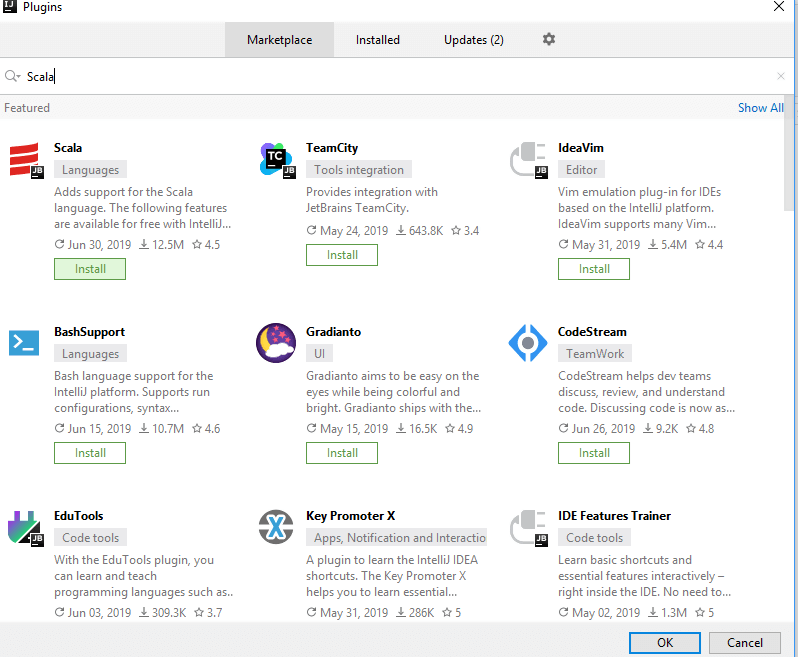
- On the Marketplace tab, a search for Scala will present the plugin as the first result under the Languages tag.
- Step 6) Click install, which will lead the plugin beginning the download.
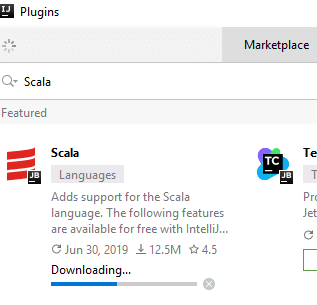
- Step 7) After the download completes, you’ll be prompted to restart the IDE so that the installed plugin can start working.
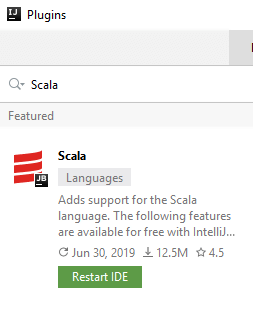
- After restarting you’ll find yourself on the same page as before when we ran the IDE, but this time around we have already installed the Scala plugin.
Example of spark and scala
Spark Context example – *How to run Spark*
- If you are struggling to figure out how to run a Spark Scala program, this section gets straight to the point.
- The first step to writing an Apache Spark application (program) is to invoke the program, which includes initializing the configuration variables and accessing the cluster. SparkContext is the gateway to accessing Spark functionality.
- For beginners, the best and simplest option is to use the Scala shell, which auto creates a SparkContext. Below are 4 Spark Context examples on how to connect and run Spark.

Learn On-Demand Apache Spark and Scala Certification Training from Real Time Experts
Weekday / Weekend BatchesSee Batch DetailsExample 1:
To login to Scala shell, at the command line interface, type
- “/bin/spark-shell “.
Example 2:
To login and run Spark locally without parallelism:
- “/bin/spark-shell –master local “.
Example 3:
To login and run Spark locally in parallel mode, setting the parallelism level to the number of cores on your machine:
- “/bing/spark-shell –master local[*] “.
Example 4:
To login and connect to Yarn in client mode:
- “/bin/spark-shell –master yarn-client “.
Spark Scala Examples on Parallelize
- Parallelize is a method used to create an RDD in Apache Spark based on data that’s already being processed in memory. Its also a great method to generate an RDD on the fly for testing and debugging code.
Example 1:
To create an RDD using Apache Spark Parallelize method on a sample set of numbers, say 1 thru 100.
- scala > val parSeqRDD = sc.parallelize(1 to 100)
Example 2:
To create an RDD from a Scala List using the Parallelize method.
- scala > val parNumArrayRDD = sc.parallelize(List(“pen”,”laptop”,”pencil”,”mouse”))
Note: To view a sample set of data loaded in the RDD, type this at the command line: parNumArrayRDD.take(3).foreach(println)
Example 3:
To create an RDD from an Array using the Parallelize method.
- scala > **val parNumArrayRDD = sc.parallelize(Array(1,2,3,4,5))*
Spark read from hdfs example
- Creating an RDD in Apache Spark requires data. In Spark, there are two ways to aquire this data: parallelized collections and external datasets. Data not in an RDD is classified as an external dataset and includes flat files, binary files,sequence files, hdfs file format, HBase, Cassandra or in any random format.
- The Spark Scala Examples listed below are some additional ways for Spark to read from hdfs.
Example 1:
To read a text file named “recent_orders” that exists in hdfs.
- scala > val ordersRDD = sc.textFile(“recent_orders”)
Example 2:
To read a text file named “recent_orders” that exists in hdfs and specify the number of partitions (3 partitions in this case).
- scala > val ordersRDD = sc.textFile(“recent_orders”, 3)
Example 3:
To read all the contents of a directory named “data_files” in hdfs.
- scala > val dataFilesRDD = sc.wholeTextFiles(“data_files”)
Note: The RDD returned is in a key,value pair format where the key represents the path of each file, and the value represents the entire contents of the file.
Spark filter example
- A filter is a transformation operation in Apache Spark, which takes an existing dataset,applies a reducing function and returns data for which the reducing fuction returns a true boolean. Conceptually, this is similar to applying a column filter in an excel spreadhseet, or a “where” clause in a sql statement.
Listed below are a few Spark filter examples
Prerequisite : Create an RDD with the sample data as show below.
- scala > val sampleColorRDD = sc.parallelize(List(“red”, “blue”, “green”, “purple”, “blue”, “yellow”))
Example 1:
To apply a filter on sampleColorRDD and only select the color “blue” from the RDD dataset.
- scala > val filterBlueRDD = sampleColorRDD.filter(color => color == “blue”)
Example 2:
To apply a filter on sampleColorRDD and select all colors other than the color “blue” from the RDD dataset.
- scala > val filterNotBlueRDD = sampleColorRDD.filter(color => color != “blue”)
Example 3:
To apply a filter on sampleColorRDD and select multiple colors: red and “blue” from the RDD dataset.
- scala > val filterMultipleRDD = sampleColorRDD.filter(color => (color == “blue” || color == “red”))
Note1: To perform a count() action on the filter output and validate, type the below at the command line:
- scala > filterMultipleRDD.count()
Note2: Once you get familiar with the basics, you could minimize your code by combining transformation and action operations into a single line as such:
- scala > sampleColorRDD.filter(color => (color == “blue” || color == “red”)).count()
Uses of spark and scala
- Frontend web development with ScalaJS
- Mobile development, both Android Development and IOS – with Scala Native
- Server-side libraries like HTTP4S, Akka-Http, Play Framework
- Internet of things using
- Game development
- NLP – Natural Language Processing using a suite of libraries ScalaNLP
- Testing advanced programming techniques such as Functional Programming and in Object-Oriented Programming
- Build highly concurrent communication application using actors a library for the JVM inspired by Erlang
- Use it for machine learning using libraries like Figaro that does probabilistic programming and Apache Spark that
- To perform batch processing, we were using Hadoop MapReduce.
- Also, to perform stream processing, we were using Apache Storm / S4.
- Moreover, for interactive processing, we were using Apache Impala / Apache Tez.
- To perform graph processing, we were using Neo4j / Apache Giraph.
Benifits
1) Ideal for Implementing IoT
- If your company is focusing on the Internet of Things, Spark can drive it through its capability of handling many analytics tasks concurrently. This is accomplished through well-developed libraries for ML, advanced algorithms for analyzing graphs, and in-memory processing of data at low latency.
2) Helps in Optimizing Business Decision Making
- Low latency data transmitted by IoT sensors can be analysed as continuous streams by Spark. Dashboards that capture and display data in real time can be created for exploring improvement avenues.
3) Complex Workflows Can Be Created with Ease
- Spark has dedicated high-level libraries for analyzing graphs, creating queries in SQL, ML, and data streaming. As such, you can create complex big data analytical workflows with ease through minimal coding.
4) Prototyping Solutions Becomes Easier
- As a Data Scientist, you can utilize Scala’s ease of programming and Spark’s framework for creating prototype solutions that offer enlightening insights into the analytical model.
5) Helps in De-Centralized Processing of Data
- In the coming decade, Fog computing would gain steam and will complement IoT to facilitate de-centralized processing of data. By learning Spark, you can remain prepared for upcoming technologies where large volumes of distributed data will need to be analyzed. You can also devise elegant IoT driven applications to streamline business functions.
6) Compatibility with Hadoop
- Spark can function atop HDFS (Hadoop Distributed File System) and can complement Hadoop. Your organization need not spend additionally on setting up Spark infrastructure if Hadoop cluster is present. In a cost-effective manner, Spark can be deployed on Hadoop’s data and cluster.
7) Versatile Framework
- Spark is compatible with multiple programming languages such as R, Java, Python, etc. This implies that Spark can be used for building Agile applications easily with minimal coding. The Spark and Scala online community is very vibrant with numerous programmers contributing to it. You can get all the required resources from the community for driving your plans.
8) Faster Than Hadoop
- If your organization is looking to enhance data processing speeds for making faster decisions, Spark can definitely offer a leading edge. Data is processed in Spark in a cyclic manner and the execution engine shares data in-memory. Support for Directed Acyclic Graph (DAG) mechanism allows Spark engine to process simultaneous jobs with the same datasets. Data is processed by Spark engine 100x quicker compared to Hadoop MapReduce.
9) Proficiency Enhancer

- If you learn Spark and Scala, you can become proficient in leveraging the power of different data structures as Spark is capable of accessing Tachyon, Hive, HBase, Hadoop, Cassandra, and others. Spark can be deployed over YARN or another distributed framework as well as on a standalone server.




