
Last updated on 20th Jan 2022| 2408
- Introduction to Spark
- What is Streaming?
- Why Spark Streaming?
- Spark Streaming Overview
- Spark Streaming Features
- Spark Streaming Workflow
- Spark Streaming Fundamentals
- Use Case – Twitter Sentiment Analysis
- Goals of Spark Streaming
- Spark Streaming Sources
- Conclusion
- Spark Streaming is an augmentation of the center Spark API that empowers versatile, high-throughput, shortcoming lenient stream handling of live information streams. Information can be ingested from many sources like Kafka, Kinesis, or TCP attachments, and can be handled utilizing complex calculations communicated with undeniable level capacities like a guide, diminish, join and window. At last, handled information can be pushed out to filesystems, data sets, and live dashboards. Truth be told, you can apply Spark’s AI and diagram handling calculations on information streams.
- Inside, it fills in as follows. Spark Streaming gets live info information streams and partitions the information into groups, which are then handled by the Spark motor to produce the last stream of results in clumps.
- Spark Streaming gives an undeniable level reflection called discretized stream or DStream, which addresses a nonstop stream of information. DStreams can be created either from input data streams from authorities like Kafka, and Kinesis, or by applying significant level procedures on other DStreams. Inside, a DStream is addressed as an arrangement of RDDs.
- This guide tells you the best way to begin composing Spark Streaming projects with DStreams. You can compose Spark Streaming projects in Scala, Java, or Python (presented in Spark 1.2), which are all introduced in this aide. You will observe tabs all through this guide that let you pick between code scraps of various dialects.
- The Spark Streaming work process has four significant level stages. The first is to stream information from different sources. These sources can be streaming information sources like Akka, Kafka, Flume, AWS, or Parquet for ongoing streaming. The second sort of source incorporates HBase, MySQL, PostgreSQL, Elastic Search, Mongo DB, and Cassandra for static/clump streaming.
- When this occurs, Spark can be utilized to perform Machine Learning on the information through its MLlib API. Further, Spark SQL is utilized to perform the further procedure on this information. At long last, the streaming result can be put away into different information stockpiling frameworks like HBase, Cassandra, MemSQL, Kafka, Elastic Search, HDFS, and nearby record frameworks.
- Streaming Context
- DStream
- Reserving
- Collectors, Broadcast Variables, and Checkpoints
- map(func) map(func) returns another DStream bypassing every component of the source DStream through a capacity func.
- flatMap(func) flatMap(func) is like map(func) however each information thing can be planned to at least 0 result things and returns another DStream by passing each source component through a capacity func.
- filter(func) filter(func) returns another DStream by choosing just the records of the source DStream on which func brings valid back.
- reduce(func) reduce(func) returns another DStream of single-component RDDs by conglomerating the components in each RDD of the source DStream utilizing a capacity func.
- groupBy(func) groupBy(func) returns the new RDD which essentially is made up with a key and comparing rundown of things of that gathering.
- Anticipate the achievement of a film
- Anticipate political mission achievement
- Choose whether to put resources into a specific organization
- Designated publicizing
- Audit items and administrations
- //Import the vital bundles into the Spark Program
- import org.apache.spark.streaming.{Seconds, StreamingContext}
- import org.apache.spark.SparkContext._
- …
- import java.io.File
- object twitterSentiment {
- def main(args: Array[String]) {
- if (args.length < 4) {
- System.err.println(“Usage: TwitterPopularTags <'consumer key> <'consumer secret> ” + “<'access token> <'access token secret> [<'filters>]”)
- System.exit(1)
- }
- StreamingExamples.setStreamingLogLevels()
- //Passing our Twitter keys and tokens as contentions for approval
- val Array(consumerKey, consumerSecret, accessToken, accessTokenSecret) = args.take(4)
- val channels = args.takeRight(args.length – 4)
- // Set the framework properties with the goal that Twitter4j library utilized by Twitter stream
- // Use them to create OAuth accreditations
- System.setProperty(“twitter4j.oauth.consumerKey”, consumerKey)
- …
- System.setProperty(“twitter4j.oauth.accessTokenSecret”, accessTokenSecret)
- val sparkConf = new SparkConf().setAppName(“twitterSentiment”).setMaster(“local[2]”)
- val ssc = new Streaming Context
- val stream = TwitterUtils.createStream(ssc, None, channels)
- //Input DStream change utilizing flatMap
- val labels = stream.flatMap { status => Get Text From The Hashtags }
- //RDD change utilizing sortBy and afterward map work
- tags.countByValue()
- .foreachRDD { rdd =>
- val now = Get current season of each Tweet
- rdd
- .sortBy(_._2)
- map(x => (x, presently))
- //Saving our result at ~/twitter/registry
- .saveAsTextFile(s”~/twitter/$now”)
- }
- //DStream change utilizing channel and guide capacities
- val tweets = stream.filter {t =>
- val labels = t. Split On Spaces .filter(_.startsWith(“#”)). Convert To Lower Case
- tags.exists { x => valid }
- }
- val information = tweets.map { status =>
- val opinion = SentimentAnalysisUtils.detectSentiment(status.getText)
- val tagss = status.getHashtagEntities.map(_.getText.toLowerCase)
- (status.getText, sentiment.toString, tagss.toString())
- }
- data.print()
- //Saving our result at ~/with filenames beginning like twitters
- data.saveAsTextFiles(“~/twitters”,”20000″)
- ssc.start()
- ssc.awaitTermination()
- }
- }
- Coming up next are the outcomes that are shown in the Eclipse IDE while running the Twitter Sentiment Streaming system. As we can find in the screen capture, every one of the tweets is ordered into Positive, Neutral, and Negative as per the feeling of the substance of the tweets.
- The result of the Sentiments of the Tweets is put away into envelopes and documents as indicated by the time they were made. This result can be put away on the neighborhood record framework or HDFS as important. The resulting index resembles this:
- Here, inside the twitter index, we can find the usernames of the Twitter clients alongside the timestamp for each tweet as displayed beneath:
- Since we have the Twitter usernames and timestamps, let us check out the Sentiments and tweets put away in the principle registry. Here, each tweet is trailed by the feeling. This Sentiment that is put away is additionally utilized for examining a tremendously huge number of bits of knowledge by organizations.
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
- Improving the client experience
- Acquiring upper hand
- Acquiring Business Intelligence
- Reviving a losing brand
- With this, we have arrived at the finish of this Spark Streaming Tutorial blog. At this point, you more likely than not procured a sound comprehension of what Spark Streaming is. The Twitter Sentiment Analysis use case will give you the necessary certainty to chip away at any future undertakings you experience in Spark Streaming and Apache Spark. Practice is the way to dominate any subject and I trust this blog has made sufficient interest in you to investigate further on Apache Spark.
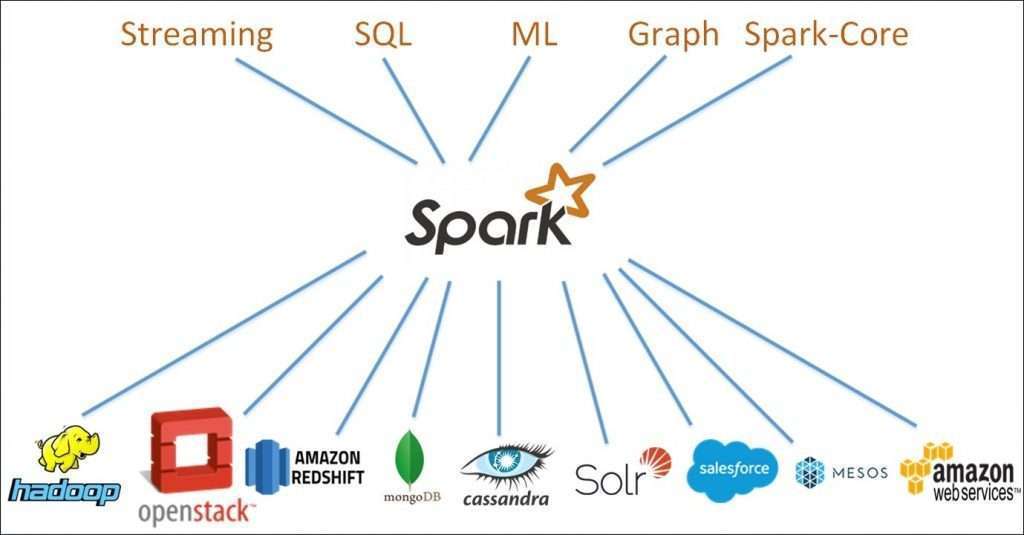
Introduction to Spark:
What is Streaming?
Information Streaming is a strategy for moving information so it tends to be handled as a consistent and constant stream. Streaming advancements are turning out to be progressively significant with the development of the Internet.
Why Spark Streaming?
We can utilize Spark Streaming to stream constant information from different sources like Twitter, Stock Market, and Geographical Systems and perform a strong examination to help organizations.

Spark Streaming Overview:
Spark Streaming is utilized for handling continuous streaming information. It is a valuable expansion to the center Spark API. Spark Streaming empowers high-throughput and issues lenient stream handling of live information streams.

Spark Streaming Features:
Scaling: Spark Streaming can without much of a stretch scale to many hubs.
Speed: It accomplishes low dormancy.
Adaptation to internal failure: Spark can productively recuperate from disappointments.
Incorporation: Spark coordinates with the group and continuous handling.
Business Analysis: Spark Streaming is utilized to follow the conduct of clients which can be utilized in business examination.
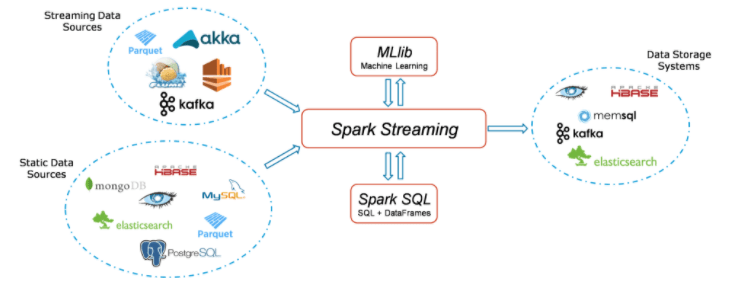
Spark Streaming Workflow:

Learn Apache spark Certification Training Course to Build Your Skills
Weekday / Weekend BatchesSee Batch DetailsSpark Streaming Fundamentals:
Streaming Context
Streaming Context consumes a surge of information in Spark. It enlists an Input DStream to create a Receiver object. It is the primary section point for Spark’s usefulness. Spark gives various default executions of sources like Twitter, Akka Actor, and ZeroMQ that are open from the unique situation.

DStream
Discretized Stream (DStream) is the fundamental reflection given by Spark Streaming. It is a consistent stream of information. It is gotten from an information source or a handled information stream created by changing the information stream. Inside, a DStream is addressed by a ceaseless series of RDDs and each RDD contains information from a specific span.
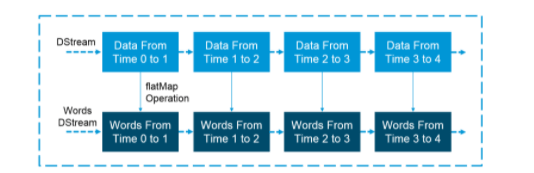
Input DStreams: Input DStreams will be DStreams addressing the surge of info information got from streaming sources. Each info DStream is related to a Receiver object which gets the information from a source and stores it in Spark’s memory for handling.
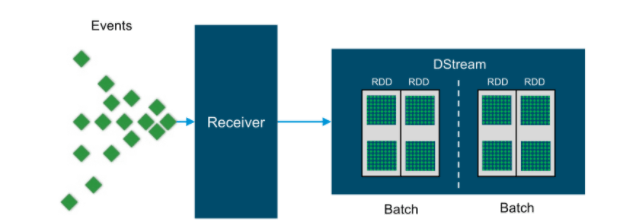
Changes on DStreams: Any activity applied on a DStream means procedure on the basic RDDs. Changes permit the information from the info DStream to be adjusted like RDDs. DStreams support a considerable lot of the changes accessible on typical Spark RDDs.
Coming up next are a portion of the famous changes on DStreams:
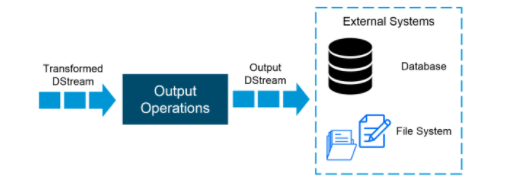
Yield DStreams:
Yield activities permit DStream’s information to be pushed out to outside frameworks like data sets or record frameworks. Yield tasks trigger the real execution of all the DStream changes.
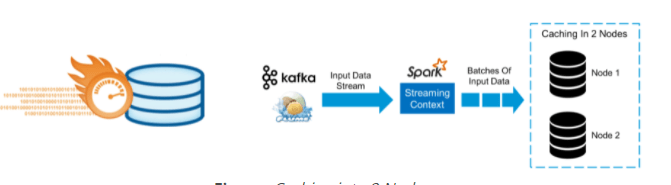
Storing
DStreams permit engineers to store/continue the stream’s information in memory. This is valuable assuming the information in the DStream will be figured on numerous occasions. This should be possible utilizing the endure() strategy on a DStream.
For input streams that get information over the organization (like Kafka, Flume, sockets, and so on), the default constancy level is set to recreate the information to two hubs for adaptation to non-critical failure.

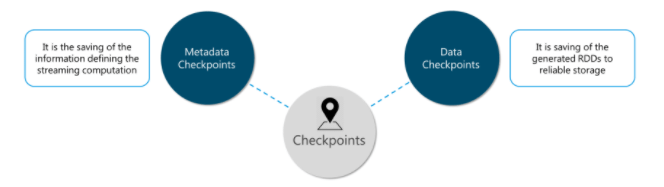
Aggregators, Broadcast Variables, and Checkpoints
Aggregators: Accumulators are factors that are just added through an acquainted and commutative activity. They are utilized to execute counters or aggregates. Following aggregators in the UI can be valuable for understanding the advancement of running stages. Spark locally upholds numeric aggregators. We can make named or anonymous aggregators.
Broadcast Variables: Broadcast factors permit the developer to keep a read-just factor reserved on each machine rather than delivery a duplicate of it with errands. They can be utilized to provide each hub with a duplicate of an enormous info dataset in a proficient way. Spark likewise endeavors to convey broadcast factors utilizing proficient transmission calculations to decrease correspondence cost.
Designated spots: Checkpoints are like designated spots in gaming. They make it run every minute of every day and make it strong to disappointments irrelevant to the application rationale.
Use Case – Twitter Sentiment Analysis:
Since we have perceived the center ideas of Spark Streaming, let us take care of a genuine issue utilizing Spark Streaming.
Issue Statement: To plan a Twitter Sentiment Analysis System where we populate constant feelings for emergency the board, administration changing and target showcasing.
Uses of Sentiment Analysis:
Spark Streaming Implementation:
Track down the Pseudo Code beneath:
Results:

Get JOB Oriented Apache spark Training for Beginners By MNC Experts
Tweaking Code:
Presently, let us alter our code a little to get opinions for explicit hashtags (points). At present, Donald Trump, the President of the United States is moving across news channels and online web-based media. Allow us to take a gander at the opinions related to the catchphrase ‘Trump’.
Pushing Forward:
As we have seen from our Sentiment Analysis showing, we can remove opinions of specific themes very much as we accomplished for ‘Trump’. Also, Sentiment Analytics can be utilized in an emergency the executives, administration changing and target promoting by organizations all over the planet. Organizations involving Spark Streaming for Sentiment Analysis have applied a similar way to deal with accomplish the accompanying:
Goals of Spark Streaming:
This design permits Spark Streaming to accomplish the accompanying objectives:
a) Dynamic burden adjusting
Separating the information into little miniature clusters considers fine-grained designation of calculations to assets. Allow us to think about a straightforward responsibility where dividing of info information stream should be finished by a key and handled. In the customary record-at-a-at-a once, one of the parcels is more computationally serious than others, the hub to which that segment is relegated will turn into a bottleneck and dial back the pipeline. The work’s assignments will be normally load adjusted across the laborers where a few specialists will handle a couple of longer errands while others will deal with a greater amount of the more limited undertakings in Spark Streaming.
b) Fast disappointment and stray recuperation
Customary frameworks need to restart the bombed administrator on one more hub to recompute the lost data in the event of hub disappointment. Just a single hub is taking care of the recomputation because of which the pipeline can’t continue until the new hub has up to speed after the replay. In Spark, the calculation discretizes into little errands that can run anyplace without influencing accuracy. So bombed assignments we can disseminate uniformly on the wide range of various hubs in the bunch to play out the recomputations and recuperate from the disappointment quicker than the conventional methodology.
c) Unification of group, streaming, and intelligent examination
A DStream in Spark is only a progression of RDDs in Spark that permits clump and streaming jobs to interoperate flawlessly. Subjective Apache Spark capacities can be applied to each bunch of streaming information. Since the clumps of streaming information are put away in the Spark’s laborer memory, it very well may be intelligently questioned on request.
d) Advanced examination like AI and intuitive SQL
Spark interoperability stretches out to rich libraries like MLlib (AI), SQL, DataFrames, and GraphX. RDDs produced by DStreams can change over to DataFrames and questions with SQL. AI models produced disconnected with MLlib can apply to streaming information.
e) Performance
Spark Streaming’s capacity to bunch information and influence the Spark motor prompts practically higher throughput to other streaming frameworks. Spark Streaming can accomplish latencies as low as a couple of hundred milliseconds.
Spark Streaming Sources:
Each information DStream (except document stream) partners with a Receiver object which gets the information from a source and stores it in Spark’s memory for handling. There are two classifications of inherent streaming sources:
Essential sources – These are the sources straightforwardly accessible in the StreamingContext API. Models: document frameworks, and attachment associations.
Progressed sources – Sources like Kafka, Flume, Kinesis, and so forth are accessible through additional utility classes. These require connecting against additional conditions.
There are two kinds of recipients based on their dependability:
Dependable Receiver – A solid recipient is the one that accurately sends an affirmation to a source when the information gets and stores in Spark with replication.
Questionable Receiver – An inconsistent collector doesn’t send an affirmation to a source. This we can use for sources when one doesn’t need or have to go into the intricacy of affirmation.
Conclusion
Apache Spark is a cluster computing platform designed to be fast, speed side and extends the popular MapReduce model to efficiently supports more type of computations, including interactive queries and stream processing.




