
Last updated on 09th Jul 2020| 1852
Apache storm is an open source distributed system for real-time processing. It can process unbounded streams of Big Data very elegantly. Storm can be used with any language because at the core of Storm is a Thrift Definition for defining and submitting topologies. Thrift can be used in any language and topologies can be defined and submitted from any language.
Apache Storm Architecture
- Storm architecture is closely similar to Hadoop. However, there are some differences which can be better understood once we get a closer look at its cluster-
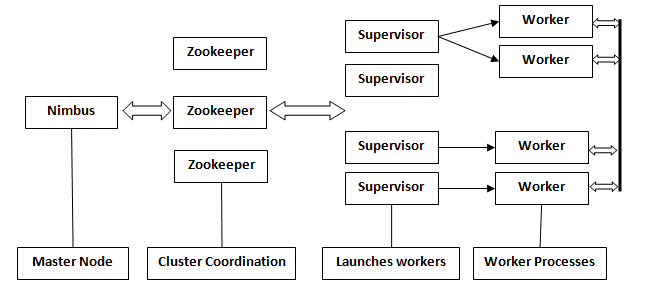
Node: There are two types of nodes in a storm cluster similar to Hadoop.
Master Node
- The master node of the storm runs a demon called “Nimbus” which is similar to the “: job Tracker” of Hadoop cluster. Nimbus is responsible for assigning the task to machines and monitoring their performance.
Worker Node
- Similar to master node worker node also runs a daemon called “Supervisor” which can run one or more worker processes on its node. Nimbus assigns the work to the supervisor and starts and stops the process according to requirement. Hence, it can’t manage its cluster state; it depends on zookeepers.
Zookeeper Framework
- It facilitates communication between nimbus and supervisor with the help of message ACK, processing status, etc.
Stream Grouping
- Stream grouping controls how the tuples are routed in the topology and helps to understand the tuples flow in the topology. There are six types of grouping-
- Shuffle Grouping
- Field Grouping
- Global Grouping
- All Grouping
- None Grouping
- Local Grouping
Graphical Representation of Grouping
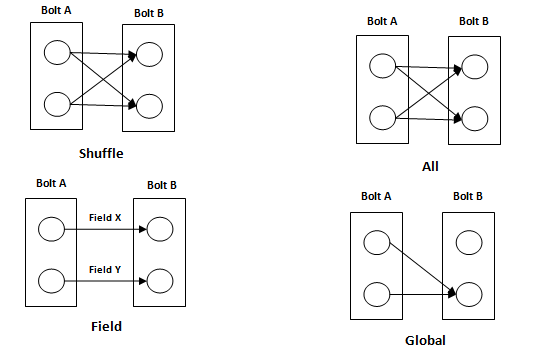
- Shuffle Grouping- Tuples are randomly distributed across the bolt’s tasks in a way such that each bolt is guaranteed to get an equal number of tuples.
- Field Grouping- The fields with the same values in tuples are grouped and the rest tuples kept outside. The stream grouped by the “book-id” field, tuples with the same “book-id” will always go to the same task, but tuples with different “book-id”‘s may go to different tasks.
- Global Grouping- All the streams can be grouped and forward to one bolt. This grouping sends tuples generated by all instances of the source to a single target instance (individually, pick the worker which has lower ID).
- All Grouping- All grouping sends a single copy of each tuple to all instances of the receiving bolt. It is used to send signals to bolts. This is useful for join operations.
- None Grouping- It specifies that you don’t care how the stream is grouped. Currently, none of the groupings are equivalent to shuffle groupings.
- Local Grouping- If the target bolt has more than one task in the same worker process, tuple will be shuffled to just those in-process tasks. Else it behaves like shuffle grouping.
Reliable Processing in Storm
Reliability can be achieved in Storm by:
- Specifying the path from spout to bolts through a process called anchoring.
- Specifying successful or unsuccessful processing using ack and fail methods.
The diagram here shows the topology from the example we discussed in the previous lesson. It shows the spout producing tuples that are processed by the Split bolt. The tuples from the split bolt are processed by the Count bolt.
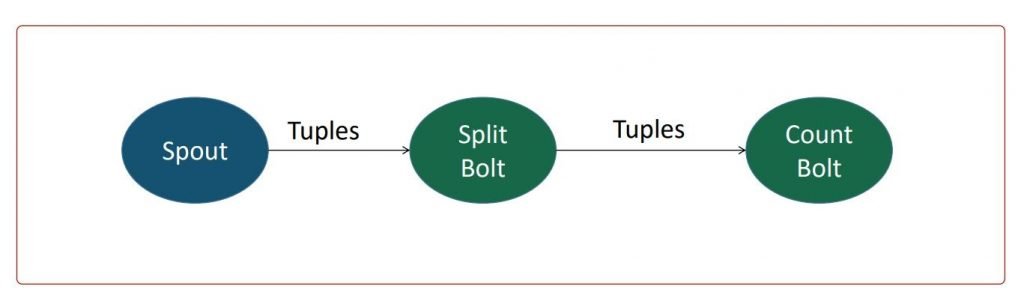
- For successful processing, a tuple from the spout should be successfully processed by the Split bolt as well as a Count bolt.
Ack and Fail
- Reliability is achieved by using the ack and fail methods.
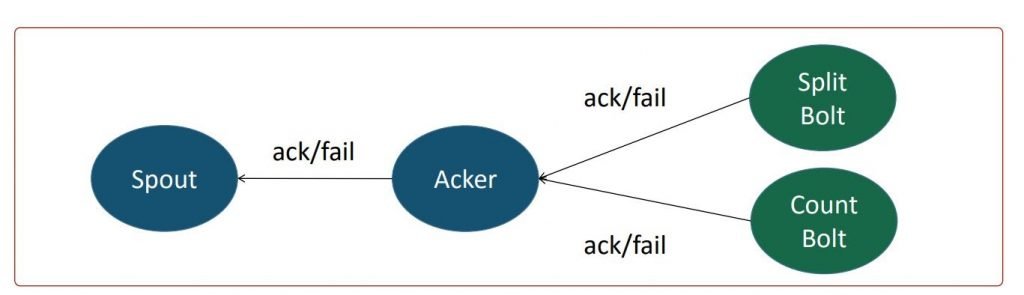
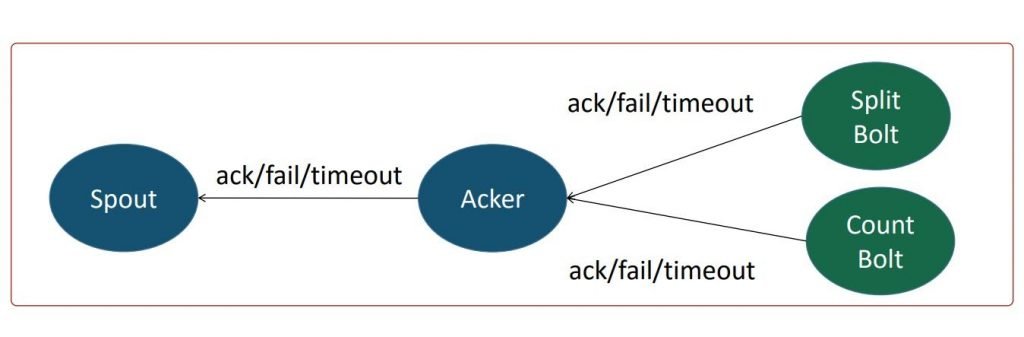
- Spout and bolts use the ack and fail methods to indicate the successful and unsuccessful processing respectively. The emit method indicates the tuples that are processed by spouts and bolts. When all the tasks in the path of a tuple send acks, the tuple is treated as successful. Otherwise, it is treated as failed. An acker task is created by Storm to handle the Acknowledgements.
- The diagram shows the acker task collecting ack and fail messages from Split and Count bolts and then sending the ack or fail message to the spout. The acker task tracks the ack and fail messages from each bolt in the path of a tuple and sends ack to spout only if all the bolts send an ack message for a particular tuple.
Ack Timeout
- If an ack is not received within a specified timeout time period, the tuple processing is considered as failed. The configuration parameter TOPOLOGY_MESSAGE_TIMEOUT_SECS specifies the timeout in seconds. The default timeout is 30 seconds.
- The diagram shows the acker task receiving the timeout apart from ack and fail, and passing the same to the spout.
Anchoring
- Specifying the link from the input path to output path for a tuple is called anchoring. Anchoring is done by specifying the input tuple in the emit method of a bolt. Input tuple should be the first parameter of the bolt.
- For example, if the bolt has the execute method as shown below: execute(Tuple inputTuple) The emit method should look like: emit(inputTuple, other parameters.)

Get Experts Curated Apache Storm Training From Real-Time Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
Components of a Storm cluster
- A Storm cluster is superficially similar to a Hadoop cluster. Whereas on Hadoop you run “MapReduce jobs”, on Storm you run “topologies”. “Jobs” and “topologies” themselves are very different — one key difference is that a MapReduce job eventually finishes, whereas a topology processes messages forever (or until you kill it).
- There are two kinds of nodes on a Storm cluster: the master node and the worker nodes. The master node runs a daemon called “Nimbus” that is similar to Hadoop’s “Job Tracker”. Nimbus is responsible for distributing code around the cluster, assigning tasks to machines, and monitoring for failures.
- Each worker node runs a daemon called the “Supervisor”. The supervisor listens for work assigned to its machine and starts and stops worker processes as necessary based on what Nimbus has assigned to it. Each worker process executes a subset of a topology; a running topology consists of many worker processes spread across many machines.
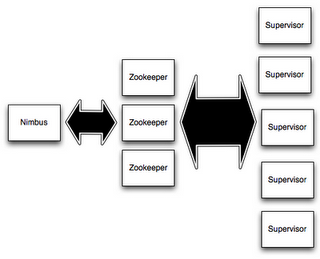
- All coordination between Nimbus and the Supervisors is done through a Zookeeper cluster. Additionally, the Nimbus daemon and Supervisor daemons are fail-fast and stateless; all state is kept in Zookeeper or on local disk. This means you can kill -9 Nimbus or the Supervisors and they’ll start back up like nothing happened. This design leads to Storm clusters being incredibly stable.
Advanced Storm Controller
- STORM PHASES
- Default – Want the same storm as the Battle Royale mode Use this setting. You don’t have to use storm beacons for this one, but if you want to adjust wait time or damage for example you can use them.
- Custom – Want to make your own storm? Use this setting.
PHASE ONE RADIUS
- The radius of the first storm circle (5 m = the length of one floor structure). Keep in mind this is the radius of the circle, not the diameter.
DELAY TIME
- Time before the storm appears
STARTING PHASE
- If Storm Phases is set to default, you can skip to a certain storm phase (for example the last few circles where the storm moves).
- If Storm Phases is set to custom, this is pretty much useless. It might be good for testing.
LATE PHASES MOVE
- If Storm Phases is set to default, you can choose whether the last 5 storm circle can move outside of the previous phase. Just like in Battle Royale.
- If Storm Phases is set to custom, you can ignore this setting.
Advanced Storm Beacon
- Every setting (except for the phase number) has a don’t override setting which will use the default setting, so the setting from Battle Royale.
PHASE
- Select the storm phase you want to customize
END RADIUS
- The radius the storm will resize to.
NOTE: The first storm phase will use the setting from the Advanced Storm Controller. You can ignore this setting for phase 1.
WAIT TIME
- The time before the storm begins to resize
NOTE: This one is kinda confusing because it uses the wait time from the previous phase. Phase 1 uses the delay time from the Advanced Storm Controller. Phase 2 uses the wait time you set for phase 1. Phase 3 uses the wait time you set for phase 2 etc.
RESIZE TIME:
- The time it takes for the storm to resize
NOTE: Just like the wait time setting, this uses the resize time from the previous phase. Phase 1 appears instantly after the delay time from the Advanced Storm Controller. Phase 2 uses the resize time you set for phase 1 etc.
DAMAGE:
- How much damage the storm does.
- This setting is in %. So if you have 10,000 HP and the damage is set to 10%. You’ll lose 1,000 HP every tick.
MOVEMENT BEHAVIOR:
- NONE – I don’t know exactly what this is because I see no difference between this and the don’t override setting.
- MOVE RANDOMLY – This setting will use the move distance min/max settings.
- MOVE TO BEACON – Move the circle to the beacon’s position.
MOVE DISTANCE MIN/MAX:
- You can only use these settings if movement behavior is set to move randomly.
- Here are a few examples on how it works:
If min and max are both set to 0 meters, the circle will always be centered.If min is set to 0m, and max is set to 50 m. The game will choose a random angle, let’s take 45 degrees for example. And the distance between the old circle could be anywhere between 0 and 50 meters. See image:
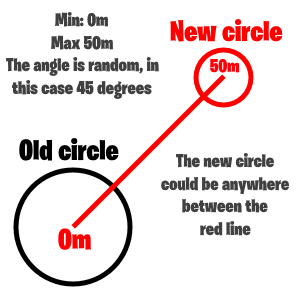
Move randomly
- If min and max is both set to 50 m. The game will choose a random angle, but the distance will always be 50 meters.
- If you don’t want the storm to move outside of the previous storm, you have to keep the maximum distance in mind:
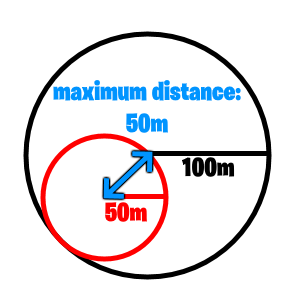
Move distance
- Small tip: If you set both min and max to 0 m in phase 1, the first circle will always be in the center of the island.
CONCLUSION:
The storm is a free and open source distributed real-time computation framework written in Clojure programming language. Apache storm is an advanced big data processing engine that processes real-time streaming data at an unprecedented (never done or known before) Speed, which is faster than Apache Hadoop.




