
Last updated on 02nd Jul 2020| 2853
Apache Oozie is the tool in which all sort of programs can be pipelined in a desired order to work in Hadoop’s distributed environment. Oozie also provides a mechanism to run the job at a given schedule.
This tutorial explains the scheduler system to run and manage Hadoop jobs called Apache Oozie. It is tightly integrated with Hadoop stack supporting various Hadoop jobs like Hive, Pig, Sqoop, as well as system specific jobs like Java and Shell.
This tutorial explores the fundamentals of Apache Oozie like workflow, coordinator, bundle and property file along with some examples. By the end of this tutorial, you will have enough understanding on scheduling and running Oozie jobs on Hadoop cluster in a distributed environment.
What is Apache Oozie?
- Apache Oozie is a scheduler system to run and manage Hadoop jobs in a distributed environment. It allows to combine multiple complex jobs to be run in a sequential order to achieve a bigger task. Within a sequence of task, two or more jobs can also be programmed to run parallel to each other.
- One of the main advantages of Oozie is that it is tightly integrated with Hadoop stack supporting various Hadoop jobs like Hive, Pig, Sqoop as well as system-specific jobs like Java and Shell.
- Oozie is an Open Source Java Web-Application available under Apache license 2.0. It is responsible for triggering the workflow actions, which in turn uses the Hadoop execution engine to actually execute the task. Hence, Oozie is able to leverage the existing Hadoop machinery for load balancing, fail-over, etc.
- Oozie detects completion of tasks through callback and polling. When Oozie starts a task, it provides a unique callback HTTP URL to the task, and notifies that URL when it is complete. If the task fails to invoke the callback URL, Oozie can poll the task for completion.
Following three types of jobs are common in Oozie −
Oozie Workflow Jobs
These are represented as Directed Acyclic Graphs (DAGs) to specify a sequence of actions to be executed.
Oozie Coordinator Jobs
These consist of workflow jobs triggered by time and data availability.
Oozie Bundle
These can be referred to as a package of multiple coordinator and workflow jobs.
We will look into each of these in detail in the following chapters.
A sample workflow with Controls (Start, Decision, Fork, Join and End) and Actions (Hive, Shell, Pig) will look like the following diagram −
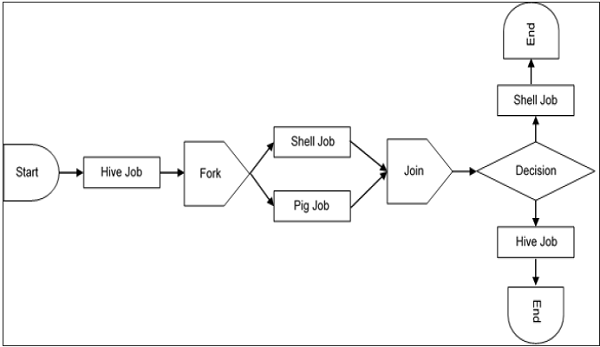
Workflow will always start with a Start tag and end with an End tag.
Use-Cases of Apache Oozie
Apache Oozie is used by Hadoop system administrators to run complex log analysis on HDFS. Hadoop Developers use Oozie for performing ETL operations on data in a sequential order and saving the output in a specified format (Avro, ORC, etc.) in HDFS.
In an enterprise, Oozie jobs are scheduled as coordinators or bundles.
How Oozie Works
- An Oozie Workflow is a collection of actions arranged in a Directed Acyclic Graph (DAG) . Control nodes define job chronology, setting rules for beginning and ending a workflow. In this way, Oozie controls the workflow execution path with decision, fork and join nodes. Action nodes trigger the execution of tasks.
- Oozie triggers workflow actions, but Hadoop MapReduce executes them. This allows Oozie to leverage other capabilities within the Hadoop stack to balance loads and handle failures.
- Oozie detects completion of tasks through callback and polling. When Oozie starts a task, it provides a unique callback HTTP URL to the task, thereby notifying that URL when it’s complete. If the task fails to invoke the callback URL, Oozie can poll the task for completion.
- Often it is necessary to run Oozie workflows on regular time intervals, but in coordination with unpredictable levels of data availability or events. In these circumstances, Oozie Coordinator allows you to model workflow execution triggers in the form of the data, time or event predicates. The workflow job is started after those predicates are satisfied.
- Oozie Coordinator can also manage multiple workflows that are dependent on the outcome of subsequent workflows. The outputs of subsequent workflows become the input to the next workflow. This chain is called a “data application pipeline”.
Oozie Editors
Before we dive into Oozie lets have a quick look at the available editors for Oozie.Most of the time, you won’t need an editor and will write the workflows using any popular text editors (like Notepad++, Sublime or Atom) as we will be doing in this tutorial.
But as a beginner it makes some sense to create a workflow by the drag and drop method using the editor and then see how the workflow gets generated. Also, to map GUI with the actual workflow.xml created by the editor. This is the only section where we will discuss about Oozie editors and won’t use it in our tutorial.The most popular among Oozie editors is Hue.Hue Editor for Oozie.This editor is very handy to use and is available with almost all Hadoop vendors’ solutions.
The following screenshot shows an example workflow created by this editor.
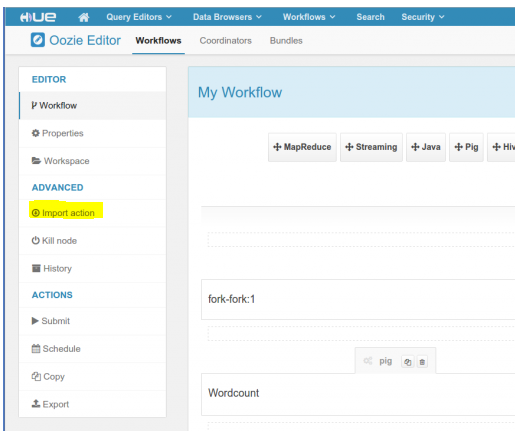
You can drag and drop controls and actions and add your job inside these actions.
Oozie Eclipse Plugin (OEP)
Oozie Eclipse plugin (OEP) is an Eclipse plugin for editing Apache Oozie workflows graphically. It is a graphical editor for editing Apache Oozie workflows inside Eclipse.
Composing Apache Oozie workflows is becoming much simpler. It becomes a matter of drag-and-drop, a matter of connecting lines between the nodes.
The following screenshots are examples of OEP.
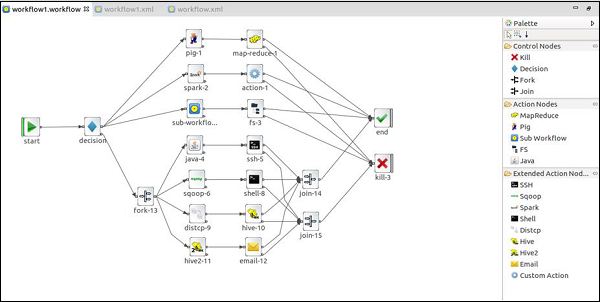
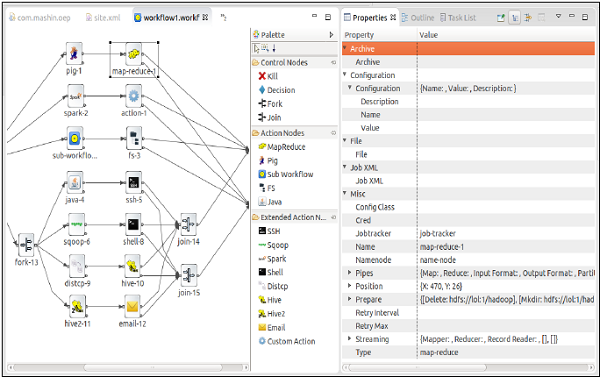
Property File
Oozie workflows can be parameterized. The parameters come from a configuration file called as property file. We can run multiple jobs using same workflow by using multiple .property files (one property for each job).Suppose we want to change the jobtracker url or change the script name or value of a param.We can specify a config file (.property) and pass it while running the workflow.
Property File
Variables like ${nameNode} can be passed within the workflow definition. The value of this variable will be replaced at the run time with the value defined in the ‘.properties’ fil.
Apache Oozie Coordinator
There is some workflow that needs to be regularly scheduled, and there is some workflow that is complex to schedule. Both kinds of workflow can be quickly scheduled by using Oozie Coordinator. Event predicates, data, and time are used as the basis for the workflow trigeneration by Oozie Coordinators. On the satisfaction of a condition, the Job coordinator starts the workflows.

Get Comprehensive Apache Oozie Training to Build Your Skills & Advance Your Career
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
Here are some of the Definition one needs to understand for the coordinator jobs:
- frequency – For the purpose of the job execution, frequency is mentioned, and it is counted in minutes.
- timezone – This tells us about the coordinator application’s timezone.
- end – It refers to the job’s end datetime.
- start – It refers to the job’s start datetime.
Let us now learn more about the Control Information’s properties:
execution- The jobs are executed in order, and the execution specifies it. Whenever different job coordinator meets multiple criteria of execution, then execution comes to tell the order in which the jobs should be executed. These are the kinds of execution:
- LAST_ONLY
- LIFO
- FIFO – It is the standard default execution one can find but can also be changed to another type of execution according to the desire of the individual.
- Concurrency – It is the property to control the maximum no. of action that can be taken for a job when the jobs are running parallely. One is the default value of the concurrency, which means at one time, only one action can be taken parallelly.
- Timeout – It is the property that helps to decide the time limit of an action to wait before it is discarded. The action will be immediately timed out if the value is 0, and no input conditions can satisfy the materialization of action. The action can also wait forever without being discarded ever if one has mentioned the value as -1. -1 is the default value of timeout.
Apache Oozie Bundle
The data pipeline is the set of coordinator applications. The execution and definition of the data pipeline are allowed by the Oozie Bundle system. Coordinator applications are not clearly dependent on each other in an Oozie bundle. Data application pipeline can be easily created by using the coordinator applications’ data dependency. The bundle can be rerun, resumed, suspended, stopped, and started by any person. Operational control of the Oozie Bundle is effortless and better to use.
Kick-off-time – It is the time of the submitting and starting of the coordinator applications by a bundle.Now, as we move forward, we will know how the creation of the workflow job is done:
Apache Oozie Word Count Workflow Job
With the use of Apache Oozie, one can do the execution of Word Count Job. All the files will be placed after the directory of WordCountTest is created. All the word count jar is placed after the creation of the lib directory.
Job and the associated parameters will be specified in the file of workflow.xml and job.properties after it is created.
1. job.properties
ResourceManager and NameNode’s are defined in the file of job.properties after it is created. The path of NameNode resolves the path of the directory of the workflow. Jobs are submitted to YARN with the help of the path of JobTracker. HDFS stores the path of the workflow.xml file and is provided by the user.
2. workflow.xml
All the execution and actions are defined in the file called workflow.xml after the user creates it. WorkflowRunnerTest is the name of the workflow-app which has to be specified by the user. After that, the Start node will be determined by the user.
For a workflow job, the entry point is called the start node. The job will start after the point of start is mentioned in the first node of the workflow. After the mentioning of the start node, the job will start from the next node called intersection0.
In the next step, in the action node, the user needs to specify the task that should be performed. The mission of WordCount of MapReduce will be executed now. The task of the WordCount of MapReduce is completed after the user specifies the required configuration. The user then defines the address of the NameNode and the Job Tracker.
The next action is to prepare the element. The cleaning up of the directory is done by using the feature. The directory cleanup is done before the action execution. Now we are going to operate to delete in HDFS. If the out1 folder is created already, we will remove the out1 folder. Before the execution of the job, deletion or creation of a folder is done using prepare tags. Output value class, output key class, reducer class, mapper class, job queue name are some of the properties of the MapReduce specified by the user.
Command Line Tools And Action Extensions
By this time, you have a good understanding of Oozie workflows, coordinators and bundles. In the last part of this tutorial, let’s touch base some of the other important concepts in Oozie.
Command Line Tools
We have seen a few commands earlier to run the jobs of workflow, coordinator and bundle. Oozie provides a command line utility, Oozie, to perform job and admin task
Action Extensions
We have seen hive extensions. Similarly, Oozie provides more action extensions few of them are as below −
Email Action
The email action allows sending emails in Oozie from a workflow application. An email action must provide to addresses, cc addresses (optional), a subject and a body. Multiple recipients of an email can be provided as comma separated addresses.
Shell Action
The shell action runs a Shell command. The workflow job will wait until the Shell command completes before continuing to the next action.
To run the Shell job, you have to configure the shell action with the =job-tracker=, name-node and Shell exec elements as well as the necessary arguments and configuration. A shell action can be configured to create or delete HDFS directories before starting the Shell job.
Installation of Oozie
The Java web-application OOZIE can be installed on machine that already have Hadoop framework installed, using either a Debian install package, RPM, or a tarball. Some Hadoop installations come preinstalled with the OOZIE application such as the Cloudera CDH3. In such framework, installation of OOZIE can be done by pulling the OOZIE package down using yum and performing installation on edge node.OOZIE installation media comes with two different components- OOZIE client and OOZIE server. Based on the size of the machine cluster, one can either chose to have both the OOZIE client and server installed on the same edge node or two separate machines.
The server component of OOZIE consist of elements that are used to launch and control different jobs in the process, while the client server of OOZIE consists of components that allow a user the ability to launch the jobs and make communication with the server components of application.
Oozie Features & Benefits
Oozie is a Java application that can run on Hadoop platform. Following features are provided by Oozie to the Hadoop developers:
- A command line interface and client API are provided by Oozie that can be used to control, launch, and monitor the jobs from Java applications
- Web services API are available in Oozie that can help in controlling the jobs from anywhere
- Periodical jobs can also be scheduled through Oozie
- Email notifications can be sent at the time when any job completes, so proper job execution can easily be done.
Conclusion
Oozie is an Apache open source project that makes straightforward the process of generating workflow and coordination between Hadoop-based jobs. Since it is a Big Data tool it is linearly separable and it can be used as s daily coordinator job. Indeed, if users do not have this tool they will probably have to write themselves their daily routine. Connecting and automating the implementation of Big Data processing tasks into a well-defined workflow is a reasonably useful feature in real-world practices for Hadoop users. Focus –The name ‘Oozie’At that time, the engineers were in India looking for a name that convey what the system really does. Since Hadoop was named after a stuffed toy elephant, the idea was to name the tool mahout which is the Indian name for elephant keeper. But the name was already taken by another project thus, after more research, Oozie, which is the Burmese word for elephant keeper, popped up and it stuck.
Finally, we came to an end of the tutorial and hoped that you liked the tutorial and learned something about Apache Oozie. This article is a good start for any beginner who is interested in learning the basic concept of the Apache Oozie.




