
Last updated on 09th Jul 2020| 2018
Apache storm is an open source distributed system for real-time processing. It can process unbounded streams of Big Data very elegantly. Storm can be used with any language because at the core of Storm is a Thrift Definition for defining and submitting topologies. Thrift can be used in any language and topologies can be defined and submitted from any language.
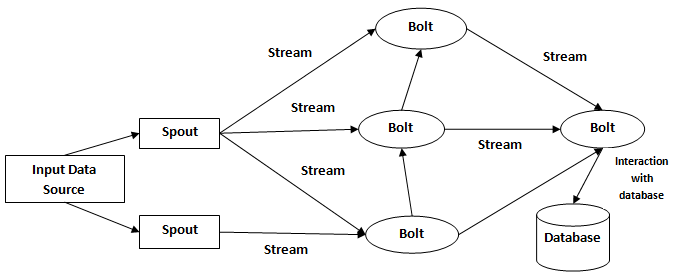
Storm Architecture
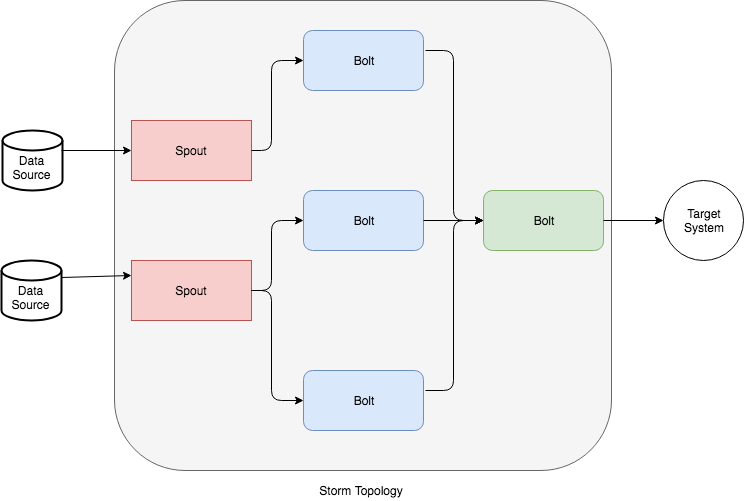
- Topology: The complete logic for defining a series of steps, streams, and bolts are defined in the Topology. It also contains definitions to specify if a local topology or a remote topology are required.
- Spouts: A spout is a stream source for bolts. It reads data from different data sources and emits a tuple as its output. A spout can further be categorized into the below two categories:
- Reliable: It replays a tuple if it is not processed by any bolt.
- Unreliable: It does not replays a tuple even if it is not processed by any bolt.
- Bolts: A bolt processes the tuple emitted by a spout. There can be multiple bolts in a topology that can be used to either perform sequential or parallel execution of tuples. Bolts can be used to perform filtering, aggregation, joins, etc. A complete operation, like processing data from Twitter, may require multiple bolts that will execute sequentially for performing operations like: filtering relevant tweets, using a bolt for aggregating the hashtags, and then using another bolt for writing it in a file as an output.
- Tuple: A tuple is a list of value that may be of the same or different types
The Components Of Storm
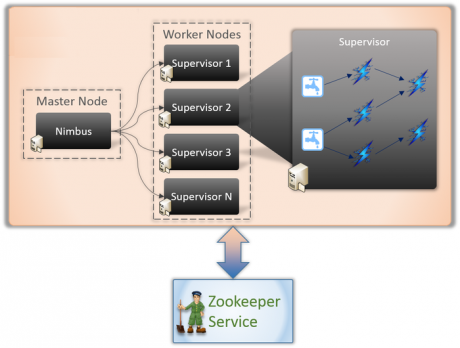
- In a Storm cluster, nodes are organized into a master node that runs continuously.
- There are two kind of nodes in a Storm cluster: master node and worker nodes. Master node run a daemon called Nimbus, which is responsible for distributing code around the cluster, assigning tasks to each worker node, and monitoring for failures. Worker nodes run a daemon called Supervisor, which executes a portion of a topology. A topology in Storm runs across many worker nodes on different machines.
- Since Storm keeps all cluster states either in Zookeeper or on local disk, the daemons are stateless and can fail or restart without affecting the health of the system

Installing Storm in a Single Node Cluster
- For installing Storm, you need to have Zookeeper in your single node cluster. So, let’s start with the installation of Zookeeper.
Zookeeper Installation:
- Step 1: Download Zookeeper from the below link:
http://mirror.fibergrid.in/apache/zookeeper/zookeeper-3.4.6/
- Step 2: After downloading, untar it by using the command tar -xvzf zookeeper-3.4.6.tar.gz.
- Step 3: Now, create a directory for storing the Zookeeper data, as it needs to store the PID’s of the processes that are running. Here we have created the folder with the name zookeeper in the zookeeper-3.4.6 directory.
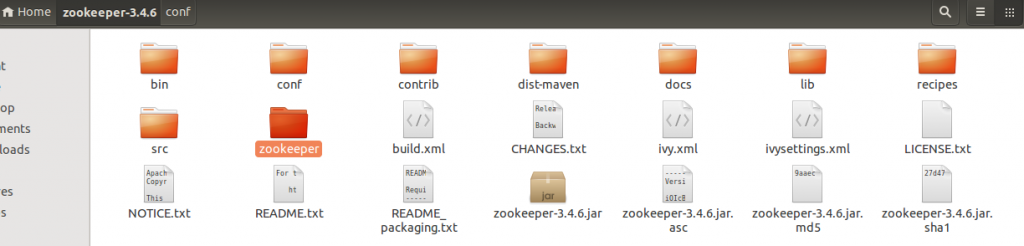
- Step 4: Next, move into the conf folder of the installed Zookeeper and copy the zoo_sample.cfg file as zoo.cfg using the command cp zoo_sample.cfg zoo.cfg.
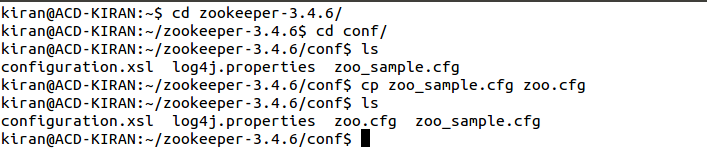
- Now, open the zoo.cfg and give the path of the directory created for storing zookeeper’s data. You can refer to the below screen shot for the same.
- We are done! We have successfully installed the Zookeeper service in your single node Hadoop cluster.
- Let’s now export the path of Zookeeper into bashrc file. Move into your home directory using cd command and open the bashrc file using the command gedit .bashrc and type the below lines in the bashrc file.
#set Zookeeper home
export ZOOKEEPER_HOME=/home/kiran/zookeeper-3.4.6[Here you should give the path of the installed zookeeper directory]
export PATH=$PATH:$ZOOKEEPER_HOME/bin
- After adding the lines, close and save the file.
- Now, source the file using the command source .bashrc.

Step 5: Start the Zookeeper service by typing the command ZkServer.sh start.
Now, let’s move on to the installation of Storm.
Storm Installation:
- Step 1: Download Storm from the below link:
http://www.apache.org/dyn/closer.lua/storm/apache-storm-1.0.1/apache-storm-1.0.1.t
- Step 2: After downloading, untar it by using the below command:
tar -xvzf apache-storm-1.0.1.tar.gz
- Step 3: Now, create a folder in the location of your choice, for storing the Storm data. We have created a folder in the apache-storm-1.0.1 directory itself.
- Step 4: Now, move into the conf folder and open the storm.yaml file and add the below specified properties. Before that please note that in the storm.local.dir you need to give the path of the directory created for storing Storm data.
storm.zookeeper.servers:
- “localhost”
- storm.local.dir:”/home/kiran/apache-storm-1.0.1/data”[Here you need to give the unrated apache-storm-1.0.1 directory]
- nimbus.host: “localhost”
- supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
- After adding these properties, close and save the file.
- Step 5: Now open the bashrc file from your home directory and export the path for Storm. Add the below lines in your bashrc file.

Learn Practical Oriented Apache Storm Training & Certification Course from Real Time Experts
Weekday / Weekend BatchesSee Batch Details- #set Storm home
- export STORM_HOME=/home/kiran/apache-storm-1.0.1
- export PATH=$PATH:$STORM_HOME/bin
- After adding the lines, close and save the file.
- Next, source the file using the command source .bashrc.

- Step 6: Start the Storm services using the below commands.As like a Hadoop cluster, storm cluster also has two kinds of nodes
1.Master Node
2.Worker Nodes
- The master node runs a daemon called “Nimbus” that is similar to Hadoop’s “Job Tracker”. Nimbus is responsible for distributing code around the cluster, assigning tasks to machines, and monitoring for failures.
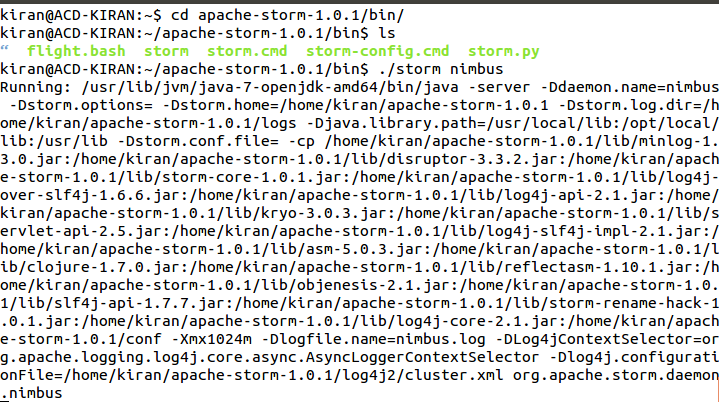
- To Start storm nimbus, open a new terminal and move into the bin directory of installed Storm and type the command ./storm nimbus.
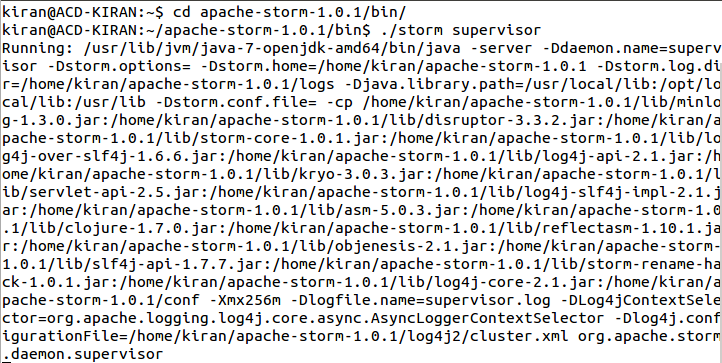
- Each worker node runs a daemon called the “Supervisor”. The supervisor listens for work assigned to its machine and starts and stops worker processes as necessary based on what Nimbus has assigned to it.
- To start the Storm supervisor, open a new terminal and move into the bin directory of the installed Storm and type the command ./storm supervisor.
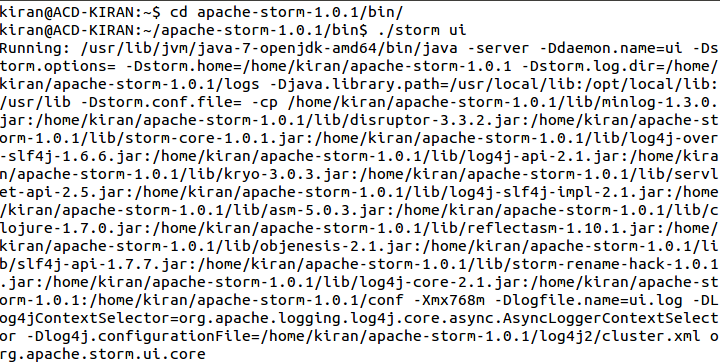
- Storm jobs can be traced using its web interface. Storm provides a web user interface from the default port 8080.
- To start the Storm UI, open a new terminal and move into the bin directory of installed Storm and type the command ./storm ui.
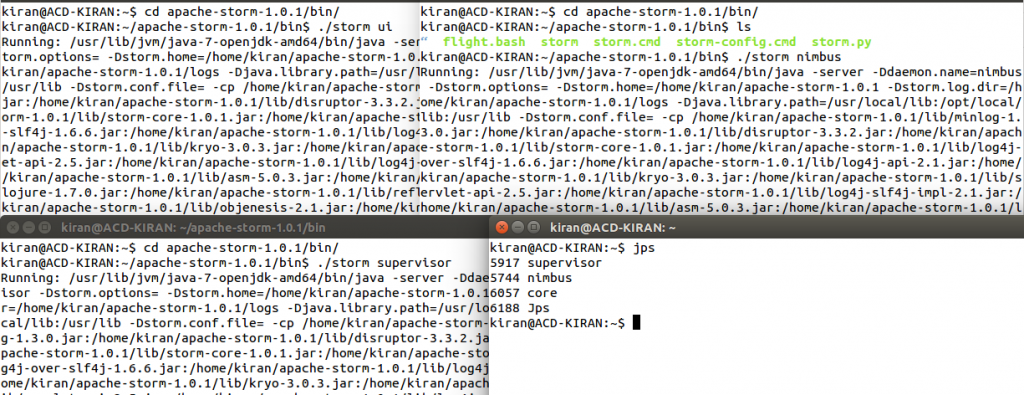
- Now, you can check the Storm services running by using the jps command. You can refer to the below screenshot for the same.
- You can also check the status of your Storm cluster by using the UI. For that, open any web browser and type localhost:8080, where 8080 is the port where Storm is running. You can check the status of your Storm using web UI. You can refer to the below screen shot for the same.
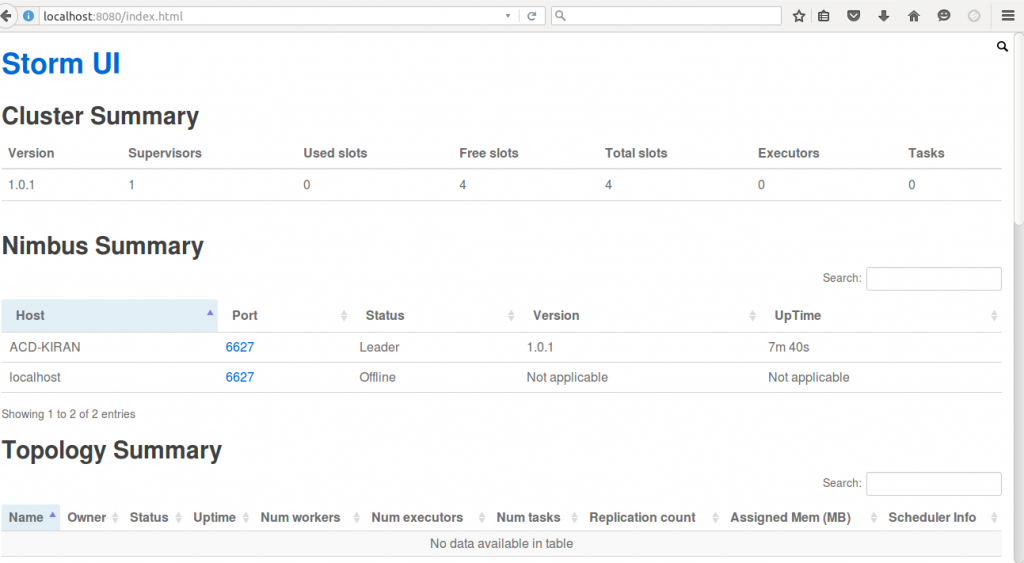
- In the above screen shot, we can see the web UI of Storm in a single node cluster..
Features of Storm
a) Fast: Storm has been reported to process up to 1 million tuples per second per node.
b) Horizontally scalable: Being fast is a necessary feature to build a high volume/velocity data processing platform, but a single-node will have an upper limit on the number of events that it can process per second. A node represents a single machine in your setup that execute Storm applications. Storm, being a distributed platform, allows you to add more nodes to your Storm cluster and increase the processing capacity of your application. Also, it is linearly scalable, which means that you can double the processing capacity by doubling the nodes.
c) Fault tolerant: Units of work are executed by worker processes in a Storm cluster. When a worker dies, Storm will restart that worker, and if the node on which the worker is running dies, Storm will restart that worker on some other node in the cluster. The descriptions of the worker process is mentioned in the Configuring the parallelism of a topology section of, Setting Up a Storm Cluster.
d) Guaranteed data processing: Storm provides strong guarantees that each message passed on to it to process will be processed at least once. In the event of failures, Storm will replay the lost tuples. Also, it can be configured so that each message will be processed only once.
e) Easy to operate: Storm is simple to deploy and manage. Once the cluster is deployed, it requires little maintenance.

Get On-Demand Apache Storm Training to Build Your Skills & Advance Your Career
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
f) Programming language agnostic: Even though the Storm platform runs on Java Virtual Machine, the applications that run over it can be written in any programming language that can read and write to standard input and output streams.
The Properties of Storm
- Simple to program: If you’ve ever tried doing real-time processing from scratch, you’ll understand how painful it can become. With Storm, complexity is dramatically reduced.
- Support for multiple programming languages: It’s easier to develop in a JVM-based language, but Storm supports any language as long as you use or implement a small intermediary library.
- Fault-tolerant: The Storm cluster takes care of workers going down, reassigning tasks when necessary.
- Scalable: All you need to do in order to scale is add more machines to the cluster. Storm will reassign tasks to new machines as they become available.
- Reliable: All messages are guaranteed to be processed at least once. If there are errors, messages might be processed more than once, but you’ll never lose any message.
- Fast: Speed was one of the key factors driving Storm’s design.
- Transactional: You can get exactly once messaging semantics for pretty much any computation.
Use Cases for Storm

- Processing streams
- As demonstrated in the preceding example, unlike other stream processing systems, with Storm there’s no need for intermediate queues.
- Continuous computation
- Send data to clients continuously so they can update and show results in real time, such as site metrics.
- Distributed remote procedure call
- Easily parallelized CPU-intensive operations.
Advantages:
- Apache Storm is a highly real-time analysis platform and hence permits real-time processing.
- It is open-source and user-friendly so incorporated with small and high industries.
- It is high-speedy, valid and generates genuine and authentic results.
- It has the operational potential of intelligence and strong capacity for processing.
- It can absorb vast volume and giant velocity of data so much compatible with big datasets.
- It is attainable, flexible and assists any programming language
Conclusion:
The storm is a free and open source distributed real-time computation framework written in Clojure programming language. Apache storm is an advanced big data processing engine that processes real-time streaming data at an unprecedented (never done or known before) Speed, which is faster than Apache Hadoop.




