
Last updated on 21st Jan 2022| 2510
- Introduction to Controlling Hadoop
- Hadoop comprises of four principle modules
- How Hadoop Works
- About Hadoop
- Running Hadoop on AWS
- History of Hadoop
- The Hadoop High-level Architecture
- The Apache Hadoop Module
- Types of Hadoop
- The Scope of Hadoop
- Benefits of Hadoop
- Features
- Hadoop Assumptions
- Hadoop Design Principles
- Hadoop makes it more straightforward to involve all the capacity and handling limit in group servers, and to execute dispersed cycles against colossal measures of information. Hadoop gives the structure blocks on which different administrations and applications can be assembled.
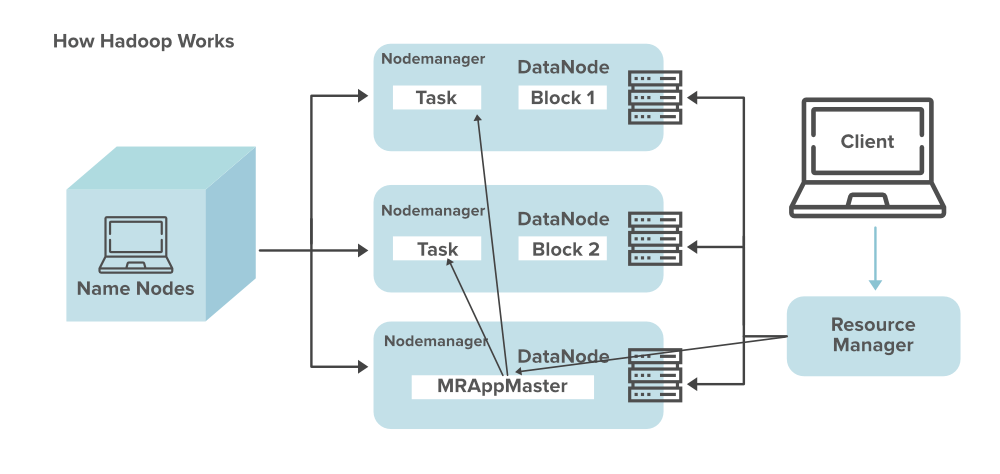
- Applications that gather information in different organizations can put information into the Hadoop bunch by utilizing an API activity to interface with the NameNode. The NameNode tracks the record index construction and position of “pieces” for each document, recreated across DataNodes.
- To run something important to question the information, give a MapReduce work comprised of many guide and decrease errands that run against the information in HDFS spread across the DataNodes. Map assignments run on every hub against the info records provided, and minimizers rush to total and put together the last result.
- Apache Spark utilizes in-memory storing and improved execution for quick execution, and it upholds general group handling, streaming examination, AI, diagram information bases, and impromptu inquiries.
- It upholds the ANSI SQL standard, including complex questions, totals, joins, and window capacities. Presto can handle information from various information sources including the Hadoop Distributed File System (HDFS) and Amazon S3.
- Apache Hadoop was destined to upgrade the use and tackle significant issues of large information. The web media was creating heaps of data consistently, and it was turning out to be undeniably challenging to deal with the information of around one billion pages of content. Arranged by progressive, Google imagined another approach of handling information prominently known as MapReduce. Later following a year Google distributed a white paper of Map Reducing system where Doug Cutting and Mike Cafarella, motivated by the white paper and in this way made Hadoop to apply these ideas to an open-source programming structure that upheld the Nutch internet searcher project. Considering the first contextual investigation, Hadoop was planned with a lot less complex stockpiling framework offices.
- Apache Hadoop is the main structure for working with Big Data. Hadoop greatest strength is adaptability. It overhauls from chipping away at a solitary hub to great many hubs with no issue in a consistent way.
- The various spaces of Big Data implies we can deal with the information’s are from recordings, text medium, value-based information, sensor data, factual information, online media discussions, web search tool questions, web based business information, monetary data, climate information, news refreshes, gathering conversations, chief reports, etc
- Google’s Doug Cutting and his colleagues fostered an Open Source Project in particular known as Hadoop which permits you to deal with the extremely big measure of information. Hadoop runs the applications based on MapReduce where the information is handled in equal and achieve the whole factual examination on big measure of information.
- It is a structure which depends on java programming. It is planned to work upon from a solitary server to great many machines each offering nearby calculation and capacity. It upholds the enormous assortment of informational index in a dispersed registering climate.
- The Apache Hadoop programming library based system that gives consents to disperse gigantic measure of informational indexes handling across groups of PCs utilizing simple programming.
- Overseeing of the Hadoop structure is profoundly effective, secure and reliable.
- The executives of group activities with a natural web UI and a vigorous API
- The establishment and setup of Hadoop group are rearranged viably.
- It is utilized to help mechanization, brilliant design and suggestions
- Progressed bunch security set-up comes extra with this toolbox.
- The whole bunch can be controlled utilizing the measurements, heat guides, examination and investigating
- Expanded degrees of customization and expansion make this more important.
- Most information base administration frameworks are inadequate for working at such grandiose degrees of Big information exigencies either due to the sheer specialized wasteful. At the point when the information is absolutely unstructured, the volume of information is humongous, where the outcomes are at high velocities, then, at that point, at long last just stage that can viably confront the test is Apache.
- The MapReduce innovation gives an amazing open door to all software engineers contributes their part where big informational indexes are isolated and are freely handled in equal. These coders doesn’t have to knew the superior presentation processing and can work effectively without agonizing over intra-bunch intricacies, checking of undertakings, hub disappointment the board, etc.
- From this HDFS guarantees no work would stop in any event, when a few hubs leaving administration. HDFS claims APIs to guarantee The MapReduce program is utilized for perusing and composing information (substance) at the same time at high rates. At the point when there is a need to accelerate execution, and afterward add additional hubs in corresponding to the group and the expanded interest can be promptly met.
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
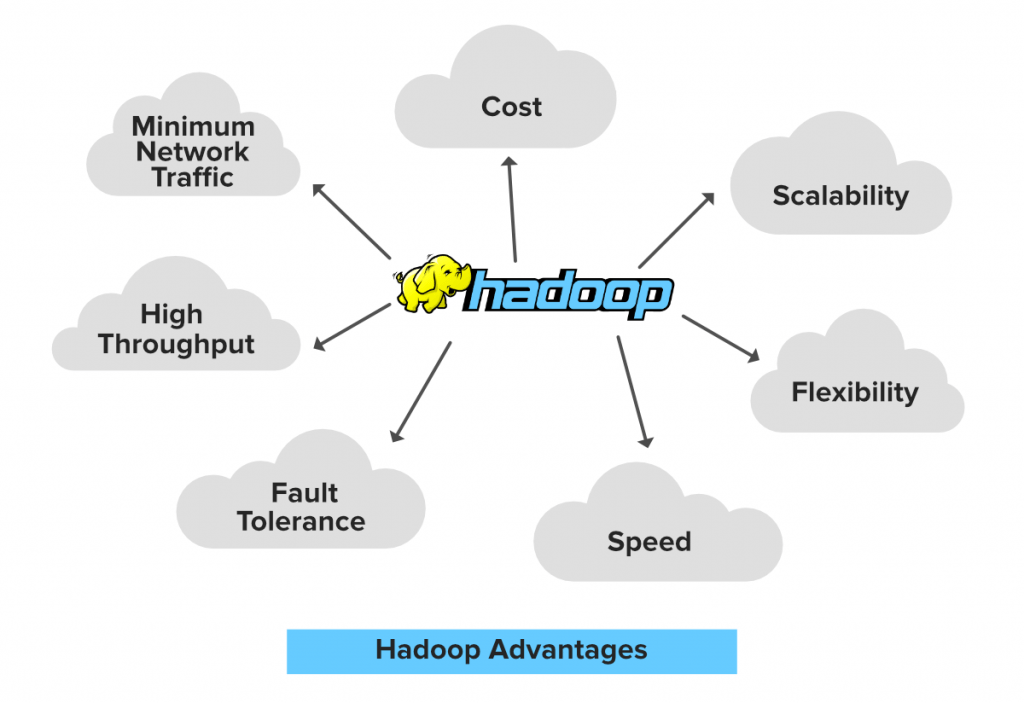
- High Availability-Data is accessible and open even there happens an equipment disappointment because of numerous duplicates of information.
- On the off chance that any episodes happened, for example, in the event that your machine or not many equipment crashes, information will be gotten to from other way.
- Versatility Hadoop is exceptionally adaptable and in a one of a kind way equipment can be effortlessly added to the hubs.
- It likewise gives flat versatility which implies new hubs can be added on the top with no personal time.
- Monetary Hadoop isn’t extravagant as it runs on bunch of item equipment.
- We don’t need any particular machine for it. Hadoop gives gigantic expense decrease since it is exceptionally simple to include more hubs the top here.
- So on the off chance that the prerequisite expands, there is an increment of hubs, with no vacation and with no a lot of pre preparation.
- Simple to utilize No need of customer to manage disseminated figuring, system deals with every one of the things. So it is not difficult to utilize.
- Information Locality-Hadoop deals with information territory rule which expresses that the development of calculation of information rather than information to. At the point when customer presents his calculation, then, at that point, the calculation is moved to information in the bunch as opposed to carrying information to the place where calculation is submitted and afterward handling it.
- Equipment might bomb because of any outer or specialized glitch where rather item equipment can be utilized.
- Handling will be run in bunches and there leaves an accentuation on high throughput instead of low idleness.
- Applications which run on HDFS have enormous arrangements of information. A run of the mill record in HDFS might be of gigabytes to terabytes in size.
- Applications require a compose once-read-many access model.
- Moving Computation is less expensive contrasted with the Moving Data.
- Framework will oversee and recuperate itself according to the prerequisite happened.
- Shortcoming Tolerant are consequently and straightforwardly course are overseen around disappointments hypothetically execute excess errands assuming that specific hubs are distinguished to be running of more slow stage.
- Execution is scaled in light of linearity.
- Relative change as far as limit with asset been change (Scalability)
- Process should be moved to information.
- Information Locality is named as lower dormancy, lower data transmission.
- Deeply, measured and extensible (Economical).
Introduction to Controlling Hadoop:
Apache Hadoop is an open source structure that is utilized to effectively store and cycle big datasets going in size from gigabytes to petabytes of information. Rather than utilizing one big PC to store and handle the information, Hadoop permits bunching numerous PCs to investigate enormous datasets in equal all the more rapidly.
Hadoop comprises of four principle modules :-
One more Resource Negotiator (YARN) – Manages and screens group hubs and asset use. It plans occupations and assignments.
MapReduce – A structure that assists programs with doing the equal calculation on information. The guide task takes input information and converts it into a dataset that can be figured in key worth sets. The result of the guide task is consumed by decrease errands to total result and give the ideal outcome.
Hadoop Common – Provides normal Java libraries that can be utilized across all modules.
How Hadoop Works :-
About Hadoop :-
Hive – Allows clients to use Hadoop MapReduce utilizing a SQL interface, empowering investigation at a gigantic scope, notwithstanding circulated and issue open minded information warehousing.
HBase- is a bigly versatile, disseminated big information store worked for arbitrary, stringently predictable, continuous access for tables with billions of lines and a big number.
Airship – An intelligent note pad that empowers intuitive information investigation.
Running Hadoop on AWS :-
Amazon EMR is an overseen administration that allows you to process and examine big datasets utilizing the most recent forms of large information handling structures like Apache Hadoop, Spark, HBase, and Presto on completely adaptable bunches.
Simple to utilize:
You can send off an Amazon EMR bunch in minutes. You don’t have to stress over hub provisioning, bunch arrangement, Hadoop setup, or group tuning.
Minimal expense:
Amazon EMR evaluating is basic and unsurprising: You pay an hourly rate for each case hour you use and you can use Spot Instances for more prominent investment funds.
Versatile:
With Amazon EMR, you can arrangement one, hundreds, or thousands of register examples to handle information at any scale.
Transient:
You can utilize EMRFS to run bunches on-request founded on HDFS information put away steadily in Amazon S3. As occupations finish, you can close down a bunch and have the information saved in Amazon S3. You pay just for the figure time that the bunch is running.
Secure:
Character and Access Management (IAM) jobs and arrangements to oversee consents. Encryption on the way and very still to assist you with securing your information and satisfy consistence guidelines, like HIPAA. Security gatherings to control inbound and outbound organization traffic to your group hubs.
AWS CloudTrail:
Audit all Amazon EMR PI calls made in your record to give security examination, asset change following, and consistence reviewing.

Learn Advanced Amazon S3 Certification Training Course to Build Your Skills
Weekday / Weekend BatchesSee Batch DetailsHistory of Hadoop:
Hadoop was made by Doug Cutting and henceforth was the maker of Apache Lucene. It is the broadly utilized text to look through library. Hadoop has its beginnings in Apache Nutch which is an open source web internet searcher itself a piece of the Lucene project.
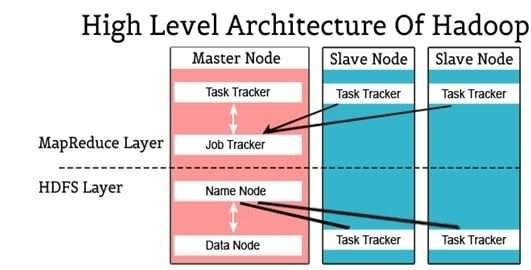
The Hadoop High-level Architecture:-
Hadoop Architecture in view of the two principle parts in particular MapReduce and HDFS.
The Apache Hadoop Module :-
Hadoop Common:
Includes the normal utilities which upholds the other Hadoop modules
HDFS:
Hadoop Distributed File System gives unlimited, high velocity admittance to the information application.
Hadoop YARN:
This innovation is fundamentally utilized for booking of work and productive administration of the bunch asset.
MapReduce:
This is an exceptionally effective approach for equal handling of colossal volumes of information. Then, at that point, there are different ventures remembered for the Hadoop module which are less utilized:
Apache Ambari:
It is an instrument for making due, checking and provisioning of the Hadoop bunches. Apache Ambari upholds the HDFS and MapReduce programs. Significant features of Ambari are:
Cassandra: It is an appropriated framework to deal with amazingly colossal measure of information which is put away across a few ware servers. The data set administration framework (DBMS)is profoundly accessible with no weak link.
HBase it is a non-social, dispersed information base administration framework that works productively on inadequate informational collections and it is profoundle.
Apache Spark This is profoundly dexterous, adaptable and secure the Big Data figure motor, versatiles the adequate work on a wide assortment of uses like ongoing handling, AI, ETL.
Hive It is an information stockroom device essentially utilized for examining, questioning and summing up of broke down information ideas on top of the Hadoop.
Pig Pig is a significant level structure which guarantees us to work in coordination either with Apache Spark or MapReduce to dissect the information. The language used to code for the systems are known as Pig Latin.
Sqoop This system is utilized for moving the information to Hadoop from social data sets. This application depends on an order line interface
Oozie This is a booking framework for work process the executives, executing work process courses for fruitful finishing of the errand in a Hadoop.
Animal handler Open source unified help which is utilized to give coordination between dispersed uses of Hadoop. It offers the vault and synchronization administration on a significant level.

Types of Hadoop :-
Hadoop Mapreduce (Processing/Computation layer) – MapReduce is an equal programming model primarily utilized for composing enormous measure of information dissemination applications contrived from Google for effective handling of a lot of datasets, on big gathering of groups.
Hadoop HDFS (Storage layer) – Hadoop Distributed File SystemorHDFS depends on the Google File System (GFS) which gives an appropriated document framework that is particularly intended to run on ware equipment. It lessens the flaws or blunders and joins minimal expense equipment. It gives significant level handling throughput admittance to application information and is appropriate for applications with big datasets.
Hadoop YARN –Hadoop YARN is a system utilized for work booking and bunch asset the executives.
Hadoop Common –This incorporates Java libraries and utilities which give those java records which are vital for start Hadoop.
Task Tracker –It is a hub which is utilized to acknowledge the assignments, for example, mix and Mapreduce structure work tracker.
Work Tracker –It is a specialist co-op which runs Mapreduce occupations on group.
Name Node – It is a hub where Hadoop stores all record area information(data put away area) in Hadoop appropriated document framework.
Information Node – It stores information in the Hadoop conveyed document framework.
The Challenges confronting Data at Scale :-
Big Data are sorted into:
Organized – which stores the information in lines and sections like social informational collections
Unstructured – here information can’t be put away in lines and segments like video, pictures, and so on
Semi-organized – information in design XML are discernible by machines and human. There is a normalized procedure that Big Data follows featuring use philosophy of ETL.
ETL – represents Extract, Transform, and Load.
Extricate – bringing the information from various sources
Change – convert the current information to squeeze into the insightful requirements
Load – right situation to determine esteem in it. Correlation with Existing Database Technologies
The Scope of Hadoop :-

Get JOB Oriented Amazon S3 Training for Beginners By MNC Experts
Benefits of Hadoop :-
It give admittance to the client to quickly compose and test the appropriated frameworks and afterward consequently disseminates the information and works across the machines and thus uses the essential parallelism of the CPU.
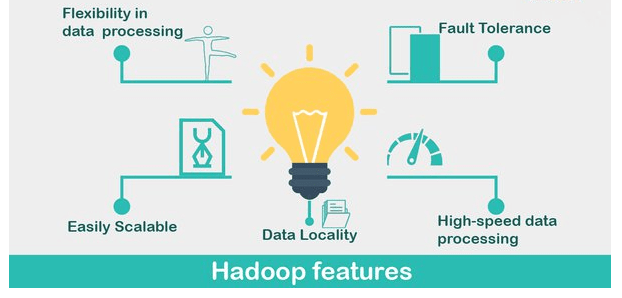
Hadoop Features and Characteristics:
Apache Hadoop is the most famous and strong enormous information device, which gives world’s best solid stockpiling layer – HDFS(Hadoop Distributed File System), a group Processing motor specifically MapReduce and a Resource Management Layer like YARN. It implies its code can be adjusted by business necessities.
Dispersed Processing- The information stockpiling is kept up with in an appropriated way in HDFS across the group, information is handled in equal on bunch of hubs.
Adaptation to non- critical failure By default the three reproductions of each square is put away across the bunch in Hadoop and it’s changed just when required. Hadoop’s shortcoming open minded can be inspected in such situations when any hub goes down, the information on that hub can be recuperated effectively from different hubs. Disappointments of a specific hub or undertaking are recuperated naturally by the system.
Unwavering quality- Due to replication of information in the group, information can be solid which is put away on the bunch of machine in spite of machine disappointments .Even in the event that your machine goes down, and furthermore your information will be put away dependably.
Features:
Hadoop Assumptions:
Hadoop is composed with enormous measure of groups of PCs as a primary concern and is based upon the accompanying suppositions:
Hadoop Design Principles:
Coming up next are the plan standards on which Hadoop works:
Conclusion:
Apache Hadoop is an open source structure that is utilized to productively store and cycle enormous datasets going in size from gigabytes to petabytes of information. Rather than utilizing one enormous PC to store and deal with the information, Hadoop permits bunching various PCs to investigate gigantic datasets in equal all the more rapidly.




