
Last updated on 18th Jan 2022| 2959
- Introduction
- Introducing Elasticsearch
- Arranging Elasticsearch
- Running Elasticsearch
- Making an Elasticsearch Index
- Elasticsearch Querying
- Elasticsearch Query DSL
- Making an Elasticsearch Cluster
- Elasticsearch Architecture
- Elasticsearch Advantages
- Elasticsearch Use-cases
- Current Demand and Future of Elasticsearch
- Conclusion
Introduction :-
Powerful, quick and exact pursuit usefulness is a vital piece of greater part of the advanced applications and programming stages. It is possible that you are running a little internet business site and need to offer your clients a hunt over item inventories, or then again you are a specialist organization and need to open an API to allow the designers to channel over clients and organizations, or you are building any sort of informing application where observing a discussion in the set of experiences is an absolute necessity have highlight from the very first moment.
Without a doubt, the pursuit could have many faces, purposes, objectives and distinctive scale. It very well may be pretty much as basic as looking by accurate word match or as mind boggling as attempting to comprehend the aim and the relevant importance of the words one’s is searching for (semantic web crawlers). As far as scale, it very well may be pretty much as minor as questioning a solitary information base table, or as mind boggling as crunching over a great many pages to convey the ideal outcomes. It is exceptionally fascinating and thriving area of exploration, with numerous calculations and papers distributed throughout the long term.
On the off chance that you are a Java/JVM designer, you might have caught wind of Apache Lucene project, a superior exhibition, full-included ordering and search library. It is the first and the top tier decision to release the force of full-text search and install it into your applications. Despite the fact that it is an awesome library definitely, numerous engineers have observed Apache Lucene excessively low-level and difficult to utilize. That is one reason why two other extraordinary activities, Elasticsearch and Apache Solr, have been conceived.
In this instructional exercise, we will discuss Elasticsearch, making an accentuation on advancement side of things rather than functional. We will gain proficiency with the rudiments of Elasticsearch, get acquainted with the phrasing and talk about various ways of running it and speak with it from inside Java/JVM applications or order line. At the finish of the instructional exercise we are going to talk about Elastic Stack to grandstand the environment around Elasticsearch and its astonishing capacities.
- The prerequisites for Elasticsearch are basic: Java 8 (explicit variant suggested: Oracle JDK form 1.8.0_131). Investigate this Logstash instructional exercise to guarantee that you are set. Likewise, you will need to ensure your working framework is on the Elastic help lattice, any other way you may clash with peculiar and eccentric issues. Whenever that is done, you can begin by introducing Elasticsearch.
- You can download Elasticsearch as an independent dispersion or introduce it utilizing the adept and yum stores. We will introduce Elasticsearch on a Ubuntu 16.04 machine running on AWS EC2 utilizing adept.
Introducing Elasticsearch :-
- sudo vim/and so on/elasticsearch/elasticsearch.yml
- network.host: “localhost”
- http.port:9200
Arranging Elasticsearch :-
Elasticsearch arrangements are finished utilizing a setup record whose area relies upon your working framework. In this document, you can design general settings (for example hub name), just as organization settings (for example host and port), where information is put away, memory, log documents, and then some.
For advancement and testing purposes, the default settings will do the trick yet it is suggested you really do a few examination into what settings you ought to physically characterize prior to going into creation.
For instance, and particularly assuming introducing Elasticsearch on the cloud, it is a decent best practice to tie Elasticsearch to either a private IP or localhost:
- {
- “name” : “33QdmXw”,
- “cluster_name” : “elasticsearch”,
- “cluster_uuid” : “mTkBe_AlSZGbX-vDIe_vZQ”,
- “rendition” : {
- “number” : “6.1.2”,
- “build_hash” : “5b1fea5”,
- “build_date” : “2018-01-10T02:35:59.208Z”,
- “build_snapshot” : bogus,
- “lucene_version” : “7.1.0”,
- “minimum_wire_compatibility_version” : “5.6.0”,
- “minimum_index_compatibility_version” : “5.0.0”
- },
- “slogan” : “You Know, for Search”
- }
Running Elasticsearch :-
Elasticsearch won’t pursue naturally establishment and you should physically begin it. How you run Elasticsearch will rely upon your particular framework. On most Linux and Unix-based frameworks you can utilize this order:
Furthermore that is it! To affirm that all is working great, just direct twist or your program toward http://localhost:9200, and you should see something like the accompanying result:
To investigate the most common way of running Elasticsearch, utilize the Elasticsearch log records situated (on Deb) in/var/log/elasticsearch/.
- twist – XPOST ‘localhost:9200/logs/my_app’ – H ‘Content-Type: application/json’ – d’
- {
- “timestamp”: “2018-01-24 12:34:56”,
- “message”: “Client signed in”,
- “user_id”: 4,
- “administrator”: bogus
- }
- ‘
Making an Elasticsearch Index :-
Ordering is the method involved with adding information to Elasticsearch. This is on the grounds that when you feed information into Elasticsearch, the information is put into Apache Lucene lists. This checks out in light of the fact that Elasticsearch utilizes the Lucene files to store and recover its information. Despite the fact that you don’t have to know a ton about Lucene, it assists with knowing how it functions when you begin quitting any funny business with Elasticsearch. Elasticsearch acts like a REST API, so you can utilize either the POST or the PUT technique to add information to it. You utilize PUT when you know the or need to determine the id of the information thing, or POST on the off chance that you need Elasticsearch to produce an id for the information thing:

Learn Advanced Elasticsearch Certification Training Course to Build Your Skills
Weekday / Weekend BatchesSee Batch Details- twist – XGET ‘localhost:9200/application/clients/4?pretty’
Elasticsearch Querying :-
When you record your information into Elasticsearch, you can begin looking and breaking down it. The least complex inquiry you can do is to bring a solitary thing. Peruse our article zeroed in solely on Elasticsearch questions.
Yet again by means of the Elasticsearch REST API, we use GET:
Elasticsearch Query DSL :-
URI look are only the start. Elasticsearch likewise furnishes a solicitation body search with a Query DSL for further developed quests. There is a wide exhibit of choices accessible in these sorts of searches, and you can blend and match various choices to get the outcomes that you require.
It contains two sorts of provisions: 1) leaf question statements that search for a worth in a particular field, and 2) compound inquiry conditions (which may contain one or a few leaf inquiry provisos).
Making an Elasticsearch Cluster :-
Keeping an Elasticsearch bunch can be tedious, particularly on the off chance that you are doing DIY ELK. However, given Elasticsearch’s strong pursuit and insightful capacities, such groups are irreplaceable. We have a more profound plunge regarding the matter with our Elasticsearch group instructional exercise, so we will involve this as a springboard for that more careful stroll through.
- $ twist – XDELETE ‘localhost:9200/application/clients/4?pretty’
- {
- “_index” : “application”,
- “_type” : “clients”,
- “_id” : “4”,
- “_version” : 2,
- “result” : “erased”,
- “_shards” : {
- “absolute” : 2,
- “effective” : 1,
- “fizzled” : 0
- },
- “_seq_no” : 1,
- “_primary_term” : 1
- }
Eliminating Elasticsearch Data :-
Erasing things from Elasticsearch is similarly just about as simple as entering information into Elasticsearch. The HTTP technique to utilize this time is-shock, shock DELETE:
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
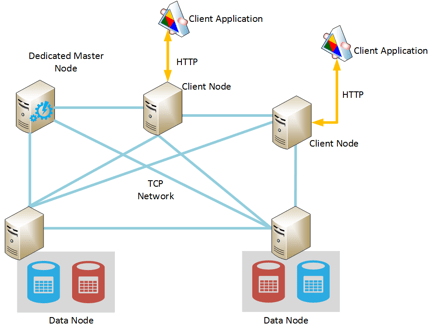
Elasticsearch Architecture :-
Elasticsearch isn’t an information store fundamentally. However, actually indeed, we can make it an information store. Elasticsearch stores archives and its adaptations. Assuming two cycles at the same time begin keeping in touch with a report, most recent form will be kept. It doesn’t uphold ACID (Atomicity, Consistency, Isolation, and Durability) properties like an information base.
Nodes and Clusters :
Node is characterized as a solitary occasion of Elasticsearch. For the most part, it runs one occasion for each machine. Groups are named as an assortment of hubs which speak with one another to peruse/keep in touch with a record. Bunch requires a special name to stay away from superfluous hubs to join the group. There is an expert hub which deals with the entire bunch. Ace hub is liable for any progressions to groups like adding a hub, eliminating a hub, making or erasing records, and so on Each group and hub has a remarkable name.
Documents and Indices :
Every hub in a group adds to the looking and ordering capacities of the bunch. For instance, assuming we have run some hunt question, every hub will execute that to look through the information it stores. Every hub upholds looking, ordering, controlling existing information.
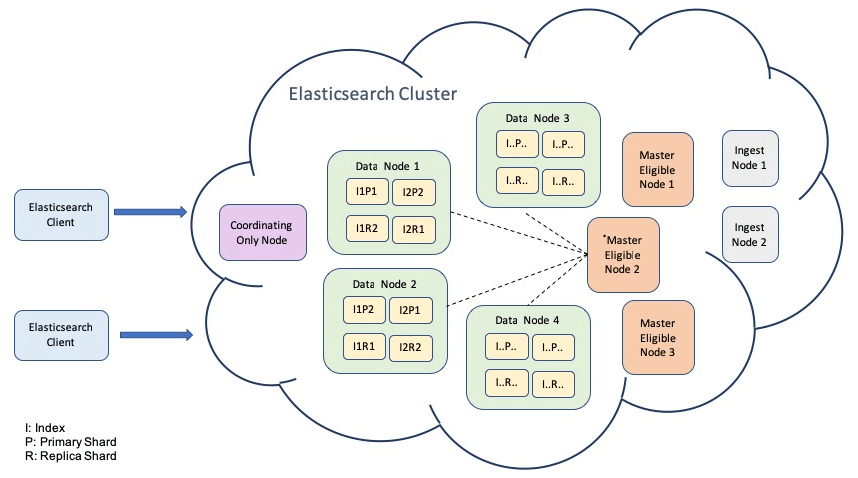
Shards and replicas :
Whatever information thing we store in the group is only the report. A report is a JSON object here and we can relate it to lines in information base wording. For instance, to store an understudy, then, at that point, you will add one item having name and standard as its properties. As we know that information will be spread across every one of the hubs, yet do we have at least some idea how to arrange it? These reports are put away under files. The file is characterized as the assortment of reports having comparable properties or we can say legitimately related. For example, a list for requests’ information, items’ information, and clients’ information.

Get JOB Oriented Elasticsearch Training for Beginners By MNC Experts
Records and Indices :
Records have their novel ID, which can be relegated by Elasticsearch or by clients while adding them to the file. Any report is exceptionally distinguished by its ID and list. There is no restriction to the quantity of records being added to the file.Lists are additionally recognized by their name. Their names can be utilized to look for any record.
Shards and imitations :
Elasticsearch involves Lucene innovation for quicker recovery of information. It utilizes the force of the Lucene file in an appropriated framework to recover information incredibly quick. Shards are named individual cases of the Lucene record. As information volume builds, record execution likewise dials back. To conquer this, Elasticsearch utilizes shards to isolate records and numerous pieces. Shards are significant due to under two reasons.
- Elasticsearch is based on Lucene – a full-highlighted data recovery library. Thus, it gives the most effective and strong full-text search abilities of an open source item. It will be extraordinary as it is well known by engineers.
- Elasticsearch has carried out a ton of elements like Faceted pursuit, altered stemming, redid parting text into words, and so on
- Elasticsearch upholds fluffy pursuit. As you can view as despite the fact that there are spelling botches in the hunt text.
- Elasticsearch upholds the IntelliSense highlight which autocompletes your inquiry text by anticipating your pursuit in light of your hunt history or finishing your text with existing labels. For instance, Google search.
- As Elasticsearch is API driven, any activity can be performed utilizing a RESTful API.
- Elasticsearch stores any progressions in information in exchange misfortune which diminishes the danger of information misfortune.
- As Elasticsearch is appropriated in nature, it is exceptionally simple to scale and incorporate Elasticsearch in any association.
- Elasticsearch upholds faceted pursuit which resembles having different channels on information alongside an order framework over them. This search is more hearty in nature than typical text-search.
- Elasticsearch executes multi-occupancy in a superior manner as an enormous Elasticsearch file.
- Utilizing Elasticsearch question DSL, it is extremely simple to plan complex inquiries and tune them unequivocally. Besides, question DSL gives a method for positioning and gathering the outcomes.
- As Elasticsearch utilizes JSON objects, it is exceptionally simple to speak with other different programming dialects.
Elasticsearch Advantages :-
The following are not many benefits of Elasticsearch:

Elasticsearch Use-cases :-
The following are not many use-cases for Elasticsearch:
An internet based store that permits its clients to investigate every one of the items they sell. For this situation, you can utilize Elasticsearch to store the entire item stock and inventory. It likewise permits clients to look and utilize autocomplete choice.
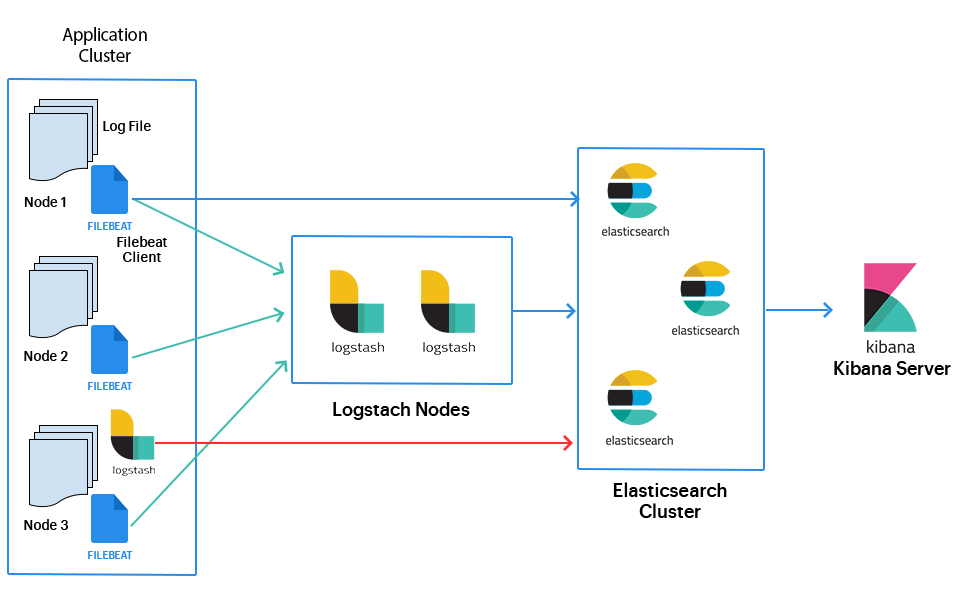
Consider a situation where you really want to store log or exchanges which you can use to investigate patterns, outlines, peculiarities or insights. For this situation, you can utilize Logstash, a piece of ELK Stack (Elasticsearch/Logstash/Kibana), to store and parse your information. Logstash assists you with taking care of information into Elasticsearch.
Have you seen the button “Tell me in the event that a thing is available” or “Advise me assuming the cost of this thing tumbles down” on internet business destinations? This component can be accomplished with the assistance of Elasticsearch. Utilizing Elasticsearch, you can switch search and have a watch on value developments or stock developments and send the alarms to clients whenever conditions are fulfilled.
Consider the prerequisite where you want to rapidly examine the information and imagine it. For this situation, Kibana can be best utilized with Elasticsearch. Elasticsearch is utilized to store information and Kibana can imagine that information in different custom dashboards. Kibana is a piece of ELK Stack (Elasticsearch, Logstash, Kibana).
Current Demand and Future of Elasticsearch :-
Elasticsearch is the most famous, open source, dispersed, cross-stage, and versatile web index. Elasticsearch is developing dramatically beginning around 2010 and establishing a surprising connection all around the IT business. Because of its dramatic development, there is an extremely appeal for gifts having Elasticsearch abilities. IT experts knowing about Elasticsearch are recruited with an extraordinary compensation and are esteemed more. It is moving in the IT business as it has an exceptionally splendid future because of its capacities to deal with a lot of information and quicker search.
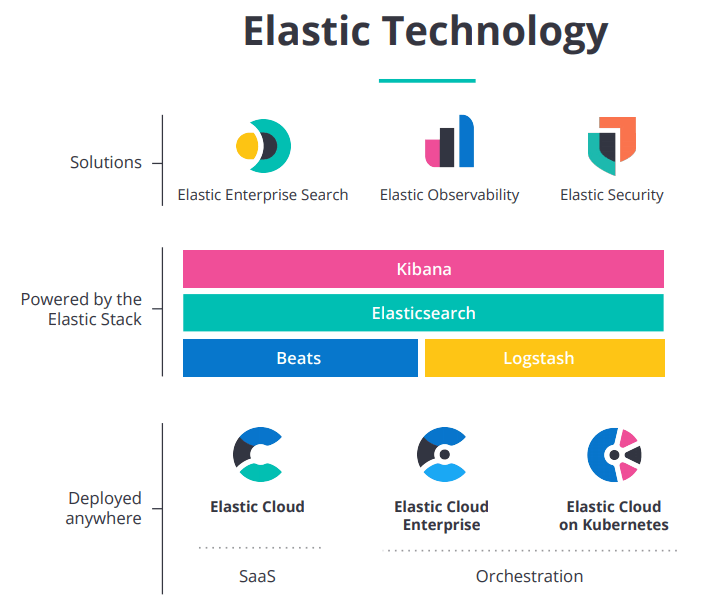
Conclusion :-
This Tutorial exercise assists amateurs with Elasticsearch and as such gives simply the fundamental stages of CRUD tasks in Elasticsearch. Elasticsearch is an internet searcher, and as such highlights a huge profundity to its inquiry highlights. Late forms have presented some extraordinary new Elasticsearch highlights and furthermore a few critical changes to the hidden information structure.




