
Last updated on 08th Jul 2020| 2098
- Apache Spark tutorial provides basic and advanced concepts of Spark. Our Spark tutorial is designed for beginners and professionals.
- Spark is a unified analytics engine for large-scale data processing including built-in modules for SQL, streaming, machine learning and graph processing.
- Our Spark tutorial includes all topics of Apache Spark with Spark introduction, Spark Installation, Spark Architecture, Spark Components, RDD, Spark real time examples and so on.
What is Spark?
- Apache Spark is an open-source cluster computing framework. Its primary purpose is to handle the real-time generated data.
- Spark was built on the top of the Hadoop MapReduce. It was optimized to run in memory whereas alternative approaches like Hadoop’s MapReduce writes data to and from computer hard drives. So, Spark process the data much quicker than other alternatives.
History of Apache Spark
- The Spark was initiated by Matei Zaharia at UC Berkeley’s AMPLab in 2009. It was open sourced in 2010 under a BSD license.
- In 2013, the project was acquired by Apache Software Foundation. In 2014, the Spark emerged as a Top-Level Apache Project.
Features of Apache Spark
Fast
- It provides high performance for both batch and streaming data, using a state-of-the-art DAG scheduler, a query optimizer, and a physical execution engine.
Easy to Use
- It facilitates writing applications in Java, Scala, Python, R, and SQL. It also provides more than 80 high-level operators.
Generality
- It provides a collection of libraries including SQL and DataFrames, MLlib for machine learning, GraphX, and Spark Streaming.
Lightweight
- It is a light unified analytics engine which is used for large scale data processing.
Runs Everywhere
- It can easily run on Hadoop, Apache Mesos, Kubernetes, standalone, or in the cloud.
Uses of Spark
Data integration:
- The data generated by systems are not consistent enough to combine for analysis. To fetch consistent data from systems we can use processes like Extract, transform, and load (ETL). Spark is used to reduce the cost and time required for this ETL process.
Stream processing:
- It is always difficult to handle the real-time generated data such as log files. Spark is capable enough to operate streams of data and refuses potentially fraudulent operations.
Machine learning:
- Machine learning approaches become more feasible and increasingly accurate due to enhancement in the volume of data. As spark is capable of storing data in memory and can run repeated queries quickly, it makes it easy to work on machine learning algorithms.
Interactive analytics:
- Spark is able to generate responses rapidly. So, instead of running pre-defined queries, we can handle the data interactively.
Need for Spark
- The traditional way of processing data on Hadoop is using its MapReduce framework. MapReduce involves a lot of disk usage and as such the processing is slower.
- As data analytics became more main-stream, the creators felt a need to speed up the processing by reducing the disk utilization during job runs.
- Apache Spark addresses this issue by performing the computation in the main memory (RAM) of the worker nodes and does not store mid-step results of computation on disk.
- Secondly, it doesn’t actually load the data until it is required for computation. It converts the given set of commands into a Directed Acyclic Graph (DAG) and then executes it. This prevents the need to read data from the disk and writing back the output of each step as is the case with Hadoop MapReduce.
- As a result, Spark claims to process data at 100X faster than a corresponding job using MapReduce for in-memory computation jobs.
Spark Architecture
The Spark follows the master-slave architecture. Its cluster consists of a single master and multiple slaves.
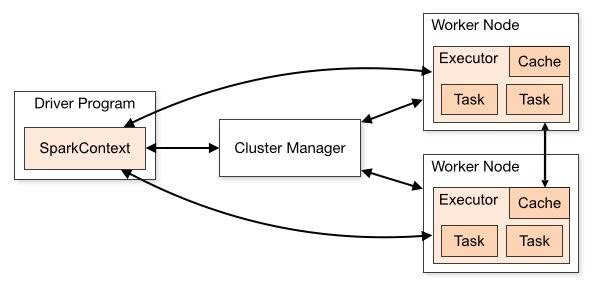
- Spark Core uses a master-slave architecture. The Driver program runs in the master node and distributes the tasks to an Executor running on various slave nodes.
- The Executor runs on their own separate JVMs, which perform the tasks assigned to them in multiple threads.
- Each Executor also has a cache associated with it. Caches can be in-memory as well as written to disk on the worker Node. The Executors execute the tasks and send the result back to the Driver.
- The Driver communicates to the nodes in clusters using a Cluster Manager like the built-in cluster manager, Mesos, YARN, etc. The batch programs we write get executed in the Driver Node.
The Spark architecture depends upon two abstractions:
- Resilient Distributed Dataset (RDD)
- Directed Acyclic Graph (DAG)
Resilient Distributed Datasets (RDD)
The Resilient Distributed Datasets are the group of data items that can be stored in-memory on worker nodes. Here,
- Resilient: Restore the data on failure.
- Distributed: Data is distributed among different nodes.
- Dataset: Group of data.
We will learn about RDD later in detail.

Get Hands-on Experience From Apache Spark Training By Expert Trainers
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
Directed Acyclic Graph (DAG)
- Directed Acyclic Graph is a finite direct graph that performs a sequence of computations on data. Each node is an RDD partition, and the edge is a transformation on top of data. Here, the graph refers the navigation whereas directed and acyclic refers to how it is done.
Let’s understand the Spark architecture.
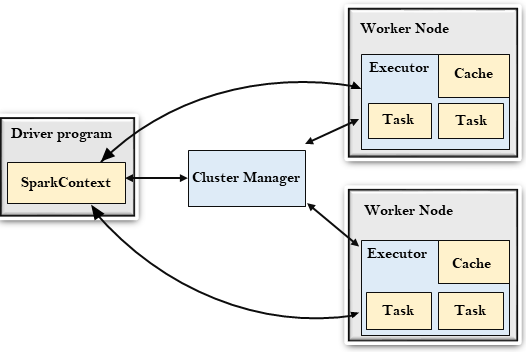
Driver Program
The Driver Program is a process that runs the main() function of the application and creates the SparkContext object. The purpose of SparkContext is to coordinate the spark applications, running as independent sets of processes on a cluster.
To run on a cluster, the SparkContext connects to a different type of cluster managers and then perform the following tasks: –
- It acquires executors on nodes in the cluster.
- Then, it sends your application code to the executors. Here, the application code can be defined by JAR or Python files passed to the SparkContext.
- At last, the SparkContext sends tasks to the executors to run.
Cluster Manager
- The role of the cluster manager is to allocate resources across applications. The Spark is capable enough of running on a large number of clusters.
- It consists of various types of cluster managers such as Hadoop YARN, Apache Mesos and Standalone Scheduler.
- Here, the Standalone Scheduler is a standalone spark cluster manager that facilitates to install Spark on an empty set of machines.
Worker Node
- The worker node is a slave node
- Its role is to run the application code in the cluster.
Executor
- An executor is a process launched for an application on a worker node.
- It runs tasks and keeps data in memory or disk storage across them.
- It read and write data to the external sources.
- Every application contains its executor.
Task
- A unit of work that will be sent to one executor.
Spark Components
The Spark project consists of different types of tightly integrated components. At its core, Spark is a computational engine that can schedule, distribute and monitor multiple applications.
Let’s understand each Spark component in detail.
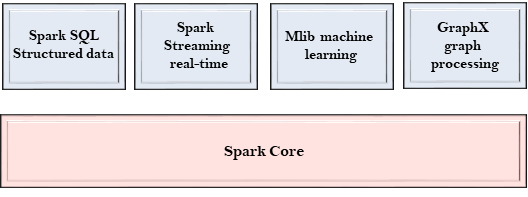
Spark Core
- The Spark Core is the heart of Spark and performs the core functionality.
- It holds the components for task scheduling, fault recovery, interacting with storage systems and memory management.
Spark SQL
Spark SQL provides a SQL-like interface to perform processing of structured data. When the user executes an SQL query, internally a batch job is kicked-off by Spark SQL which manipulates the RDDs as per the query.

Get JOB Oriented Apache Spark Certification Course with Industry Standard Modules
Weekday / Weekend BatchesSee Batch Details- The Spark SQL is built on the top of Spark Core. It provides support for structured data.
- It allows to query the data via SQL (Structured Query Language) as well as the Apache Hive variant of SQL?called the HQL (Hive Query Language).
- It supports JDBC and ODBC connections that establish a relation between Java objects and existing databases, data warehouses and business intelligence tools.
- It also supports various sources of data like Hive tables, Parquet, and JSON.
- The benefit of this API is that those familiar with RDBMS-style querying find it easy to transition to Spark and write jobs in Spark.
Spark Streaming
- Spark Streaming is a Spark component that supports scalable and fault-tolerant processing of streaming data.
- It uses Spark Core’s fast scheduling capability to perform streaming analytics.
- It accepts data in mini-batches and performs RDD transformations on that data.
- Its design ensures that the applications written for streaming data can be reused to analyze batches of historical data with little modification.
- The log files generated by web servers can be considered as a real-time example of a data stream.
- Spark Streaming is suited for applications which deal in data flowing in real-time, like processing Twitter feeds.
- Spark can integrate with Apache Kafka and other streaming tools to provide fault-tolerant and high-throughput processing capabilities for the streaming data.
MLlib
- The MLlib is a Machine Learning library that contains various machine learning algorithms.
- These include correlations and hypothesis testing, classification and regression, clustering, and principal component analysis.
- It is nine times faster than the disk-based implementation used by Apache Mahout.
- MLlib is short for Machine Learning Library which Spark provides. It includes the common learning algorithms like classification, recommendation, modeling, etc. which are used in Machine learning.
- These algorithms can be used to train the model as per the underlying data. Due to the extremely fast data processing supported by Spark, the machine learning models can be trained in a relatively shorter period of time.
GraphX
- The GraphX is a library that is used to manipulate graphs and perform graph-parallel computations.
- It facilitates to create a directed graph with arbitrary properties attached to each vertex and edge.
- To manipulate graph, it supports various fundamental operators like subgraph, join Vertices, and aggregate Messages.
- As the name indicates, GraphX is the Spark API for processing graphs and performing graph-parallel computation.
- The user can create graphs and perform operations like joining and transforming the graphs. As with MLlib, Graphx comes with built-in graph algorithms for page rank, triangle count, and more.
Create new Java Project with Apache Spark
- A new Java Project can be created with Apache Spark support. For that, jars/libraries that are present in Apache Spark package are required. The path of these jars has to be included as dependencies for the Java Project.
- In this tutorial, we shall look into how to create a Java Project with Apache Spark having all the required jars and libraries. We use Eclipse as IDE to work with the project used for demonstration in the following example. The process should be same with other IDEs like IntelliJ IDEA, NetBeans, etc.
- As a prerequisite, Java and Eclipse had to be setup on the machine.
Eclipse – Create Java Project with Apache Spark
Step 1
Download Apache Spark
The package is around ~200MB. It might take a few minutes.
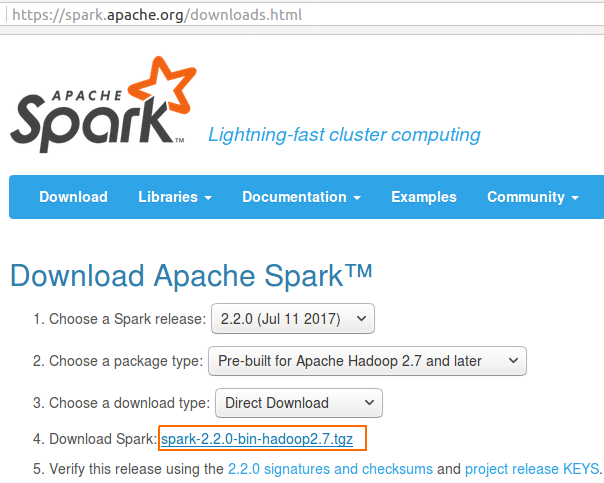
Download Apache Spark
Step 2
Unzip and find jars
Unzip the downloaded folder. The contents present would be as below :
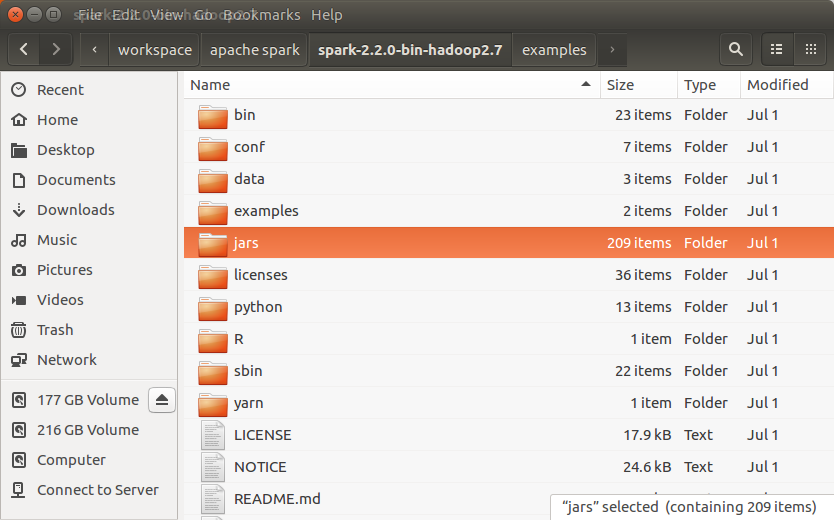
Apache Spark Package Contents
jars : this folder contains all the jars that needs to be included in the build path of our project.
Step 3
Create Java Project and copy jars
Create a Java Project in Eclipse, and copy jars folder in spark directory to the Java Project, SparkMLlib22.
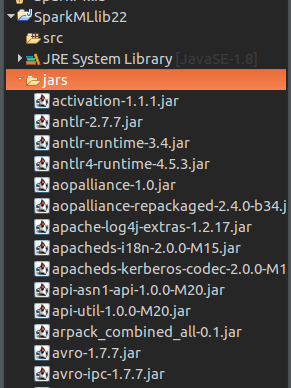
Create a Java Project and copy Jars
Step 4
Add Jars to Java Build Path
Right click on Project (SparkMLlbi22) -> Properties -> Java Build Path(3rd item in the left panel) -> Libraries (3rd tab) -> Add Jars (button on right side panel) -> In the Jar Selection, Select all the jars in the ‘jars‘ folder -> Apply -> OK.
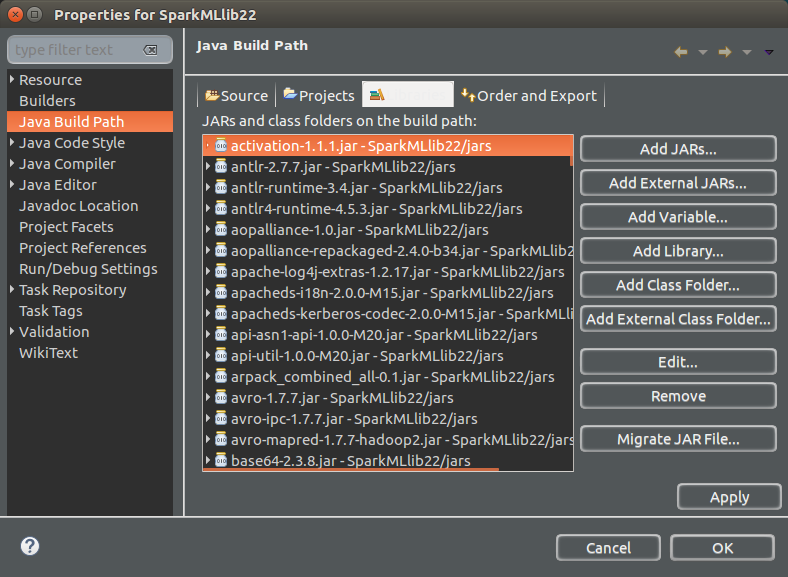
Add jars to build path
Step 5
Check the setup – Run an MLLib example
You may also copy ‘data’ folder to the project and add ‘jars’ in spark ‘examples‘ directory to have a quick glance on how to work with different modules of Apache Spark. We shall run the following Java Program, JavaRandomForestClassificationExample.java, to check if the Apache Spark setup is successful with the Java Project.
Conclusion
- Apache Spark is the platform of choice due to its blazing data processing speed, ease-of-use, and fault tolerant features.
- In this article, we took a look at the architecture of Spark and what is the secret of its lightning-fast processing speed with the help of an example. We also took a look at the popular Spark Libraries and their features.




