
Browse [LATEST] Elasticsearch Interview Questions & Answers
Last updated on 04th Jul 2020, Blog, Interview Questions
Elasticsearch stands as an open-source, distributed search and analytics engine engineered to deliver rapid search, analysis, and visualization of extensive data sets in real-time. It forms the central element of the Elastic Stack, which encompasses Kibana for data visualization and administration, Logstash for data transformation, and Beats for data gathering. Constructed upon Apache Lucene, Elasticsearch provides potent full-text searching capabilities, accommodating both structured and unstructured data. Its applications span various fields, encompassing log and event data scrutiny, text-based exploration, and real-time analytical tasks. The distributed design of Elasticsearch allows it to expand horizontally, ensuring robust availability and fault tolerance. It boasts strong extensibility, offers support for RESTful APIs, and features a comprehensive query language. Elasticsearch finds utility across a diverse spectrum of sectors, from e-commerce and finance to healthcare and cybersecurity, facilitating data exploration, analysis, and the extraction of valuable insights.
1. Describe Elasticsearch.
Ans:
Elasticsearch stands as an open-source, distributed search and analytics engine, leveraging the capabilities of the Apache Lucene search library. Its primary purpose is to efficiently store, swiftly search, and perform real-time analysis on extensive datasets. Elasticsearch seamlessly integrates with the Elastic Stack, a holistic ecosystem that encompasses complementary tools such as Logstash and Kibana, delivering a comprehensive solution for data analysis and visualization.
2. What are some of Elasticsearch’s key characteristics?
Ans:
- Distributed and Scalable: Elasticsearch is designed for distributed environments, allowing easy data distribution across multiple nodes or servers, and can handle escalating data volumes and query loads horizontally.
- Near Real-Time Search: Elasticsearch provides near real-time indexing and search, ensuring data is swiftly indexed and searchable after ingestion, making it ideal for applications requiring immediate access to current information.
- Proficient Full-Text Search: Elasticsearch is a powerful tool for full-text search, enabling users to efficiently analyze and scrutinize text data using advanced text analysis and scoring algorithms.
- Schema-Free Flexibility: Elasticsearch’s adaptability allows for seamless data ingestion without the need for predefined schemas, ensuring a seamless and dynamic experience for users.
- Robust Query Language: Elasticsearch offers a powerful query language for complex data filtering, aggregation, and organization, accommodating various query types from simple term searches to complex operations.
- Comprehensive Full-Text Analysis: Elasticsearch offers comprehensive text analysis capabilities, including tokenization, stemming, and language support, ensuring accurate and relevant search results for unstructured textual data.
- Scalability and High Availability: Elasticsearch offers high availability, fault tolerance, data dependability, and minimal downtime through its built-in features that can be easily scaled horizontally and vertically.
- RESTful API Accessibility: Elasticsearch’s RESTful API streamlines data indexing, querying, and management tasks through standard HTTP methods, simplifying interactions with the system.
- Document-Centric: Elasticsearch uses a document-centric approach, storing data in JSON documents, simplifying the handling of structured and semi-structured data, and making each document unique and retrievable.
- Extensive Ecosystem Integration: Elasticsearch, part of the Elastic Stack, integrates with Logstash and Kibana for data ingestion, transformation, and visualization, enabling comprehensive data analysis and monitoring.
- Active Community and Support: Elasticsearch, a popular open-source platform, is supported by Elastic, a company that caters to enterprise customers’ needs through commercial options.
3. Define cluster
Ans:
A cluster is a basic idea that denotes a group of one or more Elasticsearch nodes or instances interacting to store data and offer distributed search and analytics capabilities. The distributed architecture of Elasticsearch must include clusters.4. How do clusters function?
Ans:
- Node Discovery: Elasticsearch instances can join existing or initiate new clusters through node discovery, which can be customized through settings like unicast or multicast discovery.
- Data Distribution: Elasticsearch organizes data into indexes and shards, strategically disseminating them across nodes using a hashing algorithm for equitable distribution.
- Master-Node Architecture: Master nodes manage cluster-level activities like index creation and maintenance, while data nodes handle data storage and query execution within the cluster framework.
- Data Replication: Elasticsearch generates replica shards for primary shards, providing fail-safe backups and enhancing query performance. They assign primary and replica shards to distinct nodes for fault tolerance.
- Query Distribution: The cluster distributes a client’s query across multiple nodes, each processing its data and transmitting results to a coordinating node, which aggregates and consolidates the results.
- High Availability: Clusters maintain high availability standards by reallocating impacted shards to other operational nodes when a node fails or becomes unreachable, ensuring data accessibility despite hardware glitches or network interruptions.
- Scalability: Elasticsearch’s dynamic cluster expansion allows for easy data volume expansion or query demands, thanks to its ability to handle horizontal scaling and node addition seamlessly.
- Cluster Health and Monitoring: Elasticsearch provides APIs and tools for monitoring cluster health and performance, enabling users to analyze status, access statistics, and configure notifications for proactive issue resolution.
5. What does ELK stack mean?
Ans:
A group of open-source software programs called the ELK Stack is made for log management, data analytics, and visualization. The abbreviation “ELK” stands for Elasticsearch, Logstash, and Kibana, the three essential parts of the stack.
Every component in the stack has a specific function:
- Elasticsearch: A distributed search and analytics engine that searches and indexes enormous volumes of data using the central component of the ELK Stack.
- Logstash: Data collection pipeline that processes and analyzes data from various sources, including logs, metrics, and event streams, utilizing data enrichment, filtering, and parsing.
- Kibana: Robust data exploration and visualization tool that provides a user-friendly interface for querying and displaying Elasticsearch data, enabling interactive dashboards, charts, graphs, and maps.
6. What benefits does Elasticsearch give you?
Ans:
- Distributed Architecture
- Scalability
- Full-Text Search
- High Performance
- Rich Query Language
- Schema-Free
- Data Replication
- Security Options
7. Describe the ELK stack architecture.
Ans:
The ELK Stack, sometimes referred to as the Elastic Stack, is a powerful combination of three essential parts utilized for log and data analysis, visualization, and administration. Together, these elements build a solid architecture for handling and extracting insights from data.
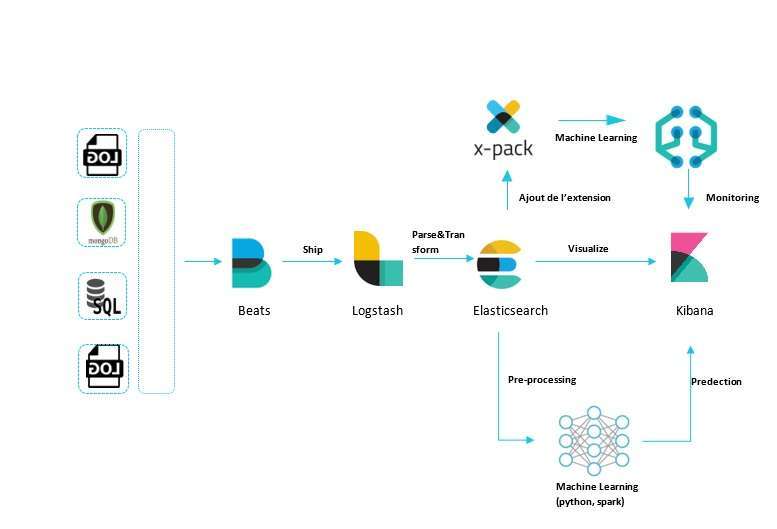
- Elasticsearch: Elasticsearch is a distributed search and analytics engine that indexes and stores data for quick retrieval and analysis.
- Logstash: Logstash is a tool that gathers data from various sources, analyzes it, and then delivers it to Elasticsearch for archival and analysis.
- Kibana: A user-friendly interface is provided by Kibana, a visualization and exploration tool, for querying and displaying data contained in Elasticsearch.
8. What are the main tasks carried out in a document?
Ans:
Elastic search’s main tasks on documents consist of:
- Indexing
- Searching
- Deleting
- Retrieving
- Updating
- Scripting Mapping and Schema Management
9. What does tokenizer mean?
Ans:
An essential part of the text analysis procedure is a tokenizer. It is essential for dividing a text block (a string of characters) into smaller chunks, or “tokens.” The building blocks for full-text search and indexing are tokens, which are often words or keywords that make up the text.
10. What does an Elasticsearch analyzer do?
Ans:
The processing of textual data within Elasticsearch requires the use of an Elasticsearch analyzer, which performs several key tasks. During indexing and querying, an analyst works with the text.
11. What is the procedure for deleting an index in Elasticsearch?
Ans:
-
Using the DELETE Request: You can delete an index with an HTTP DELETE request by specifying the index name in the request URL. Here’s an example using the “curl” command:
curl -X DELETE “http://localhost:9200/your_index_name”
Replace ‘your_index_name’ with the name of the index you want to remove.
-
Using the Elasticsearch REST API: You can utilize a tool or library that provides Elasticsearch client functionality in your preferred programming language, such as Python.
For Example: From elasticsearch import Elasticsearch
- es = Elasticsearch([{‘host’: ‘localhost’, ‘port’: 9200}])
- es.indices.delete(index=’your_index_name’, ignore=[400, 404])
Change ‘your_index_name’ to the name of the index you want to remove.
- Using Kibana: Kibana offers interactive index deletion using Dev Tools or Management UI. Send a DELETE request with the index name, then navigate to “Index Management” in the Management UI.
- Note: Exercise caution when using interactive interfaces like Kibana to delete indexes in a production environment.
-
Using Curator: You can manage Elasticsearch indices using the powerful Curator tool, which allows index deletion based on criteria like age or size and can be automated through actions.
Example Curator action file (‘delete_indices.yml’):
- actions:
- 1:
- action: delete_indices
- description: “Delete old indices”
- options:
- ignore_empty_list: True
- timeout_override:
- continue_if_exception: False
- disable_action: False
- filters:
- – filtertype: pattern
- kind: prefix
- value: your_index_prefix
- – filtertype: age
- source: creation_date
- direction: older
- timestring: ‘%Y.%m.%d’
- unit: days
- unit_count: 30
- exclude:
Run Curator using the action file:
- curator –config curator.yml delete_indices.yml
Change ‘your_index_name’ to the name of the index or pattern you want to remove, and adjust the Curator setup to meet your requirements.
12. Where is Elasticsearch stored?
Ans:
In a distributed cluster, Elasticsearch is typically stored on one or more servers or nodes. The file systems of these nodes are where Elasticsearch’s data and configurations are stored. Elasticsearch’s data and other components are located in the following directories:
- Data Directory
- Logs Directory
- Plugins Directory
- Configuration Directory
- Temporary Files and Indices
13. Which configuration management tools does Elasticsearch support?
Ans:
- Chef
- Ansible
- SaltStack
- Puppet
- Kubernetes
- Terraform
- Docker Compose
14. What is mapping in elastic search?
Ans:
An index’s data structure and how its documents should be stored and indexed are specified by a mapping, which is a schema definition. Elasticsearch makes use of mappings to decide how to index the data, what data types to utilize for fields, and how to tokenize and analyze text fields. A mapping instructs Elasticsearch on how to understand the information in your documents.
15. Define Apache Lucene.
Ans:
The Apache Software Foundation created Apache Lucene, a widely used open-source search library and information retrieval software project. It offers a reliable and effective framework for cataloging and looking up text-based data. Lucene is a Java-based information retrieval system that is intended to be extremely scalable, adaptable, and able to handle a variety of information retrieval jobs.
16. What does Elasticsearch’s NRT (Near Real-Time) mean?
Ans:
The abbreviation “NRT” in Elasticsearch stands for “Near Real-Time.” It refers to Elasticsearch’s ability to provide close-to-real-time search and indexing of data as it’s ingested into the system. This means that, as soon as a document is added, updated, or deleted in Elasticsearch, it usually takes only a few seconds for it to become searchable.
17. What does Elasticsearch’s URI search feature accomplish?
Ans:
With Elasticsearch’s URI (Uniform Resource Identifier) search functionality, you can send HTTP GET requests with search parameters contained directly in the URI. With this functionality, Elasticsearch can be easily accessed using straightforward searches that resemble URLs.
18. List various Elasticsearch Cat API commands available.
Ans:
Here are some of the frequently used functions provided by the Elasticsearch Cat API:
- cat indices
- cat count
- cat shards
- cat nodes
- cat field data
- cat allocation
- cat pending_tasks
- cat recovery
- cat plugins
- cat segments
- cat aliases
19. What is an “ingest node” in Elasticsearch?
Ans:
An ingest node in Elasticsearch is a specialized type of node within a cluster responsible for executing operations on pre-processed and transformed documents before indexing them into Elasticsearch. The Elasticsearch Ingest Node Pipeline, which is part of ingest nodes, allows you to define a series of processors or transformations to apply to incoming documents before they are stored in the index.
20. What query language is used by Elasticsearch?
Ans:
Elasticsearch primarily uses the “Elasticsearch Query DSL” (Domain-Specific Language) as its query language. This query language is specifically designed for interacting with Elasticsearch and conducting various searches and retrievals on the data indexed in Elasticsearch.
Subscribe For Free Demo
21. What are Elasticsearch’s single document APIs?
Ans:
Elasticsearch’s single document APIs allow you to interact with individual documents within an index. These APIs enable you to create, retrieve, update, and delete single documents and perform other actions on individual documents in Elasticsearch. They are useful when you need to work with specific data entries in your Elasticsearch index.
Some of the popular Single Document APIs in Elasticsearch include:
- Get API
- Index API
- Update API
- Delete API
- Source API
- Exists API
- Term Vectors API
22. What are multi-document APIs in Elasticsearch?
Ans:
Elasticsearch’s multi-document APIs enable concurrent operations on multiple documents within indices, reducing overhead and facilitating bulk operations such as mass indexing, updating, removal, and document searching, making them frequently utilized in Elasticsearch operations.
Here are some popular Elasticsearch multi-document APIs:
- Bulk API
- Search API
- Reindex API
- Multi-Get API
- Update By Query API
- Delete By Query API
23. What are Elasticsearch fuzzy queries?
Ans:
An Elasticsearch fuzzy query is a type of query that allows you to search for terms that are similar to a provided term, even if they contain minor typos or spelling errors. Fuzzy queries enable you to retrieve results that may not exactly match the search term but are sufficiently close to be considered relevant. This is particularly useful for accommodating variations in user input and improving search accuracy.
Example:
- {
- “query”: {
- “fuzzy”: {
- “title”: {
- “value”: “apple”,
- “fuzziness”: “2” // Allows for up to 2 edit distance (typo) changes
- }
- }
- }
- }
24. Describe the purpose of Elasticsearch’s replica shards.
Ans:
Elasticsearch’s replica shards serve various purposes, including:
- Read Scalability
- Distributing the load
- Recovery and Failover
- Enhanced Search Results
- Recovery and Failure Handling
- High Availability and Fault Tolerance
25. What syntax should I use to add a mapping to an index?
Ans:
When creating an index in Elasticsearch or modifying an existing mapping, you typically use the Index Mapping API to add a mapping.
Example:
- PUT /my_index # Create the index if it doesn’t exist
- {
- “mappings”: {
- “properties”: {
- “field1”: {
- “type”: “text”,
- “analyzer”: “standard”
- },
- “field2”: {
- “type”: “integer”
- }
- }
- }
- }
26. What distinguishes the terms “Master Node” and “Master-Eligible Node”?
Ans:
| Master Node | Master-Eligible Node | |
|---|---|---|
| 1 | A specified node designated as the master node in an Elasticsearch cluster is in charge of managing the entire cluster and keeping track of its metadata. | A node that is set to be capable of becoming a master node—whether or not it is doing so right now—is said to be master-eligible. |
| 2 | It controls operations like adding and removing indices, keeping track of the cluster’s nodes, and organizing shard allocation and recovery. | Nodes that are master-eligible take part in master election procedures. To maintain cluster management in the event that the current master node fails, one of the master-eligible nodes is chosen as the new master. |
| 3 | When necessary, the master node starts leader elections and manages other cluster state changes, such as adding or removing nodes. | In order to provide fault tolerance, Elasticsearch clusters frequently have multiple master-eligible nodes. This makes it possible for another master-eligible node to take over in the event that the present master node is unavailable. |
| 4 | There is only one active master node at a time in a healthy cluster. To ensure high availability in the event that the current master node fails, more than one node may be identified as master-eligible nodes. | Beyond taking part in master elections, being a master-eligible node does not always entail additional duties. Depending on their setup and roles, master-eligible nodes can also carry out data and query-related operations like non-master nodes. |
27. What does an ElasticSearch filter do?
Ans:
Filters are binary queries that limit document collection based on query criteria, sorting documents according to predetermined standards without altering relevance scores. They exclude or include documents based on provided conditions.
28. Describe the inverted index and the significance it serves in Elasticsearch.
Ans:
An inverted index is a data structure that links terms (words or tokens) to the texts or locations where they exist in a corpus of text data. It flips the conventional data structure, in which terms are linked to documents. Instead, you can easily find out which papers include specific terms by using the inverted index. Its significance in Elasticsearch:
- Scalability
- Reduced Scanning
- Efficient Text Retrieval
- Tokenization and Analysis
- Partial Match and Ranking
- Support for Complex Queries
29. Why would you use the ‘wait_for_completion’ parameter?
Ans:
The ‘wait_for_completion’ parameter is used in various API queries, especially those involving asynchronous processes. It allows you to specify whether the client should wait for a specific operation to complete or receive an immediate response indicating that the operation has been accepted and is in progress. The importance and use cases of the ‘wait_for_completion’ parameter may vary depending on the specific action being performed.
Query:
- POST /my_index/_doc/_bulk
- {
- “wait_for_completion”: true,
- “index”: { “_index”: “my_index”, “_id”: “1” }
- }
30. What does an ElasticSearch shard mean?
Ans:
A shard is a fundamental unit of data storage and distribution. Elasticsearch divides an index into smaller, manageable pieces called shards, which can be distributed across multiple nodes in a cluster. Understanding shards is essential for optimizing the performance, scalability, and reliability of your Elasticsearch cluster.

Learn From Comprehensive Elasticsearch Training By Expert Trainers
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
31. Is there a schema for ElasticSearch?
Ans:
Since Elasticsearch doesn’t impose a strict structure on your data, it is frequently referred to as a “schema-less” or “schema-flexible” database. Instead, it enables you to store and index data without needing to give every document in an index a set, permanent structure. Elasticsearch’s adaptability is one of its main advantages, particularly in situations where data is varied, dynamic, or changes over time.
32. Why is it necessary to install X-Pack for Elasticsearch?
Ans:
X-Pack for Elasticsearch offers various essential features, including:
- Security
- Reporting
- Graph Exploration
- Elasticsearch SQL CLI
- SQL and SQL REST API
- Monitoring and Alerting
- Machine Learning CLI
- Cross-Cluster Search and Replication
33. How does Beats work with Elasticsearch?
Ans:
Elastic Beats are user-friendly data shippers that efficiently gather, process, and send data to Elasticsearch, enabling easier monitoring and analysis of infrastructure, apps, and logs.
34. Describe the process for developing custom Elasticsearch plugins.
Ans:
- Organize the development environment
- New Plugin Project Creation
- Select the Type of Plugin
- Generate the plugin code
- Build Configuration
- Use customized functionality
- Testing
- Packaging
- locally install and test
- Distribution
- Updating and maintaining
35. Can frozen indices be used for write operations?
Ans:
No, Elasticsearch does not allow write operations on frozen indices. Frozen indices are strictly read-only to ensure the durability and integrity of the data stored in frozen indices.
36. What exactly do you mean by cluster health?
Ans:
Cluster health refers to the overall state or status of an Elasticsearch cluster at a specific point in time. It provides essential information about the operational status of the cluster, including the health of individual nodes, the availability of primary and replica shards, and various cluster-level metrics. Monitoring cluster health is a critical aspect of managing an Elasticsearch cluster.
37. Is Elasticsearch compatible with other programs? If so, what are the names of the tools?
Ans:
Elasticsearch is highly flexible and can be integrated with a wide range of additional tools and technologies to enhance its functionality and support various use cases. It can be integrated with various data storage, analysis, visualization, and processing technologies. Some of the tools and services that Elasticsearch is compatible with include Datadog, Contentful, Couchbase, and Amazon Elasticsearch Services.
38. What syntax does Elasticsearch use to fetch a document by ID?
Ans:
To fetch a document by its ID in Elasticsearch, you can use the ‘GET’ request to the ‘_doc’ endpoint and specify the index name and document ID in the URL as follows:
Syntax:
- GET /index_name/_doc/document_id
39. What does the “_source” column in Elasticsearch documents represent?
Ans:
The ‘_source’ field is a unique field having a particular function in documents. It serves as a repository for the original JSON source information that was utilized to index a document. The ‘_source’ field’s main function is to give users a method to get the original data that was indexed without having to download the whole page.
- Versioning
- Partial Updates
- Document Retrieval
- Search and Analysis
- Data Retrieval Efficiency
40. What function does Elasticsearch’s “refresh interval” serve?
Ans:
The “refresh interval” setting in Elasticsearch regulates how frequently updates to an index are made visible and searchable in the index. In an Elasticsearch cluster, it influences the harmony between indexing speed and search performance.
41. Explain the concept of nested aggregations in Elasticsearch.
Ans:
Elasticsearch’s nested aggregations allow you to execute aggregations within nested documents or object arrays. You can use nested aggregations to evaluate and condense data at various levels of nesting when you have nested data structures, such as a list of comments within a blog article. This preserves the hierarchical structure of your documents while enabling you to get insightful information. For situations like nested comments, products with several qualities, or hierarchical data modeling, nested aggregations are helpful. They give you fine-grained control over your data analysis by allowing you to independently aggregate, filter, and compute statistics on nested documents.
42. How do Elasticsearch date histogram aggregations work?
Ans:
To organize and examine data over time periods, you can use date histogram aggregations. For the examination of time series data, such as log data, sales records, and sensor readings, date histogram aggregations are very helpful. To aggregate date histograms, follow these steps:
- Define the Aggregation: Include a date histogram aggregation in the aggregations portion of your Elasticsearch query. Here’s a simplified illustration:
- {
- “aggs”: {
- “my_date_histogram”: {
- “date_histogram”: {
- “field”: “timestamp_field”,
- “interval”: “day”
- }
- }
- }
- }
- ‘My_date_histogram’ is a name that the user has given the aggregation.
- ‘Timestamp_field’ the name of the field holding the date or timestamp you wish to aggregate should be used in its stead.
- ‘Interval’ includes terms like “day,” “hour,” “month,” etc. that specify the time period for grouping data.
- Execute the Query: For the purpose of aggregating the date histogram, send this query to Elasticsearch. The results of the aggregate will be returned by elasticsearch in a response.
- Analyze the Results: Each time interval’s bucket and its corresponding aggregated data will be included in the response, as well. For additional analysis or visualization, you can access these results in your application.
Example:
- {
- “aggregations”: {
- “my_date_histogram”: {
- “buckets”: [
- {
- “key_as_string”: “2023-10-01T00:00:00.000Z”,
- “key”: 1664524800000,
- “doc_count”: 5
- },
- {
- “key_as_string”: “2023-10-02T00:00:00.000Z”,
- “key”: 1664611200000,
- “doc_count”: 8
- }
- // More buckets for other intervals
- ]
- }
- }
- }
43. Describe the Elasticsearch notion of dynamic mapping.
Ans:
When documents are indexed by Elasticsearch, a feature called dynamic mapping automatically recognizes and determines the data types of fields within those documents without the need for explicit schema or mapping definitions. It makes it simple to index documents with different field types and enables Elasticsearch to adapt to changing data architectures.
44. Define pipelines in Elasticsearch.
Ans:
As documents are being ingested into the index, Elasticsearch’s pipelines feature, which was first introduced in version 5.0 and later releases, allows you to conduct data transformations and enrichments on the documents. Before data is indexed, pipelines are mostly used to preprocess and change it, making it more suited for search and analysis.
45. How can you create management policies for indices using ILM?
Ans:
Elasticsearch’s Index Lifecycle Management (ILM) feature enables you to specify rules for controlling the lifespan of your indices. You may automate procedures like index rollover, retention, and data migration with ILM policies based on predetermined criteria.
The following describes how to define indices management policies using ILM:
- Define an ILM Policy
- The Policy Should Be Attached to an Index Template
- Use the specified template to create an index.
- Index Management
46. What are the ILM’s recommended essential phases for the index lifecycle?
Ans:
- Hot Phase: During the “hot” phase, indexes receive new data, actively written to and queried. Prerequisites like age or index size can be specified for exiting the hot phase.
- Warm Phase: Indexes transition from “hot” to “warm” phase, allowing performance optimization for queries. Prerequisites for warm phase entry include index age or size.
- Cold Phase: The “cold” phase is used for indices no longer frequently queried, allowing them to be stored more efficiently and shifted to slower, more affordable options.
- Frozen Phase: Elasticsearch’s “frozen” phase is an optional stage for compliance or long-term archiving, storing frozen indices that cannot be searched, and conditions for entering this phase can be specified.
- Delete Phase: The “delete” step in Elasticsearch removes indices based on predetermined standards, such as age or older version quantity, to save space in the cluster.
47. How is Elasticsearch’s role-based access control (RBAC) configured?
Ans:
- Activate Security Features: Ensure that Elasticsearch’s security features are activated by applying the relevant license (e.g., the default “Basic” license).
- Establish Authentication: Configure authentication methods, such as native authentication, LDAP, or Single Sign-On (SSO), to validate user identities.
- Define User Roles: Craft customized roles that delineate permissions for specific users or groups, with control extending to actions at the cluster, index, or document levels.
- Allocate Access Rights: Link privileges to roles, specifying the actions that users possessing those roles are permitted to undertake. Privileges span activities such as reading, writing, and administrative tasks.
- Create User Accounts and Role Assignments: Generate user profiles and assign them to predefined roles. Users inherit the permissions ascribed to the roles they are associated with.
- Configure Role Mapping: Set up role mapping to connect external groups (e.g., LDAP groups) with Elasticsearch roles, streamlining the management of users and their access.
- Secure Elasticsearch API Entry Points: Lock down entry points to Elasticsearch’s API by enforcing stringent authentication and authorization measures. Tailor roles for RESTful APIs as required.
- Conduct Testing and Monitoring: Rigorously evaluate the RBAC configuration to ensure that users possess the requisite permissions. Continuously monitor Elasticsearch logs and security events for potential issues.
48. Define X-Pack.
Ans:
X-Pack, an expansion module for Elasticsearch, Kibana, Logstash, and Beats, was developed by Elastic to enhance the security, monitoring, alerting, and management features of Elasticsearch and Elastic Stack.
49. What guidelines should be followed when designing an Elasticsearch index?
Ans:
- Shard Count and Size Selection: Ensure optimal performance and resource utilization by aiming for a shard size ranging from several gigabytes to tens of gigabytes, considering data volume and query patterns.
- Mapping Type Considerations: Starting version 7.0, Elasticsearch no longer supports multiple mapping types within an index, recommending single mapping types or separate indexes for each document type.
- Mapping Optimization Strategies: Select appropriate data types for mapping, customize analyzers for text fields, and use date fields for timestamp data to enhance queries based on time.
- Analysis Strategies for Indexing and Querying: A balanced approach between index-time and query-time analysis is recommended, incorporating “text” and “keyword” subfields for text fields to optimize full-text and exact match queries.
- Effective Index Lifecycle Policy: Implement Index Lifecycle Management (ILM) policies to automate data retention, rollovers, and migration, enhancing efficiency and simplifying index management tasks.
- Scaling and High Availability Planning: Consider horizontal scaling options like adding more nodes to your Elasticsearch cluster or using index aliases for data distribution, and configure replica shards for high availability and fault resilience.
- Continuous Monitoring and Optimization: Utilize Elasticsearch’s built-in monitoring features to continuously monitor your index and cluster, optimize query and aggregation performance, and consider query caching for improved search efficiency.
50. Describe the significance of performance tuning and monitoring in Elasticsearch clusters.
Ans:
- Ensures Cluster Reliability and Health
- Finds Performance Bottlenecks
- the avoidance of downtime and data loss
- Query and Indexing Performance is improved.
- efficient use of resources
- Planning for capacity and scalability
- Improves Compliance and Security
- Offers Guidance for Troubleshooting
- Encourages Effective Data Management
- Cost reduction
51. What is caching in Elasticsearch?
Ans:
Elasticsearch caching is a technique for storing and retrieving frequently accessed data, which enhances query performance and lessens the strain on the CPU and underlying storage. Elasticsearch’s architecture is fundamentally based on caching, which facilitates faster search and retrieval processes.
52. What does elasticsearch’s Logstash mean?
Ans:
For data intake, transformation, and forwarding, Logstash, a separate component of the Elastic Stack (formerly known as the ELK Stack), is frequently used in conjunction with Elasticsearch. Before being indexed into Elasticsearch for search, analysis, and visualization, data from many sources can be processed and enhanced using Logstash.
53. how does Logstash integrate with Elasticsearch?
Ans:
- Logstash Configuration
- Input Plugins
- Filter Plugins
- Elasticsearch Output Plugin
- Output Configuration
- Data Indexing
- Indexing Strategy
- Monitoring and Management
- Scalability and High Availability
- Security Integration
54. How does Elasticsearch manage document versioning?
Ans:
- Automated Document Versioning
- Optimistic Concurrency Management
- Initial Document Indexing
- Document Updates
- Resolution of Conflicts
- Preservation of Historical Document States
- Deactivating Versioning Support
55. What function does machine learning play in Elasticsearch?
Ans:
- Predictive Analysis
- Anomaly Detection
- Root Cause Analysis
- Automated Data Management
- Automated Alerts
- Improved Search Relevance
- Behavior Analysis

Join Best Elasticsearch Course with Global Recognised Certification
Weekday / Weekend BatchesSee Batch Details56. How are geolocation and geometry data fields handled by Elasticsearch?
Ans:
- Indexing Geospatial Data
- Geographical Inquiries
- Sorting by Distance
- Geo Aggregations
- GeoJSON Support
57. What filters does Elasticsearch have?
Ans:
- Term Filter
- Exists Filter
- Range Filter
- Bool Filter
- Geo Filters
- Script Filter
- Prefix Filter
- Wildcard Filter
58. What syntax does Elasticsearch use to retrieve a document by ID?
Ans:
Syntax:
- GET /index_name/_doc/document_id
59. How do Term-based and Full-text queries differ from one another?
Ans:
- Term-Based Queries: Term-based queries match words exactly, searching for papers with the requested terms. They don’t undergo text analysis and work with raw terms in an inverted index. They’re useful for high precision but lesser recall.
Examples: This includes term queries, term range queries, prefix queries, wildcard queries, and others.
- Full-Text Queries: Full-text queries are used for searching text-based data, analyzing both the search query and indexed data. They handle language-specific tasks like stemming, removing stop words, and tokenizing input text. They are suitable for information retrieval and natural language search for higher recall.
60. How does Elasticsearch search across several fields?
Ans:
Multi-Match Query:
- {
- “query”: {
- “multi_match”: {
- “query”: “search term”,
- “fields”: [“field1”, “field2”, “field3”]
- }
- }
- }
Bool Query with Should Clauses:
- {
- “query”: {
- “bool”: {
- “should”: [
- { “match”: { “field1”: “search term” }},
- { “match”: { “field2”: “search term” }},
- { “match”: { “field3”: “search term” }}
- ]
- }
- }
- }
Query String Query:
- {
- “query”: {
- “query_string”: {
- “query”: “field1:search term OR field2:search term OR field3:search term”
- }
- }
- }
61. What distinguishes Amazon DynamoDB from Elasticsearch?
Ans:
- Elasticsearch: Elasticsearch is a robust indexing and search tool used in search engines, e-commerce platforms, and log management systems for full-text search, analytics, and log analysis, enabling fuzzy matching, proximity searches, and relevance scoring.
- Amazon DynamoDB: DynamoDB is a managed NoSQL database service designed for high-quality, scalable performance, suitable for low-latency data access applications like IoT, gaming, and online apps. It offers fundamental query capabilities, but not for sophisticated search operations like Elasticsearch.
62. Differentiate between a primary shard and a replica shard
Ans:
| Effect | Primary Shard | Replica Shard |
| Responsibility | Elasticsearch divides each index into one or more primary shards. The main copy of the data for that index is stored in the primary shard. | Replica shards are extra copies of the data in the parent shard. They act as backups and enable horizontal read operation scaling. |
| Write Operations | Every write activity, including document updating and indexing, is initially focused on the primary shard. This guarantees that the data is present in a single, authoritative copy. | Write operations do not include replica shards. Only the primary shard will receive write operations. Read-only copies are replicas. |
| Availability | Each major shard is hosted on a distinct node in the cluster thanks to elasticsearch. With this distribution, fault tolerance is improved because if one node fails, another can step in to host the primary shard. |
To provide high availability, Elasticsearch automatically distributes replica shards among many nodes. In the event of node failures, this distribution enables for redundancy and failover. |
| Number of Shards | An index’s primary shard count is predetermined at index creation and never changes. If there is already an index, it cannot be altered. |
After an index is created, the replica shard count can be customized and altered. Per primary shard, Elasticsearch lets you have 0 or more replica shards. |
63. What fundamental X-Pack commands are there?
Ans:
64 Demonstrate Elasticsearch API.
Ans:
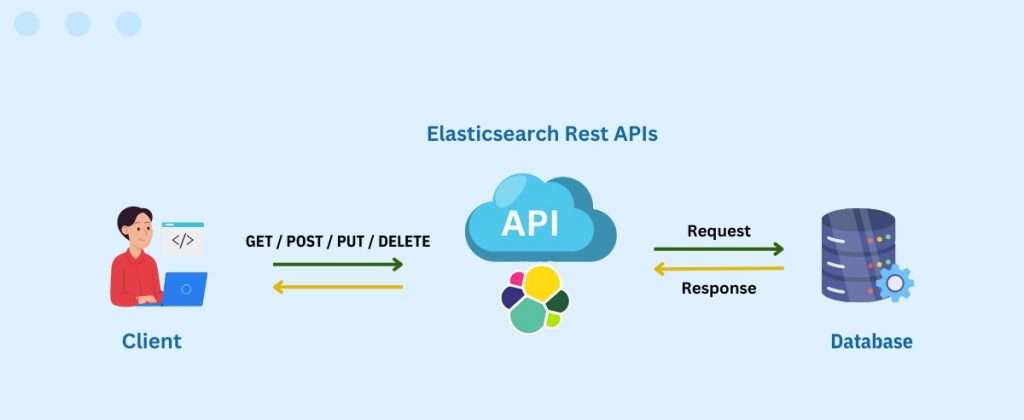
WYou can communicate with Elasticsearch, a distributed, open-source search and analytics engine, using a collection of HTTP endpoints and RESTful web services known as the Elasticsearch API. You may manage data stored in Elasticsearch clusters by indexing, searching, updating, and performing a variety of other activities using the Elasticsearch API.ith Elasticsearch’s URI (Uniform Resource Identifier) search functionality, you can send HTTP GET requests with search parameters contained directly in the URI. With this functionality, Elasticsearch can be easily accessed using straightforward searches that resemble URLs.
65. What does Elasticsearch’s graph explore API do?
Ans:
- Graph Exploration
- Discovering Hidden Patterns
- Graph Visualization
- Anomaly Detection
- Related Documents
- Influence and Impact Analysis
66. What is a Data Node in Elasticsearch?
Ans:
An essential part of an Elasticsearch cluster is an Elasticsearch Data Node, sometimes known as a “data node” or simply “data node.” It is essential for handling and storing the real data included in Elasticsearch indexes.
67. What is Elasticsearch’s most recent version?
Ans:
Elasticsearch 7.15 was the most recent version that was considered stable. Elasticsearch is still actively being developed, and new versions with bug fixes, enhancements, and new features are constantly published. I advise consulting the Elasticsearch GitHub repository or the official Elasticsearch website to find the most recent information about the most recent version of Elasticsearch. There may have been additional versions released after my previous update because Elasticsearch’s versioning structure normally follows a pattern like 7.x, with the x being the minor version.
68. What is the “Bucket Selector Aggregation,” and why is it helpful in the study of time series data?
Ans:
Bucket Selector Aggregation is a lesser-known Elasticsearch feature used to aggregate, filter, and compute metrics on data, often used alongside queries to examine and compile data stored in Elasticsearch indices.
- Date Histogram Aggregation: This type of aggregation is commonly employed to create data histograms or group data into intervals based on date or time. It aids in visualizing data trends over time, detecting patterns, and conducting time-oriented analysis.
- Moving Average Aggregation: This aggregation computes the moving average of a time series, serving the purpose of smoothing data and revealing longer-term patterns.
- Sum, Minimum, Maximum, and Average Aggregations: These aggregation methods enable you to calculate diverse metrics, such as the total, lowest, highest, and mean values of numerical fields within a specified time frame.
- Filter Aggregation: The filter aggregation permits you to refine your analysis by applying filters to the data prior to performing other aggregation operations. This allows you to focus on specific subsets of your data for more targeted analysis.
69. Can you give an example of a real-world use case where Time Series Data analysis was done using Elasticsearch?
Ans:
Utilizing Elasticsearch for IT Operations Log and Event Analysis: A highly common application of Elasticsearch in the realm of time series data analysis pertains to IT operations and the management of logs. Within organizations, a substantial volume of log data is routinely generated by servers, applications, network devices, and various infrastructure elements. Elasticsearch offers an efficient means of storing and indexing this data, simplifying the process of scrutinizing and overseeing the operational well-being and performance of IT systems as time progresses.
70. How is Time Series Data handled by Elasticsearch? Describe the idea of Indices and Timestamps.
Ans:
Elasticsearch effectively indexes, queries, and analyzes time series data using timestamps and indices, making it a powerful search and analytics engine.
Timestamps:
- Significance: Timestamps play a pivotal role in Elasticsearch’s management of time series data. They denote the precise date and time when an event or data point was recorded.
- Data Ingestion: When time series data is imported into Elasticsearch, each data point is linked with a timestamp. This timestamp typically resides within the data itself, serving as the basis for chronological organization within Elasticsearch.
- Chronological Sorting: Elasticsearch takes charge of sorting data by timestamps automatically. This ensures that the most recent data takes precedence in search results.
Indices:
- Importance: Within Elasticsearch, data is structured into what are known as indices. An index is a collection of documents that share a similar data schema and are stored collectively. In the context of time series data, it is customary to create indices based on defined time intervals, such as daily, weekly, or monthly.
- Index Naming Conventions: A common practice involves naming these indices in accordance with a pattern that incorporates a date or timestamp. For instance, you might establish indices with names like “log-2023-10-01” to represent data recorded on October 1, 2023.
- Data Retention: Time series data frequently adheres to a finite retention period. Consequently, older indices can be removed or archived once they are no longer needed, thereby liberating storage resources.
- Index Sharding: Elasticsearch offers the capability to partition an index into multiple shards, allowing for parallel processing and scalability. This feature proves particularly advantageous when dealing with substantial volumes of time series data.
- Querying: Elasticsearch facilitates the querying of data spanning multiple indices. It does so efficiently by extracting pertinent data from the relevant indices based on the timestamps specified within the query.
71. What part do Elasticsearch queries and aggregations play in SIEM for spotting trends and security threats?
Ans:
For the purpose of discovering security threats and patterns, Elasticsearch queries and aggregations are essential components of Security Information and Event Management (SIEM) systems. SIEM systems are made to gather, examine, and correlate information from numerous sources in order to spot and address security events. Elasticsearch is frequently utilized as the backend for SIEM solutions because of its querying and aggregation capabilities.
Here is how Elasticsearch aggregations and searches help SIEM:
- Log Data Retrieval
- Real-Time Alerting
- Correlation Analysis
- Anomaly Detection
- Historical Analysis
72. Explain the concept of threat detection and incident response using Elasticsearch in a SIEM context.
Ans:
Threat Detection using Elasticsearch:
- Data Ingestion
- Real-Time Monitoring
- Correlation and Anomaly Detection
- Search and Investigation
Incident Response using Elasticsearch:
- Alert Triage:
- Timeline Analysis
- Threat Hunting
- Forensics and Investigation
- Reporting and Documentation
73. Why are anomaly detection and machine learning used in SIEM, and how is Elasticsearch used to enable these features?
Ans:
Security Information and Event Management (SIEM) systems have useful features like machine learning and anomaly detection that can improve an organization’s cybersecurity efforts. In order to provide strong support for machine learning-based anomaly detection in a SIEM setting, Elasticsearch can be combined with these capabilities.
Purpose of Machine Learning and Anomaly Detection in SIEM:
Machine learning and anomaly detection in SIEM aid in early threat detection by analyzing extensive security data, reducing false positives, promoting adaptive security, and aiding in advanced threat detection by detecting complex attack patterns and multifaceted attacks, particularly for sophisticated cyber threats.
Elastic search’s Support for Machine Learning and Anomaly Detection:
Elasticsearch’s ML plugin offers integrated machine learning capabilities for data preprocessing, model training, and anomaly detection. It efficiently stores large security data and integrates with various sources. Users can create custom jobs for analysis, and it integrates with Kibana for real-time anomaly detection. Its compatibility with SIEM solutions simplifies anomaly detection.
74. Define sorting in Elasticsearch
Ans:
In Elasticsearch, sorting refers to the process of arranging search results in a specific order based on one or more criteria. When you perform a search query, Elasticsearch retrieves a set of documents that match the query conditions. Sorting allows you to control the order in which these documents are presented in the search results.
75. In how many ways can Elasticsearch search results be sorted?
Ans:
- Ascending or Descending Order
- Single Field Sorting
- Multi-Field Sorting
- Custom Sorting
76. Describe pagination.
Ans:
Web applications frequently utilize pagination to deliver big data sets or search results in a user-friendly and manageable way. It entails segmenting a huge dataset into manageable, distinct pages or subsets so that people can browse the material one page at a time. When working with lengthy lists, search results, or database queries, pagination is quite helpful.
77. Explain how pagination works
Ans:
- Active Page
- Total Pages
- User Control
- Navigation Controls
- Division into Pages
- Limiting Data Transfer
78. What mapping type does an index’s default for documents use?
Ans:
Documents within an index use “_doc” as their default mapping type as of Elasticsearch 7.0 and newer versions. This indicates that Elasticsearch will assume “_doc” as the default mapping type for indexing documents if no mapping type is explicitly specified.
79. What are mapping types in Elasticsearch?
Ans:
Elasticsearch uses the term “mapping types” to describe how an index’s documents are ordered. Prior to version 7.0 of Elasticsearch, an index might include different mapping types, each with their own schema or structure. A different document type with unique fields and characteristics was represented by each mapping type.
80. How were mapping types used in earlier versions of Elasticsearch?
Ans:
- Schema Definition
- Different Document Types
- Querying by Type
- Dynamic Mapping
81. Why are mappings defined in Elasticsearch?
Ans:
Elasticsearch defines mappings for a variety of reasons, and these objectives are critical to how Elasticsearch indexes and queries data. Fields in your documents have a defined structure and set of properties thanks to mappings.
82. What are the goals of mapping definitions?
Ans:
- Define Data Structure
- Data Validation
- Ensure Data Consistency
- Dynamic Mapping Control
- Text Analysis Configuration
- Indexing Control
- Relevance Scoring
- Data Modeling
- Aggregation and Filtering
83. What makes the PUT and POST methods better for indexing documents in elastic search?
Ans:
PUT Method:
- The PUT method serves the purpose of either creating a new document or updating an existing one, and it operates based on a specific document ID. When employing the PUT method, it’s essential to explicitly include the document’s ID within the request URL.
- If a document with the designated ID already exists, it will be modified to incorporate the fresh content supplied in the request.
- Conversely, if the document is absent and PUT is used for indexing, Elasticsearch will generate the document using the provided ID.
Example:
- PUT /myindex/mytype/1
- {
- “field1”: “value1”,
- “field2”: “value2”
- }
POST Method:
The POST method is employed to index a document without the need to specify a document ID; instead, Elasticsearch autonomously generates a distinct ID for the document upon using the POST method.
When you submit multiple requests via the POST method without explicitly specifying an ID, Elasticsearch generates a fresh, unique ID for each document. This feature proves beneficial if you prefer Elasticsearch to take charge of managing document IDs for you.
Example:
- POST /myindex/mytype/
- {
- “field1”: “value1”,
- “field2”: “value2”
- }
84. Why is TLS crucial for Elasticsearch, and what does it mean?
Ans:
The cryptographic protocol used to protect data in transit is called TLS(Transport layer security). Protecting sensitive information while communicating between nodes and clients is essential in Elasticsearch.
85. How do you make Elasticsearch support TLS?
Ans:
- Certificate Generation: Generate X.509 certificates for both Elasticsearch nodes and clients, which should include a self-signed CA certificate.
- Elasticsearch Configuration: Modify the ‘elasticsearch.yml’ configuration file to define the file paths for node and CA certificates, alongside other essential TLS configurations.
- Keystore and Truststore Creation: Utilize the elasticsearch-certutil utility to establish keystore and truststore files for the nodes, preserving private keys and trusted CA certificates.
- Node Setting Adjustment: Modify the settings of Elasticsearch nodes to enable TLS encryption for both node-to-node and client-to-node communications. Specify the locations of the keystore and truststore.
- Elasticsearch Restart: Restart Elasticsearch nodes to put the TLS settings into effect. This process secures data transmissions between nodes and clients, implementing encryption and authentication mechanisms.
86. What problems are frequently encountered when configuring TLS for Elasticsearch, and how may they be resolved?
Ans:
- Management of Certificates
- Compatibility of Cipher Suites
- Handling Certificate Revocation
- Compatibility in Mixed Clusters
- Impact on Performance
- Compatibility with Clients and Applications
- Security of Key and Trust Stores
- Authentication of Clients
- Monitoring and Audit Trails
- Documentation and Training
87. What effect does TLS activation have on Elasticsearch performance?
Ans:
- Network Overhead
- Encryption Overhead
- Resource Utilization
- Latency
- Connection Handshakes
- I/O Operations
88. What function does a secure client serve within Elasticsearch?
Ans:
In order to make safe and authenticated connections with the Elasticsearch cluster, a secure client is essential. During the TLS handshake, it presents a legitimate X.509 certificate to demonstrate its identity and securely encrypts communication. This helps to maintain the security and integrity of data sent to and from the Elasticsearch cluster by ensuring that client-to-node communications are shielded from prying eyes and unwanted access.
89. What does the ‘Elasticsearch PKI Realm function in the security plugin do?
Ans:
A crucial element of the Elasticsearch security plugin, the “Elasticsearch PKI Realm” enables users to authenticate via certificates. It enables Elasticsearch to validate the X.509 certificates offered during the TLS handshake, allowing it to confirm the legitimacy of users. This realm is a significant feature for authentication and access control in safe Elasticsearch deployments as it plays a critical role in strengthening security by ensuring that only users with valid certificates are permitted access to the Elasticsearch cluster.
90. How do you manage node authentication and authorization for Elasticsearch in a multi-node cluster with TLS?
Ans:
The management of node authentication and authorisation in a multi-node Elasticsearch cluster using TLS involves configuring X.509 certificates for every node, which are verified during the TLS handshake. Authorized nodes are specified by security settings in the Elasticsearch configuration, and access levels are enforced by roles and privileges assigned to nodes. The security of the Elasticsearch environment is strengthened by this use of certificate-based authentication and role-based authorisation, which guarantees that only trusted nodes can participate.
91. Explain keystore.
Ans:
Cryptographic keys, digital certificates, and other sensitive security data are kept in a keystore, a secure data repository. It is utilized in secure communications, authentication, and encryption. In order to store private keys and certificates for secure communication, keystores are crucial for TLS and SSL. They are essential for creating secure connections, authenticating users or servers, and guaranteeing data integrity and confidentiality. They can be password-protected to prevent unauthorized access. Keystores are implemented by many programs and platforms, such as Java Keystore (JKS) for Java applications, to ensure the privacy and security of digital communications.
92. Define truststore.
Ans:
A truststore is a repository where X.509 certificates that are trusted for authentication and trust in secure communications are kept. Verifying the validity of certificates given by distant servers or entities is essential for TLS and SSL protocols. Clients contact Truststores to confirm that the certificate is valid, has not expired, and was signed by a reputable Certificate Authority (CA). They establish a network of trust, validate the identity of remote parties, enable secure connections, and guard against man-in-the-middle attacks. To guarantee data secrecy and integrity while in transit, truststores are frequently employed in secure network protocols.
93. How does a Certificate Authority (CA) function in TLS for Elasticsearch?
Ans:
A Certificate Authority (CA) is a pivotal entity in TLS for Elasticsearch, responsible for issuing digital certificates and ensuring secure communication. During TLS setup, the CA generates X.509 certificates, distinguishing between nodes and clients. In TLS handshakes, Elasticsearch nodes validate their identities via certificates. The client-side CA certificate authenticates the server’s certificate, establishing trust and deterring unauthorized access. The CA also manages certificate revocation, maintains validity, and builds a trust hierarchy for secure connections. This trust anchor forms the foundation for safeguarding data in transit within Elasticsearch.
94. How are self-signed certificates for Elasticsearch generated?
Ans:
Self-signed certificates for Elasticsearch are created using the ‘elasticsearch-certutil’ tool. First, set up a certificate authority (CA) and generate a CA certificate with ‘elasticsearch-certutil ca’. Then, produce node certificates for each Elasticsearch node using ‘elasticsearch-certutil cert’, specifying the node’s name and the CA certificate. Ensure the certificates include the node’s Common Name (CN) and Subject Alternative Name (SAN) with the hostname or IP. After generating certificates, place them in designated directories as per Elasticsearch’s configuration. Lastly, configure Elasticsearch to use these certificates, restart the nodes, and enable TLS with self-signed certificates, bolstering Elasticsearch communication security.
95. What exactly is the Elasticsearch Bulk API used for, and what is its main objective? please respond to me in a single paragraph.
Ans:
Elasticsearch Bulk API enhances indexing performance by allowing batch processing of multiple actions in a single request. This reduces network overhead and improves efficiency by reducing delays in individual operations. It’s particularly useful for bulk data imports, log ingestion, and fast, large-scale data indexing in situations requiring fast, large-scale data indexing.