
Last updated on 08th Jul 2020| 5900
Hive is a data warehousing infrastructure based on Apache Hadoop. Hadoop provides massive scale out and fault tolerance capabilities for data storage and processing on commodity hardware. Hive is designed to enable easy data summation, ad-hoc querying and analysis of large volumes of data. It provides SQL which enables users to do ad-hoc querying, summarization and data analysis easily. At the same time, Hive’s SQL gives users multiple places to integrate their own functionality to do custom analysis, such as User Defined Functions (UDFs).
Hive cheat sheet
Apache Hive: It is a data warehouse infrastructure based on Hadoop framework which is perfectly suitable for data summarization, analysis and querying. User defined aggregate functions: A user defined function that takes multiple rows or columns and returns the aggregation of the data.
Hive Options :
- Set execution engine : set hive.execution.engine=mr/spark/tez;
- Set queuename : set mapreduce.job.queuename=default;
Hive Optimizations :
Vectorized execution :
- hive.vectorized.execution.enabled
- https://cwiki.apache.org/confluence/display/Hive/Vectorized+Query+Execution
Map Joins :
- hive.auto.convert.join;
- https://cwiki.apache.org/confluence/display/Hive/Vectorized+Query+Execution
Hive Queries :
Deduplicate lines :
- select <needed fields>
from
- select *, row_number() over (partition by id order by tech_timestampchargement desc) as rank
- from [database.table]
- where rank = 1 //
to keep only the first occurence.
Hive Procedures :
Tranfert data between clusters : If it’s an external table, you just need to execute a “show create table” from the source cluster and execute it on the new cluster. You just need to copy paste the content of the table folder from a ccuster to the other in the path specified in the create statement.
Hive Function Meta Commands
- SHOW FUNCTIONS : lists Hive functions and operators
- DESCRIBE FUNCTION [function name] : displays short description of the function
- DESCRIBE FUNCTION EXTENDED [function name]: access extended description of the function
Types Of Hive Functions :
- UDF : is a function that takes one or more columns from a row as argument and returns a single value or object. Eg: concat(col1, col2)
- UDTF : takes zero or more inputs and and produces multiple columns or rows of output. Eg: explode()
- Macros : a function that users other Hive functions.
How To Develop UDFs
- package org.apache.hadoop.hive.contrib.udf.example; import java.util.Date;
- import java.text.SimpleDateFormat;
- import org.apache.hadoop.hive.ql.exec.UDF;
- @Description(name = “YourUDFName”,
- value = “_FUNC_(InputDataType) – using the input datatype X argument, “+
- “returns YYY.”,
- extended = “Example:\n”
- + ” > SELECT _FUNC_(InputDataType) FROM tablename;”)
- public class YourUDFName extends UDF{
- ..
- public YourUDFName( InputDataType InputValue ){
- ..;
- }
- public String evaluate( InputDataType InputValue ){
- ..;
- }
- }
How To Develop UDFs, GenericUDFs, UDAFs, And UDTFs
- public class YourUDFName extends UDF{
- public class YourGenericUDFName extends GenericUDF {..}
- public class YourGenericUDAFName extends AbstractGenericUDAFResolver {..}
- public class YourGenericUDTFName extends GenericUDTF {..}semicolon to terminate statemets
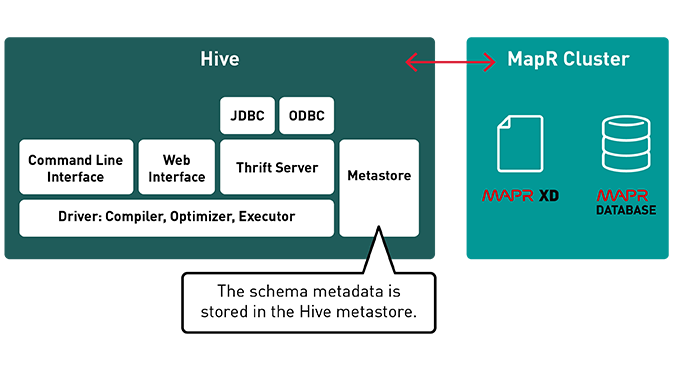
Hive syntax cheat sheet :
- Interchangeable constructs.
- Hive is case sensitive.
- Semicolon to terminate statements.
- Hive data types.
- Primitive Data Types.
- Numeric
- TINYINT, SMALLINT, INT, BIGINT
- FLOAT
- DOUBLE
- DECIMAL
- Date/Time

Get Best Hive Training & Certification Course from Expert Trainers
Weekday / Weekend BatchesSee Batch DetailsTIMESTAMP :
- Strings must be in format “YYYY-MM-DD HH:MM:SS.fffffffff”
- Integer types as UNIX timestamp in seconds from UNIX epoch (1-JAN-1970 00:00:00)
Floating point types same as Integer with decimal precision.
- DATE
String Data Types :
- STRING
- VARCHAR
- CHAR
- Misc.
- BOOLEAN
- BINARY : BINARY is an array of Bytes and similar to VARBINARY in many RDBMSs. BINARY columns are stored within the record, not separately like BLOBs . We can include arbitrary bytes in BINARY column and these bytes are not parsed by Hive as numbers or strings.
Basic Syntax :
Database
Create database :
- CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
- [COMMENT some_comment]
- [LOCATION hdfs_path]
- [WITH DBPROPERTIES(property_name=property_value, …)];
Use database
- USE db_name;
Drop database
- DROP (DATABASE|SCHEMA) [IF EXISTS] database_name;
Show database
- SHOW DATABASES;
Table
Create table
- CREATE [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
- [(col_name data type [COMMENT col_comment], …)]
- [PARTITIONED BY (col_name data type [COMMENT col_comment], …)]
- [ROW FORMATTED row_format]
- [STORED AS file_format]
- [LOCATION hdfs_path]
- [TBLPROPERTIES (property_name=property_value, …)];
External Example 1:
- CREATE EXTERNAL TABLE users (
- user_id INT,
- age INT,
- gender STRING,
- occupation STRING,
- zip_code STRING
- )
- ROW FORMAT DELIMITED
- FIELDS TERMINATED BY ‘|’
- STORED AS TEXTFILE
- LOCATION ‘/pluralsight/userinfo’
- ;
==> For external table, you still can directly insert data into it via “INSERT INTO TABLE …” syntax. This is same as managed table: You can use “INSERT INTO TABLE …” to insert data to __both__ managed table and external table
Create table **AS** Example 1:
- CREATE TABLE
- occupation_count STORED AS RCFile
- AS
- SELECT
- COUNT(*), occupation
- FROM users
- GROUP BY
- occupation;
==> new table will have data
Create table **LIKE** Example 1:
Create table:
- occupation2
- LIKE occupation_count;
==> It will create a new table with no records (empty)
==> It is similar to Oracle “CREATE TABLE y AS SELECT * FROM y WHERE 1=0”
Truncate table : There is no “IF NOT EXISTS” as part of truncate syntax
- TRUNCATE TABLE table_name [PARTITION partition_spec];
Drop table :
- DROP TABLE IF EXISTS [db_name.]table_name;
Show table in hive database
- SHOW TABLES [IN database_name] [‘identifier_with_wildcards’];
Example:
SHOW TABLES “*example*”;
Describe table
- DESCRIBE [EXTENDED|FORMATTED] [db_name.]table_name;
Show table DDL script
- SHOW CREATE TABLE [db_name.]table_name;
Show execution plan for Hive query
- EXPLAIN query;
Load data into table :
- LOAD PATH INPATH [path]
- Move data if source is HDFS
- Copies data if source is LOCAL
- LOAD DATA LOCAL INPATH [path]

Start the hive shell :
hive
Create schema in hive :
hive> create schema hiveschema location ‘/hivedatabase/’;

Learn Best Hive Training to Get Most In-Demand IT Skills
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
Create table with location
- use hiveschema;
- create external table employee(emp_id int,emp_name string,emp_phone string)
- row format delimited
- fields terminated by ‘\t’ location ‘/hivedatabase/employee’;
Create External table in hive
Note:
- The difference between external and internal table is that.
- Drop table for internal table drops the table and metadata.
- Drop table for external table only drops the metadata and data is not touched.
External table : When there is data already in HDFS, an external Hive table can be created to describe the data.It is called External (Data is in the external table and is specified in the Location properties instead of the default warehouse directory.
- Table name would be created as directory
- Schema would be created as meta store
Create external table
- create table product_ratings(UserId string, ISBN string)
- partitioned by (ProductRating int)
- row format delimited
- fields terminated by ‘\t’;
Load data from HDFS
- load data inpath ‘/Locations/Products_Ratings.cvs’
- into table
- product_ratings partition (ProductRating=0)
Query data : Now we can use select * from table or specify the partition by condition. When we use partition condition internally the fetch data would be faster.
select * from product_ratings where ProductRating=0
Partitioning of table
- Hive creates tables in partitions.
- They are used to divide the table into related parts.
- Makes data querying more efficient.
Import data to hive from mysql contacts and account tables
- sqoop import –connect jdbc:mysql://localhost:3306/securemask \
- –username root –password cloudera \
- –table contacts \
- –fields-terminated-by “,” \
- –target-dir /user/cloudera/workspace/contactsmask \
hive-import
In this import we are specifying the schema and not the directory path
- sqoop import –connect jdbc:mysql://quickstart.cloudera/original \
- –username root –password cloudera \
- –table employee \
- –hive-import \
- –hive-table hiveschema.employee -m1 \
- –fields-terminated-by ‘\t’ \
- –direct;
Add UDF function
- hive> ADD JAR /home/cloudera/mask.jar;
- hive> CREATE TEMPORARY FUNCTION MASK AS ‘hiveudf.PImask’;
Create similar tables in Hive :
- hive> create table securedaccounts like accounts;
Data masking :
Insert masked phone number into accounts : insert overwrite table secured accounts select id,name,MASK(phone) from accounts;
Insert masked phone and email into contacts : insert overwrite table securedcontacts select id,accountid,firstname, lastname,MASK(phone),
MASK(email) from contacts; Move tables (securedcontacts,securedaccounts) from hive to my SQL
sqoop export –connect jdbc:mysql://localhost:3306/securemask
- username root –password cloudera
- table contacts
- export-dir /user/hive/warehouse/securedcontacts
RETRIEVING INFORMATION
| Function | MySQL | Hive |
|---|---|---|
| Retrieving Information (General) | SELECT from_columns FROM table WHERE conditions; | SELECT from_columns FROM table WHERE conditions; |
| Retrieving All Values | SELECT * FROM table; | SELECT * FROM table; |
| Retrieving Some Values | SELECT * FROM table WHERE rec_name = “value”; | SELECT * FROM table WHERE rec_name = “value”; |
| Retrieving With Multiple Criteria | SELECT * FROM TABLE WHERE rec1 = “value1″ AND rec2 =”value2”; | SELECT * FROM TABLE WHERE rec1= “value1″ AND rec2 =”value2”; |
| Retrieving Specific Columns | SELECT column_name FROM table; | SELECT column_name FROM table; |
| Retrieving Unique Output | SELECT DISTINCT column_name FROM table; | SELECT DISTINCT column_name FROM table; |
| Sorting | SELECT col1, col2 FROM table ORDER BY col2; | SELECT col1, col2 FROM table ORDER BY col2; |
| Sorting Reverse | SELECT col1, col2 FROM table ORDER BY col2 DESC; | SELECT col1, col2 FROM table ORDER BY col2 DESC; |
| Counting Rows | SELECT COUNT(*) FROM table; | SELECT COUNT(*) FROM table; |
| Grouping With Counting | SELECT owner, COUNT(*) FROM table GROUP BY owner; | SELECT owner, COUNT(*) FROM table GROUP BY owner; |
| Maximum Value | SELECT MAX(col_name) AS label FROM table; | SELECT MAX(col_name) AS label FROM table; |
| Selecting from multiple tables (Join same table using alias w/”AS”) | SELECT pet.name, comment FROM pet, event WHERE pet.name =event.name; | SELECT pet.name, comment FROM pet JOIN event ON (pet.name =event.name) |
METADATA
| Function | MySQL | Hive |
|---|---|---|
| Selecting a database | USE database; | USE database; |
| Listing databases | SHOW DATABASES; | SHOW DATABASES; |
| Listing tables in a database | SHOW TABLES; | SHOW TABLES; |
| Describing the format of a table | DESCRIBE table; | DESCRIBE (FORMATTED|EXTENDED)table; |
| Creating a database | CREATE DATABASE db_name; | CREATE DATABASE db_name; |
| Dropping a database | DROP DATABASE db_name; | DROP DATABASE db_name (CASCADE); |




