
Last updated on 03rd Jul 2020| 4880
Apache Hive interview questions span various facets of the platform, exploring topics essential for candidates to demonstrate their expertise in leveraging Hive for big data processing within the Hadoop ecosystem. Expectations typically include understanding Hive’s architecture, its integration with Hadoop, and proficiency in HiveQL, the SQL-like query language used for data retrieval and analysis. Interviewers may delve into advanced aspects like data partitioning, optimization strategies, and real-world applications, gauging the candidate’s ability to apply Hive effectively in big data scenarios. A comprehensive grasp of Hive’s features, limitations, and best practices is crucial for well-rounded interview preparation.
1. Define Hive.
Ans:
Hive, constructed atop the Hadoop Distributed File System (HDFS), is a data warehousing system with a SQL-like query language. Offering an elevated abstraction layer, it facilitates managing and querying extensive datasets stored in Hadoop. Hive proficiently translates SQL-like queries, or HiveQL, into MapReduce jobs, empowering users accustomed to SQL to conduct data analysis within the Hadoop environment.
2. Explain the key components of Hive architecture.
Ans:
Hive architecture consists of several components:
- Metastore: Stores metadata, including table schemas, partitions, and statistics.
- Query Processor: Translates HiveQL queries into execution plans.
- Driver: Coordinates tasks and communicates with the Hadoop ecosystem.
- Execution Engine: Executes tasks generated by the Query Processor.
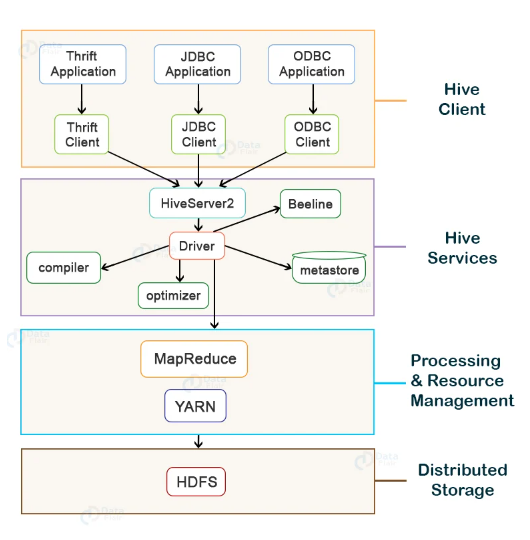
3. Differentiate between Hive and HBase.
Ans:
Hive is a data warehousing solution that facilitates querying and managing large datasets using a SQL-like language. In contrast, HBase is a NoSQL, distributed database designed for real-time read and write access to large datasets, offering low-latency random access to individual records.
4. What is the Hive Metastore?
Ans:
The Hive Metastore is a centralised repository that stores metadata about Hive tables, partitions, and columns. It decouples metadata from data, enabling better organisation and management. The Metastore is crucial for query optimization and efficient data retrieval.
5. How is data stored in Hive?
Ans:
Data in Hive is stored in tables. These tables can be stored as text files, sequence files, or in various other formats. The choice of storage format impacts factors like query performance, compression, and compatibility with other Hadoop ecosystem tools.
6. What are Hive UDFs and UDAFs?
Ans:
User-Defined Functions (UDFs) and User-Defined Aggregation Functions (UDAFs) are custom functions created by users to extend Hive’s functionality. UDFs operate on a single row, while UDAFs operate on groups of rows, providing a way to perform custom processing within Hive queries.
7. Explain the difference between Hive internal tables and external tables.
Ans:
Internal tables store data in a directory controlled by Hive. Dropping an internal table removes both metadata and data. External tables, on the other hand, reference data outside the Hive-managed directory. Dropping an external table only removes metadata, leaving the data intact.
8. What is the significance of HiveQL?
Ans:
HiveQL is a query language used in Hive to interact with and query data. It provides a SQL-like syntax, making it accessible to users familiar with relational databases. HiveQL simplifies the intricacies of crafting MapReduce programs, enabling users to articulate queries in a declarative and recognizable fashion.
9. What is Hive partitioning, and how does it improve performance?
Ans:
Hive partitioning involves dividing a table into subdirectories based on specific column values. This improves query performance by allowing Hive to skip unnecessary data during query execution. Partitioning is particularly beneficial when dealing with large datasets, as it enables more efficient data retrieval.
10. Discuss Hive bucketing and its purpose.
Ans:
Hive bucketing involves dividing data into more manageable parts called buckets based on the hash values of a column. This helps improve query performance by allowing for more efficient sampling and join operations. Bucketing is beneficial when there is a need for data organisation that complements specific types of queries and enhances overall processing efficiency.
11. Explain Hive indexing and its types.
Ans:
Hive indexing involves creating additional data structures to enhance the speed of data retrieval in queries. Types of indexing in Hive include:
- Bitmap Indexes: Map each distinct value to a bitmap, improving search performance for equality conditions.
- Compact Indexes: Store key-value pairs in a compact format, reducing storage overhead.
- Bitarray Indexes: Represent distinct values using bit arrays, optimising query performance.
12. What is the role of SerDe in Hive?
Ans:
SerDe, short for Serializer/Deserializer, is a crucial component in Hive that manages the serialisation and deserialization of data. It defines how data is transformed into a format suitable for storage in Hive tables and how it is presented during query results. Custom SerDe implementations can handle various data formats, making Hive versatile in processing different types of data.
13. How does Hive optimise query performance?
Ans:
Hive employs several techniques to optimise query performance:
- Query Optimization: It involves transforming queries into more efficient execution plans.
- Data Partitioning: Partitioning data based on specific columns enhances query performance by reducing the amount of data scanned.
- Indexing: Creating indexes on columns accelerates query response times by allowing faster lookup of values.
14. What is the importance of HiveServer2 in Hive architecture?
Ans:
HiveServer2 is a JDBC server that allows external clients to interact with Hive and execute Hive queries. It provides improved security features, supporting authentication and authorization mechanisms. HiveServer2 is more scalable than its predecessor, supporting multiple concurrent connections and queries.
15. Differentiate between dynamic partitioning and static partitioning in Hive.
Ans:
| Aspect | |||
| Definition | Automatically creates partitions based on the values in the data. | Requires explicit declaration of partition values during table creation. | |
| Flexibility | Offers more flexibility as partitions are determined dynamically during data insertion. | Limited flexibility as partition values need to be predefined. | |
| Use Case | Suitable for scenarios with evolving and unpredictable data patterns. | Ideal for stable and known partition values. | |
| Syntax Example | INSERT INTO TABLE dynamic_part_tbl PARTITION (col1) VALUES (…); | INSERT INTO TABLE static_part_tbl PARTITION (col1=’value’) VALUES (…); | |
| Query Performance | Depending on the data distribution, dynamic partitioning may offer better performance. | Performance benefits may be realized in scenarios with a fixed set of partitions. | |
| Compatibility with Tools | Compatible with a broader range of data loading tools as partition values are determined dynamically. | Requires tools to be aware of and handle predefined partition values. |
16. What is Hive’s ACID compliance, and why is it important?
Ans:
ACID (Atomicity, Consistency, Isolation, Durability) compliance in Hive ensures that transactions are processed reliably. Atomicity ensures transactions are treated as a singular unit; Consistency ensures the database remains in a valid state, Isolation prevents interference between transactions, and Durability guarantees that committed transactions persist even in the face of system failures. ACID compliance is crucial in scenarios involving concurrent write operations to maintain data integrity and consistency.
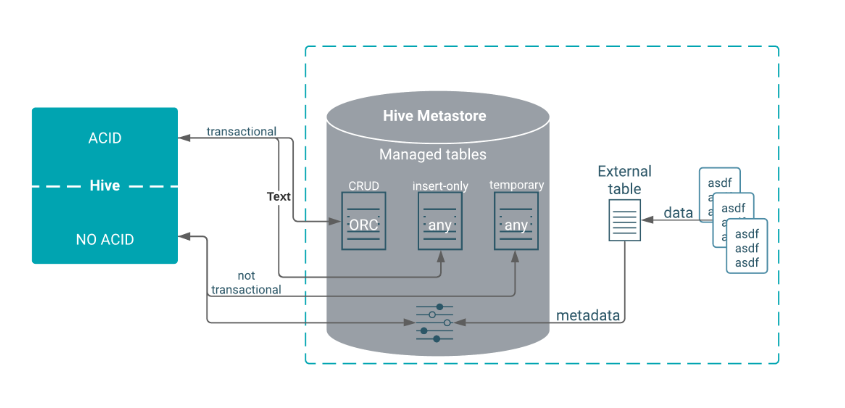
17. Explain the Hive view and its usage.
Ans:
- A Hive view is a virtual table that is based on the result of a SELECT query.
- Views simplify complex queries by encapsulating them, providing a layer of abstraction over the underlying tables. They are used to present a structured and simplified view of data, allowing users to query the view as if it were a regular table.
18. How does Hive handle complex data types?
Ans:
Hive supports complex data types such as structs, arrays, and maps.
These data types can be used in table definitions to represent nested or hierarchical data structures. Hive provides functions and operators to manipulate and query data within these complex types, allowing for flexible and expressive data processing.
19. Discuss Hive transactional tables.
Ans:
- Hive transactional tables support atomic and consistent transactions.
- They allow for ACID-compliant operations on Hive tables, ensuring data integrity in scenarios involving multiple concurrent transactions.
- Transactional tables are essential for maintaining consistency and reliability in data processing workflows.
20. What are the advantages of using Hive in Hadoop ecosystems?
Ans:
- SQL-Like Query Language (HiveQL): Hive offers a familiar SQL-like language, making it accessible to users with SQL skills.
- Scalability: It leverages the Hadoop ecosystem for distributed storage and processing, enabling scalability for large-scale data sets.
- Ecosystem Integration: Hive seamlessly integrates with other Hadoop components, such as HDFS and MapReduce, facilitating comprehensive data processing and analytics workflows.
21. How does Hive handle schema evolution?
Ans:
Hive supports schema evolution by allowing users to add new columns to existing tables without requiring modifications to the stored data. This is achieved using SerDe (Serializer/Deserializer) and compatibility attributes. When new columns are introduced, Hive accommodates them during query execution, making it adaptable to evolving data requirements.
22. What are the storage formats supported by Hive?
Ans:
Hive supports a variety of storage formats to cater to different use cases. These include:
- TextFile: Simple and human-readable, suitable for structured and semi-structured data.
- SequenceFile: A binary format suitable for large datasets.
- ORC (Optimised Row Columnar): Columnar storage format provides better compression and performance.
- Parquet: A columnar storage format optimised for performance and compatibility with various processing frameworks.
- Avro: A compact binary format with support for schema evolution.
23. How does Hive differ from traditional relational databases?
Ans:
Hive differs from traditional relational databases in its design and use case. While conventional databases are optimised for transactional processing with a schema-on-write approach, Hive is designed for the analytical processing of large-scale data using a schema-on-read model. It operates on top of Hadoop, making it suitable for big data scenarios.
24. Discuss Hive’s role in the Hadoop ecosystem.
Ans:
Hive plays a crucial role in the Hadoop ecosystem as a data warehousing solution. It provides a SQL-like query language (HiveQL) for querying and analysing data stored in Hadoop Distributed File System (HDFS). Hive simplifies data processing tasks, making it accessible to users familiar with SQL, and it integrates seamlessly with other Hadoop components for comprehensive big data analytics.
25. Explain the concept of Hive skew join optimization.
Ans:
Hive skew joins optimization addresses performance challenges caused by skewed data distribution in join operations. Uneven distribution of data across join keys can significantly affect the overall performance when data is not uniformly distributed among the join keys. Skew join optimization redistributes data among tasks to balance the workload, preventing performance bottlenecks associated with skewed data.
26. How can you improve Hive query performance?
Ans:
- Improving Hive query performance involves several strategies:
- Optimise queries by understanding and rewriting them for better efficiency.
- Partition tables to reduce the amount of data scanned.
- Choose appropriate storage formats like ORC or Parquet for better compression and query speed.
- Enable vectorization to process data in batches, enhancing performance.
- Tune configuration parameters such as memory settings and parallelization to match the cluster’s capabilities.
- Use indexing and collect statistics on tables to aid the query planner.
27. What is the role of the Hive execution engine in query processing?
Ans:
The Hive execution engine is responsible for processing Hive queries. It interprets HiveQL queries, creates execution plans, and coordinates the execution of tasks. Common execution engines include MapReduce, Tez, and Spark. The choice of execution engine impacts the performance and scalability of Hive queries, and it can be configured based on specific use cases and cluster characteristics.
28. Discuss the use of Hive for ETL processes.
Ans:
Hive is widely used in big data environments for Extract, Transform, and Load (ETL) processes. It streamlines the conversion of raw and unstructured data into a formatted structure conducive to analysis. HiveQL supports various ETL operations, including data cleansing, aggregation, and filtering, making it a valuable tool for preparing data for downstream analytics.
29. What are the limitations of Hive?
Ans:
- Limited support for real-time processing due to its batch-oriented nature.
- Challenges with low-latency queries, making it less suitable for interactive analytics.
- Issues with small file sizes, leading to suboptimal performance.
- Specific complex query patterns may face limitations compared to traditional relational databases.
30. Explain Hive variable substitution and its usage.
Ans:
Hive variable substitution allows users to dynamically replace placeholders with values in scripts or queries. Variables can be set and utilized to parameterize scripts, enhancing reusability and flexibility. For example, users can set variables for database names, file paths, or configuration options, providing a convenient way to customise the behaviour of Hive scripts and queries.
31. What is the purpose of the Hive authorization model?
Ans:
The Hive authorization model serves the critical role of ensuring secure access control to Hive resources and data. It establishes and enforces security policies, specifying who has permission to perform various operations on databases, tables, and other Hive objects. This model enhances the overall security posture of the Hive environment by regulating user access and maintaining data confidentiality and integrity.
32. How can you troubleshoot performance issues in Hive queries?
Ans:
Troubleshooting performance issues in Hive queries involves a multifaceted approach. It includes analysing the execution plans of queries using the EXPLAIN statement to understand the logical and physical steps involved. Optimising queries by considering indexing and partitioning strategies, reviewing data skewness, and ensuring proper resource allocation are crucial steps. Additionally, monitoring system resource usage and leveraging profiling tools aid in identifying and resolving performance bottlenecks.
33. What is the Hive Beeline tool, and how is it used?
Ans:
Hive Beeline is a versatile command-line interface that facilitates interaction with Hive. It operates as a JDBC client, allowing users to establish connections to Hive and execute queries, scripts, and commands. Beeline is particularly useful for scenarios where external applications or scripts need to connect to Hive, offering a convenient means to work with Hive functionalities in a programmatic manner.
34. Is it possible to designate the creator’s name for a table in Hive?
Ans:
Yes, you can specify the creator’s name for a table in Hive using the COMMENT clause during table creation. For example:
- CREATE TABLE my_table (
- column1 INT,
- column2 STRING
- ) COMMENT ‘Created by John Doe’;
35. Discuss the role of Hive in data warehousing.
Ans:
Hive holds a crucial position in data warehousing within the Hadoop ecosystem by furnishing a SQL-like interface (HiveQL). This interface empowers users to interrogate and examine extensive datasets residing in Hadoop. This facilitates the organisation and structuring of data, making it well-suited for reporting, analytics, and data warehousing tasks. By leveraging Hive, organisations can efficiently process and derive insights from vast amounts of data stored in Hadoop clusters.
36. What is the Hive execution plan, and how is it generated?
Ans:
The Hive execution plan, generated using the EXPLAIN statement, is a detailed roadmap outlining the logical and physical steps involved in the execution of a Hive query. The generation of this plan is orchestrated by the Hive query compiler and optimizer. The plan provides insights into how the query will be processed, including the sequence of operators and stages in the execution flow, aiding users in understanding and optimizing their queries for efficiency.
37. Explain the role of the Hive CLI (Command Line Interface).
Ans:
- The Hive Command Line Interface (CLI) serves as an interactive and scriptable tool for users to interact with Hive.
- It allows users to enter HiveQL queries directly, manage Hive databases and tables, and perform administrative tasks in a command-line environment.
- The Hive CLI is well-suited for interactive usage and scripting, providing a straightforward means for users to work with Hive functionalities without the need for a graphical interface.
38. Discuss the difference between Hive and Pig.
Ans:
Hive and Pig are both high-level scripting languages within the Hadoop ecosystem, each catering to distinct use cases and preferences. Utilising a SQL-like language (HiveQL), Hive is particularly suited for users familiar with SQL and excels in structured data processing. On the other hand, Pig employs a data flow scripting language and is more flexible, making it suitable for complex data processing tasks. While Hive is favoured for structured data and SQL-like queries, Pig offers greater flexibility for diverse data processing scenarios.
39. What is the purpose of Hive’s MapReduce engine?
Ans:
Hive’s MapReduce engine is instrumental in executing Hive queries by translating HiveQL queries into a series of MapReduce jobs. This engine adheres to the MapReduce programming model, enabling Hive to efficiently process and analyze data stored in Hadoop. It assumes a pivotal role in coordinating the distributed computations essential for processing large-scale data, guaranteeing the smooth execution of queries within the Hadoop ecosystem.
40. Explain Hive’s approach to handling NULL values.
Ans:
In Hive, NULL values are treated as unknown or undefined. When querying data, Hive incorporates NULL values in comparisons, aggregations, and other operations. Conditions such as IS NULL and IS NOT NULL are employed to filter or identify NULL values in Hive queries. This approach to handling NULL values ensures consistency and accuracy in query results, allowing users to effectively manage and analyze datasets containing unknown or missing information.
41. Describe the concept of a function in Hive using an example.
Ans:
Hive functions allow users to perform operations on data within queries. For instance:
-
SELECT CONCAT(first_name, ‘ ‘, last_name) AS full_name FROM employees;
Here, the CONCAT function concatenates the first_name and last_name columns, creating a new column named full_name.
42. How can you implement row-level security in Hive?
Ans:
Row-level security in Hive can be implemented through various methods:
- Views: Create views that filter data based on user roles.
- Custom UDFs: Develop User-Defined Functions (UDFs) to enforce security rules.
- Built-in Security Features: Leverage Hive’s built-in column-level privileges to control access.
43. How does Hive support custom serialisation and deserialization?
Ans:
Hive supports custom serialisation and deserialization through SerDes (Serializer/Deserializer). Users can define their SerDes to handle data formats not natively supported by Hive, allowing for integration with various data sources.
44. What are the benefits of using the ORC file format in Hive?
Ans:
The ORC file format in Hive offers several advantages. It provides better compression, reducing storage requirements. ORC files are optimised for reading, improving query performance by minimising I/O operations. This makes ORC suitable for large-scale data processing in data warehouses.
45. Discuss Hive views and their use cases.
Ans:
Hive views act as a logical layer on top of tables, offering a simplified way to query data. Use cases include:
- Security: Views have the capability to limit access to particular columns or rows.
- Abstraction: Views shield users from underlying schema changes.
- Query Simplification: Complex queries can be encapsulated in views, providing a cleaner interface for end-users.
46. How can the data type of a column be modified in Hive? Explain the RLIKE function in Hive.
Ans:
Data Type Modification: To change the data type of a column, use the ALTER TABLE statement. For example: ALTER TABLE table_name CHANGE column_name new_data_type.
RLIKE Function: The RLIKE function in Hive is used for pattern matching. For instance: SELECT * FROM table WHERE column RLIKE ‘^A.*’ selects rows where the column starts with ‘A’.
47. Explain Hive vectorization and its advantages.
Ans:
Hive vectorization is a technique where operations are performed on batches of data, improving query performance. Advantages include:
- CPU Efficiency: Reduced CPU overhead by processing data in vectorized form.
- I/O Efficiency: Fewer I/O operations due to optimized processing.
- Query Speed: Enhanced query speed, especially for operations like scanning and filtering.
48. What is the Hive AUXJARS configuration property used for?
Ans:
The Hive AUXJARS configuration property is utilised to specify additional JAR files containing custom SerDes or UDFs. This allows users to extend Hive’s functionality with custom code and libraries.
49. How can you monitor Hive performance using metrics?
Ans:
Hive provides various performance-related metrics that can be monitored using tools like Apache Ambari or by querying the Hive metrics tables. These metrics include information on query execution times, resource utilisation, and other performance indicators.
50. Explain the Hive TEZ execution engine and its benefits.
Ans:
Hive TEZ is an execution engine designed to optimise task execution in Hive queries. Benefits include:
- Resource Utilisation: TEZ optimises resource utilisation for better performance.
- Reduced Execution Time: TEZ can significantly reduce query execution time compared to traditional engines like MapReduce.
- Enhanced Efficiency: TEZ improves overall efficiency in processing complex queries in Hive.

Best Apache Hive Certification Course with Advanced Concepts from Real Time Experts
Weekday / Weekend BatchesSee Batch Details51. What is the purpose of the Hive LATERAL VIEW?
Ans:
The Hive LATERAL VIEW is utilised to address scenarios involving complex data types like arrays and maps. It allows for the creation of additional rows in the result set for each element within the complex data type. This is particularly beneficial when dealing with nested structures, enabling the unnesting of these structures for more accessible analysis and processing in Hive queries.
52. How does Hive handle schema-on-read and schema-on-write?
Ans:
Traditionally, Hive follows a schema-on-read approach. This means that data is stored without a predefined schema, and the schema is applied during the query processing phase. However, with the introduction of optimised file formats such as ORC (Optimised Row Columnar) and Parquet, Hive now supports schema-on-write. This means that the schema can be defined and applied during the data storage process, leading to enhanced performance during query execution.
53. What is the Hive Strict Mode, and when is it used?
Ans:
The Hive Strict Mode is a setting that enforces strict data type checking during the execution of Hive queries. When enabled, it ensures that there are no implicit type conversions during operations, making the queries more robust and reducing the chances of errors caused by unexpected data type mismatches. This mode proves especially beneficial in situations where maintaining strict adherence to data types is essential for upholding data integrity and ensuring query accuracy.
54. Explain the concept of Hive bucketed tables and their advantages.
Ans:
- Hive bucketed tables involve organising data into buckets based on hash values of a specified column.
- This technique provides several advantages, including improved query performance for certain types of joins.
- Bucketing helps distribute data evenly across buckets, reducing data skewness and enhancing parallel processing.
- It also allows for more efficient sampling and optimised analytics when dealing with large datasets.
55. How does Hive Tez differ from Hive MapReduce?
Ans:
Hive Tez is an alternative execution engine within Hive that differs from the traditional Hive MapReduce execution. Tez utilises directed acyclic graphs (DAGs) for query execution, providing improved performance, reduced latency, and better resource utilisation compared to Hive MapReduce. Tez achieves this by optimising the execution plan and enabling more efficient data movement and computation.
56. How can you handle JSON data in Hive?
Ans:
Hive provides built-in functions to handle JSON data. The get_json_object function is commonly used to extract specific values from JSON strings, while the json_tuple function is employed for parsing JSON arrays. These functions facilitate the integration of JSON data into Hive queries, allowing for seamless processing and analysis of JSON-formatted information.
57. What is the purpose of the Hive Tez UI, and how can it be accessed?
Ans:
The Hive Tez UI serves as a graphical user interface that provides detailed insights into the execution of Tez queries within Hive. It offers information about vertices, tasks, and their progress during the query execution process. To access the Hive Tez UI, one can typically navigate to the Tez application master’s web interface, where the UI is hosted.
58. Discuss the Hive HBase integration and use cases.
Ans:
The integration between Hive and HBase enables seamless querying and analysis of HBase data using the familiar Hive SQL interface. This integration is particularly valuable for scenarios where real-time access to HBase data is required, but analytical processing is more efficiently handled by Hive. Use cases include combining the strengths of both systems to achieve a balance between real-time capabilities and analytical insights, making it suitable for diverse applications such as reporting, analytics, and business intelligence.
59. How does Hive handle data skewness in joins?
Ans:
Hive employs several techniques to address data skewness challenges that may arise during join operations. These techniques include automatic map join optimization, which leverages hash-based techniques to handle skewed keys efficiently. Additionally, bucketed map join is used to distribute data uniformly across buckets, mitigating the impact of skewed data. Dynamic partition pruning is another strategy where Hive optimises query plans by excluding unnecessary partitions during execution, contributing to improved performance in the presence of data skewness.
60. Explain the concept of Hive HLL (HyperLogLog) functions.
Ans:
- Hive HLL functions implement the HyperLogLog algorithm, providing an approximate and memory-efficient method for estimating distinct counts in large datasets.
- These functions are valuable in scenarios where an exact count of distinct values may be impractical due to the sheer volume of data.
- Hive HLL functions offer a compromise between accuracy and computational efficiency, making them suitable for applications that require cardinality estimation while minimising resource consumption.
61. What is the Hive EXPLAIN statement used for?
Ans:
The Hive EXPLAIN statement is employed to analyze and understand the execution plan of a Hive query. It provides insights into how the query will be processed, including details about the logical and physical execution steps, the order of operations, and optimization strategies. EXPLAIN helps users optimize queries by identifying potential bottlenecks and areas for improvement in the query plan.
62. Discuss the significance of Hive’s Vectorization Query Engine.
Ans:
Hive’s Vectorization Query Engine is crucial for enhancing query performance. It leverages vectorized processing techniques, enabling the execution of operations on entire batches of data at once, rather than row by row. This approach significantly improves the efficiency of query processing, leading to faster execution times and better utilization of hardware resources.
63. How does Hive handle table statistics, and why are they important?
Ans:
Hive maintains statistics about tables, including information about data distribution and size. These statistics are crucial for the query optimizer to generate efficient execution plans. By having accurate statistics, Hive can make informed decisions about join strategies, data distribution methods, and other optimizations, ultimately improving query performance.
64. Explain the role of the Hive ACID ARCHIVE directory.
Ans:
The Hive ACID ARCHIVE directory is used to store historical data versions in Hive ACID (Atomicity, Consistency, Isolation, Durability) tables. When updates or deletes occur on ACID tables, the old versions of affected records are moved to the ACID ARCHIVE directory, allowing for point-in-time querying and recovery.
65. What is the Hive Query Language (HQL), and how is it different from SQL?
Ans:
- Hive Query Language (HQL) is a SQL-like language designed for querying and processing data in Apache Hive.
- It shares similarities with SQL but may have variations and extensions to accommodate the characteristics of Hadoop and Hive.
- HQL allows users to express queries using SQL-like syntax, making it more accessible for those familiar with traditional relational databases.
66. How does Hive support indexing for improving query performance?
Ans:
Hive supports indexing through techniques like Bitmap Indexes and Bloom Filters. These indexes enhance query performance by allowing Hive to skip irrelevant data blocks during query execution. While not as extensive as traditional database indexes, these techniques contribute to more efficient query processing in Hive.
67. Explain the concept of Hive materialized views.
Ans:
Hive materialized views are precomputed and stored query results that can be referenced to improve query performance. They are created based on specified query patterns and provide faster access to aggregated or computed data. Materialized views are particularly beneficial for complex queries and large datasets, reducing the need for redundant computations.
68. Discuss the purpose of the Hive resource manager.
Ans:
- The Hive resource manager is responsible for managing and allocating resources within a Hive environment.
- It ensures fair distribution of resources among concurrent queries, preventing resource contention and optimizing overall system performance.
- Resource managers like YARN and standalone modes facilitate efficient resource utilization in Hive.
69. How can you implement security measures in Hive to control access?
Ans:
Hive provides various security features, including user authentication, authorization, and encryption. Users can be authenticated through mechanisms like Kerberos. Access control is implemented through role-based authorization, allowing administrators to define and manage user privileges. Encryption ensures the confidentiality of data during transmission and storage, contributing to a secure Hive environment.
70. How does Hive handle nested data structures and complex types?
Ans:
Hive supports nested data structures and complex types such as arrays, maps, and structs. Users can query, manipulate, and analyze data within these structures using appropriate Hive functions. Hive’s ability to handle nested data structures makes it versatile for processing diverse datasets and complex data models.
71. Discuss the advantages of using Hive LLAP (Live Long and Process).
Ans:
Hive LLAP, or Live Long and Process, offers significant advantages in terms of improved query performance and interactive query processing. It provides low-latency access to data by maintaining long-lived daemons that cache and reuse query plans. This architecture enables faster query execution, reduced query latencies, and enhanced support for interactive and ad-hoc querying in Hive.
72. Does Hive support multi-line comments?
Ans:
Yes, Hive supports multi-line comments. You can use the /* */ syntax for multi-line comments. Here’s an example:
- /*
- This is a multi-line comment in Hive.
- It can span across multiple lines.
- Useful for adding detailed explanations or notes.
- */
- SELECT * FROM my_table;
73. Explain the concept of Hive Dynamic Resource Allocation (DRA).
Ans:
Hive Dynamic Resource Allocation (DRA) allows dynamic adjustment of resources allocated to queries based on workload demands. It ensures efficient resource utilization by allocating additional resources to queries requiring more resources dynamically. This adaptability enhances overall cluster performance and responsiveness, particularly in dynamic and shared resource environments.
74. How can you configure Hive to use a specific execution engine?
Ans:
Hive supports multiple execution engines, such as MapReduce, Tez, and Spark. Configuration settings in Hive can be adjusted to specify the desired execution engine. The hive.execution.engine property in the Hive configuration file (hive-site.xml) can be set to values like mr for MapReduce, tez for Tez, or spark for Apache Spark, depending on the preferred execution engine.
75. What is the significance of the Hive HCatalog component?
Ans:
- Hive HCatalog is a metadata and table management system that provides a unified view of data stored in Hadoop Distributed File System (HDFS).
- It enables seamless interaction between different data processing tools by providing a common metadata store.
- HCatalog simplifies data sharing and integration across various Hadoop ecosystem components, promoting interoperability and ease of use.

Enroll in Apache Hive Certification Training with Advanced Concepts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
76. Explain how Hive integrates with Apache Spark.
Ans:
Hive can integrate with Apache Spark through the Hive Spark Thrift Server. This integration allows users to run Hive queries using the Spark execution engine. The Hive on Spark mode leverages the strengths of both systems, combining Hive’s SQL-like querying capabilities with Spark’s distributed computing capabilities for efficient data processing and analytics.
77. Discuss the Hive ACID DELETE operation.
Ans:
- The Hive ACID DELETE operation is part of Hive’s support for ACID (Atomicity, Consistency, Isolation, Durability) transactions.
- It allows users to delete specific rows from ACID-compliant tables.
- The operation ensures that the delete operation is atomic and consistent, and it is particularly useful in scenarios where selective data deletion is required while maintaining transactional integrity.
78. Explain the purpose of the Hive ORC (Optimized Row Columnar) file format.
Ans:
The Hive ORC file format is designed for optimal performance and storage efficiency. It stores Hive data in a columnar format, allowing for better compression and improved query performance. ORC files support features like predicate pushdown and lightweight indexing, making them well-suited for data warehousing and analytical processing in Hive.
79. How can you handle data serialization and deserialization in Hive?
Ans:
Hive uses SerDe (Serializer/Deserializer) libraries to handle data serialization and deserialization. Users can specify the SerDe for a table during table creation to customize how data is formatted when written to or read from files. This flexibility allows Hive to work with various data formats and structures, making it versatile in handling diverse data sources.
80. Discuss the role of Hive AcidHouseKeeper and its significance.
Ans:
- Hive AcidHouseKeeper is a component responsible for cleaning up obsolete files and managing compactions in Hive ACID (Atomicity, Consistency, Isolation, Durability) tables.
- It assumes a pivotal role in sustaining the efficiency and integrity of ACID transactions through the periodic execution of essential housekeeping tasks.
- AcidHouseKeeper ensures that the storage space is optimized, and the historical versions of data are appropriately managed, contributing to the overall stability of the system.
81. What are the limitations of Hive streaming for real-time processing?
Ans:
Hive streaming, while powerful for batch processing, has limitations in real-time scenarios due to inherent latency. It operates in batch mode, introducing delays in processing, making it less suitable for applications requiring low-latency responses. Real-time processing demands immediate data insights, a requirement that Hive streaming may not fully meet.
82. Explain the Hive Authorization Model and its components.
Ans:
The Hive Authorization Model is a comprehensive system governing access control in Hive. It consists of roles, privileges, and grants. Roles are groups of users, privileges define specific actions, and grants assign these privileges to roles or individual users. This model ensures a robust access control mechanism, allowing administrators to manage permissions effectively.
83. How does Hive support multi-table inserts in a single query?
Ans:
Hive facilitates multi-table inserts through the INSERT INTO clause. Users can either use INSERT INTO… VALUES or INSERT INTO … SELECT to insert data into multiple tables within a single query. This feature streamlines data insertion processes and enhances the efficiency of complex queries.
84. Explain the role of the Hive Cost-Based Optimizer (CBO).
Ans:
- The Hive Cost-Based Optimizer is integral to query optimization.
- It evaluates potential query plans based on estimated costs and selects the most efficient plan.
- Factors considered include data distribution, statistics, and join conditions.
- The CBO significantly contributes to improved query performance by selecting optimal execution plans.
85. What are the best practices for managing Hive table partitions efficiently?
Ans:
Efficient Hive table partition management involves thoughtful choices of partition columns, minimising the number of partitions, and regularly updating statistics. Additionally, utilising an optimal file format and organising data based on partition keys are crucial for enhancing performance. Regular maintenance, such as vacuuming and analysing, further contributes to efficient partitioning.
86. How can one exclude header rows from a table in Hive?
Ans:
- To exclude header rows during table creation, users can employ the TBLPROPERTIES clause and set the skip.header.line.count property.
- Alternatively, during data loading with the LOAD DATA command, the IGNORE option can be used to skip header rows.
- These mechanisms ensure the exclusion of headers from the Hive table.
87. Describe the steps involved in recursively accessing subdirectories in Hive queries.
Ans:
Recursively accessing subdirectories in Hive is accomplished by using the SHOW command with the RECURSIVE keyword or specifying the recursive option in the dfs URI. This instructs Hive to explore subdirectories recursively, allowing for the retrieval of data from nested directory structures in a comprehensive manner.
88. Is it possible to modify settings within a Hive session? If so, how can it be done?
Ans:
Yes, it is possible to modify settings within a Hive session using the SET command. This command allows users to alter configuration parameters temporarily for the current session. It provides a flexible way to customize session-specific configurations without affecting the overall Hive environment.
89. Illustrate the functionality of the Trim and Reverse functions in Hive, providing examples.
Ans:
The TRIM function in Hive eliminates leading and trailing spaces from a string.
-
SELECT TRIM(‘ Hello ‘) returns ‘Hello’
On the other hand, the REVERSE function reverses the characters in a string.
-
SELECT REVERSE(‘Hive’) returns ‘eviH’
These functions contribute to string manipulation and formatting in Hive queries.
90. What is the order of precedence for Hive configuration?
Ans:
The order of precedence for Hive configuration follows a hierarchical structure. It begins with system-level defaults, progresses to settings in Hive-site.xml, incorporates Hadoop configuration, considers Hadoop environment variables, and, finally, includes session-specific settings. This hierarchical approach provides a layered and customizable configuration system catering to different levels of the Hive environment.
91. What are the considerations when optimising Hive queries for large datasets?
Ans:
Optimising Hive queries for large datasets involves several considerations. Partitioning and bucketing tables, choosing appropriate file formats (e.g., ORC or Parquet), optimising join strategies, and utilising vectorization are essential. Additionally, proper indexing, managing data skewness, and adjusting memory configurations contribute to optimising Hive queries for large-scale data processing.
92. What are Hive-managed tables, and when are they used?
Ans:
Hive-managed tables are tables where Hive assumes control over the entire lifecycle of the data, including storage and metadata management. These tables are employed when users prefer Hive to handle the underlying details of table management. Hive-managed tables are particularly useful in scenarios where Hive is the primary tool for organising and managing data, simplifying administrative tasks for users.




