
Last updated on 17th Jul 2025| 11319
- Introduction
- Importance of XPath in Selenium
- Types of XPath
- How XPath Works
- Absolute vs Relative XPath
- Advantages of Using XPath
- XPath vs Other Locator Strategies
- Conclusion
Introduction
In web automation testing, accurately locating web elements is one of the most crucial tasks for creating stable and efficient test scripts. Selenium WebDriver, a widely used automation tool, offers several locator strategies to identify elements on a webpage. These include using ID, name, class name, link text, CSS selectors, and XPath. Among these, XPath is one of the most powerful and flexible options, especially when dealing with complex or dynamically changing HTML structures. XPath, which stands for XML Path Language, is used to navigate through elements and attributes in an XML or HTML document. In Selenium, it allows testers to locate elements based on their hierarchy, attributes, text content, or position relative to other elements. This makes it an essential tool for scenarios where simpler locators like ID or class name are insufficient. There are two types of XPath: absolute and relative. Absolute XPath starts from the root of the document and follows a direct path to the element, making it sensitive to layout changes. Relative XPath, on the other hand, begins from a node of interest and is more flexible, making it the preferred choice for test automation. XPath expressions can be enhanced using conditions such as contains, starts-with, and text matches, enabling testers to pinpoint elements with greater precision. Logical operators and indexing can also be used to refine element selection. In summary, XPath provides the ability to locate elements in a variety of ways, making it a versatile and reliable strategy in Selenium automation. Mastery of XPath can significantly improve the accuracy and maintainability of automated tests, especially in complex web applications.
Interested in Obtaining Your Software Testing Certificate? View The Software Testing Training Course Offered By ACTE Right Now!
Importance of XPath in Selenium
XPath is a powerful and widely used locator strategy in Selenium WebDriver, especially valuable when dealing with dynamic or complex web applications. One of the primary reasons for its popularity is its ability to accurately identify elements even when they lack unique identifiers such as IDs or names. Unlike other locators, XPath can navigate through the entire Document Object Model (DOM) to find elements based on a variety of attributes, structures, or text content. One of the key advantages of XPath is its dynamic nature. It allows testers to locate elements based on their position in the DOM or their relationship to other elements, such as parent, sibling, or child nodes. This relational capability makes XPath highly adaptable when the structure of a webpage changes frequently, which is common in modern web applications. XPath also supports the use of attribute values for element identification, offering flexibility that other locators may not provide.

For example, elements can be located using partial attribute matches with functions like contains or starts-with, which is especially helpful when dealing with dynamically generated attribute values. Another strength of XPath is its support for text-based searches. This means testers can locate elements by their visible text content, which is often the most human-readable and reliable identifier in user-facing components. Moreover, XPath enables navigation not only downwards through the DOM tree but also upwards and sideways capabilities that CSS selectors lack. This multidirectional traversal allows for more comprehensive and contextual element identification. Lastly, XPath is compatible with both HTML and XML documents, making it a versatile tool for automation across different types of web technologies. For all these reasons, XPath plays a vital role in Selenium testing, providing unmatched precision and flexibility for locating web elements.
Types of XPath
- Absolute XPath: Starts from the root element of the HTML document and follows a full path to the target element. It uses a single forward slash (/) and defines each node in sequence.
- Relative XPath: Begins from a specific element or node in the DOM using double slashes (//), making it shorter and more flexible. It is widely used because it is less affected by structural changes in the HTML.
- XPath with Attribute: Selects elements based on the value of a specific attribute, such as id, name, or class. This is one of the most reliable and commonly used types, especially when attributes are unique.
- XPath using Text(): Locates elements based on their exact visible text content. This is useful when the text inside an element is consistent and unique, such as a button label or a heading.
- XPath using Contains(): Matches elements that contain a specific substring within an attribute or text. This is helpful for identifying elements with dynamic or partially known values.
- XPath using Starts-With(): Selects elements where an attribute value starts with a given string. It is particularly useful for handling elements with dynamic IDs or classes that follow a predictable pattern.
- XPath using Axes: Navigates between nodes based on their relationship in the DOM, such as parent, child, sibling, or ancestor. This is valuable for locating elements relative to others when direct identification is not possible.
- XPath Overview: XPath is a language used to navigate and locate parts of an HTML or XML document. It helps identify elements, attributes, and text by following the structure of the document.
- DOM Hierarchy: The DOM, or Document Object Model, represents a webpage as a tree-like structure. Each node in this tree stands for an element, an attribute, or a piece of text. XPath is used to move through this hierarchy and select specific parts of the page.
- Root Selector: This selects nodes starting from the root of the document. It moves through the structure step by step, beginning from the top of the hierarchy.
- Anywhere Selector: This allows selection of nodes from any location in the document, regardless of their level in the hierarchy. It is useful when the exact path from the root is unknown or unnecessary.
- Current and Parent Nodes: There are specific selectors to indicate the current node being examined and its immediate parent. These help in writing relative paths instead of starting from the top each time.
- Attribute Selector: XPath can also target attributes of elements, such as class names or IDs. This makes it possible to find elements based on their properties, rather than just their position.
- Combining Expressions: Multiple XPath elements can be combined to create precise queries. This allows users to target exactly the part of the document they need by narrowing down the selection based on structure and attributes.
- Precise Element Selection: XPath allows for highly specific selection of elements within an HTML or XML document. It can target elements based on their position, attributes, hierarchy, or even text content, making it ideal for accurate data extraction.
- Supports Complex Queries: XPath supports complex expressions and conditions. You can combine multiple criteria such as element relationships, attributes, and text values to refine your search and retrieve exactly what you need from a document.
- Works with Any XML/HTML Structure: XPath is structure-based rather than language- or framework-specific. It can navigate any well-formed XML or HTML document, making it a flexible tool for a variety of applications including web scraping, test automation, and document analysis.
- Relative and Absolute Paths: XPath supports both relative and absolute paths. This means you can navigate from the root of the document or from any node, depending on your needs.
- Attribute and Text Matching: XPath can locate elements using attribute values or visible text, providing more ways to identify content. This is especially helpful when element positions change but their attributes or text remain consistent.
- Integration with Tools: XPath is widely supported in tools like Selenium, Scrapy, and browser developer consoles. This broad compatibility makes it easy to incorporate into web testing, data scraping, and automation workflows.
- Time-Saving and Efficient: By offering direct paths to elements, XPath reduces the time needed to locate or extract data. Its ability to handle dynamic and nested structures efficiently makes it a powerful tool for developers and testers alike.
To Earn Your Software Testing Certification, Gain Insights From Leading Blockchain Experts And Advance Your Career With ACTE’s Software Testing Training Course Today!
How XPath Works
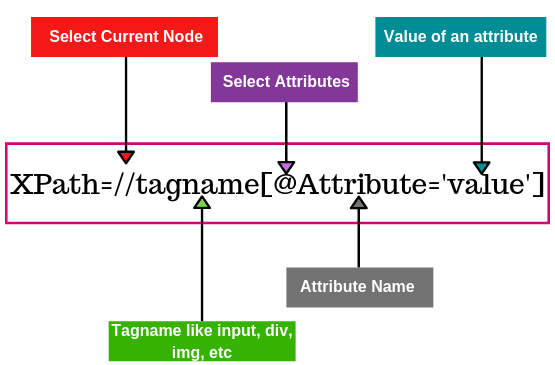

Absolute vs Relative XPath
XPath expressions are generally divided into two types: absolute and relative. Understanding these can help testers create more reliable and maintainable automation scripts. Absolute XPath refers to the complete path starting from the root element of the HTML document, moving step-by-step through each child node until it reaches the target element. This approach gives an exact location but is fragile; any small change in the page structure can cause the XPath to break, making it less suitable for dynamic web applications. Relative XPath, on the other hand, is far more flexible and commonly used in test automation. Instead of starting from the root, it allows you to search for elements based on specific attributes or text content, regardless of their exact position in the DOM. This makes relative XPath more robust, especially in pages that change frequently. It can locate elements by matching attribute values, visible text, or their relationship to other elements on the page. Another benefit of relative XPath is its ability to search through the entire document structure, making it ideal for locating elements that may be deeply nested or surrounded by dynamic content. Unlike absolute XPath, it is not tied to the exact hierarchy of the DOM, which reduces maintenance overhead when page layouts are updated. In summary, while absolute XPath provides a direct path and may be suitable for stable, static content, relative XPath offers a more adaptable and resilient solution. Its ability to handle dynamic layouts and locate elements contextually makes it a preferred choice in modern Selenium automation.
Want to Pursue a Software Testing Master’s Degree? Enroll For Software Testing Master Program Training Course Today!
Advantages of Using XPath
XPath vs Other Locator Strategies
While XPath is a powerful and versatile locator strategy, it is important to understand the value of other locators available in Selenium WebDriver. Each has its own strengths and is best suited to specific scenarios, depending on the structure and design of the web application. The ID locator is often considered the fastest and most reliable. When an element has a unique ID attribute, this method provides a direct and efficient way to access it. However, not all elements have unique IDs, especially in dynamically generated content. The Name locator is another straightforward option, useful when the name attribute is unique on the page. It is commonly used for form fields, though its reliability depends on how consistently names are assigned in the HTML. CSS selectors are also popular due to their speed and concise syntax. They are very effective for selecting elements based on class, ID, attributes, or hierarchical relationships. However, one limitation of CSS selectors is that they can only move down the DOM tree and cannot access parent or sibling elements above a given node. The Class Name locator is helpful for identifying elements grouped under a common class. While it is useful for styling and layout purposes, class names are often shared among multiple elements, which can lead to ambiguity. Tag Name locators allow testers to select elements by their HTML tag, such as all input fields or all images. This approach is broad and typically used when combined with other filters. Finally, Link Text and Partial Link Text locators are specifically useful for anchor elements. They help identify links by matching the visible text, making them ideal for navigation testing. Overall, while XPath excels in handling complex and dynamic structures, combining it with other locators can create more efficient and readable test scripts.
Conclusion
XPath is an essential tool in the Selenium automation toolkit, offering a level of flexibility that is difficult to match with other locator strategies. It allows testers to locate web elements based on a wide range of criteria, including attributes, visible text, hierarchical position, and relationships between elements in the HTML structure. This makes XPath especially valuable when dealing with dynamic or complex web applications where elements may not have fixed or unique identifiers. Although XPath has a learning curve, especially when it comes to mastering its syntax and various functions, the benefits it provides in real-world testing scenarios are substantial. It enables testers to write automation scripts that can adapt to changes in the web page layout, minimizing the need for constant maintenance. XPath can also be combined with conditions and functions to create highly specific and reliable locators, even in the absence of consistent attributes. Following best practices is key to making the most of XPath in Selenium. Using relative XPath rather than absolute paths improves test resilience and reduces dependency on the exact structure of the DOM. Additionally, incorporating XPath functions like contains, starts-with, and text matching can help identify elements that change dynamically or are difficult to locate with simpler strategies. Incorporating XPath into your Selenium tests enhances your ability to interact with a wide range of web elements, making your scripts more adaptable and powerful. Whether you’re testing static websites or complex, data-driven applications, a strong understanding of XPath equips you with the tools needed to navigate and control any HTML structure effectively. This ultimately leads to more stable, maintainable, and reliable automated testing solutions.




