
Last updated on 09th Jul 2020| 2218
Apache Cassandra is a highly scalable, high-performance distributed database designed to handle large amounts of data across many commodity servers, providing high availability with no single point of failure. It is a type of NoSQL database. Let us first understand what a NoSQL database does.
NoSQLDatabaseA NoSQL database (sometimes called as Not Only SQL) is a database that provides a mechanism to store and retrieve data other than the tabular relations used in relational databases. These databases are schema-free, support easy replication, have simple API, eventually consistent, and can handle huge amounts of data.
The primary objective of a NoSQL database is to have
- simplicity of design,
- horizontal scaling, and
- finer control over availability.
NoSql databases use different data structures compared to relational databases. It makes some operations faster in NoSQL. The suitability of a given NoSQL database depends on the problem it must solve.
NoSQL vs. Relational Database
The following table lists the points that differentiate a relational database from a NoSQL database.
| Relational Database | NoSql Database |
|---|---|
| Supports powerful query language. | Supports very simple query language. |
| It has a fixed schema. | No fixed schema. |
| Follows ACID (Atomicity, Consistency, Isolation, and Durability). | It is only “eventually consistent”. |
| Supports transactions. | Does not support transactions. |
Besides Cassandra, we have the following NoSQL databases that are quite popular −
- Apache HBase
HBase is an open source, non-relational, distributed database modeled after Google’s BigTable and is written in Java. It is developed as a part of Apache Hadoop project and runs on top of HDFS, providing BigTable-like capabilities for Hadoop.
- MongoDB
MongoDB is a cross-platform document-oriented database system that avoids using the traditional table-based relational database structure in favor of JSON-like documents with dynamic schemas making the integration of data in certain types of applications easier and faster.
What is Apache Cassandra?Apache Cassandra is an open source, distributed and decentralized/distributed storage system (database), for managing very large amounts of structured data spread out across the world. It provides highly available service with no single point of failure.
Listed below are some of the notable points of Apache Cassandra −
- It is scalable, fault-tolerant, and consistent.
- It is a column-oriented database.
- Its distribution design is based on Amazon’s Dynamo and its data model on Google’s Bigtable.
- Created at Facebook, it differs sharply from relational database management systems.
- Cassandra implements a Dynamo-style replication model with no single point of failure, but adds a more powerful “column family” data model.
- Cassandra is being used by some of the biggest companies such as Facebook, Twitter, Cisco, Rackspace, ebay, Twitter, Netflix, and more.
Cassandra has become so popular because of its outstanding technical features. Given below are some of the features of Cassandra:
- Elastic scalability
Cassandra is highly scalable; it allows to add more hardware to accommodate more customers and more data as per requirement.
- Always on architecture
Cassandra has no single point of failure and it is continuously available for business-critical applications that cannot afford a failure.
- Fast linear-scale performance
Cassandra is linearly scalable, i.e., it increases your throughput as you increase the number of nodes in the cluster. Therefore it maintains a quick response time.
- Flexible data storage
Cassandra accommodates all possible data formats including: structured, semi-structured, and unstructured. It can dynamically accommodate changes to your data structures according to your need.
- Easy data distribution
Cassandra provides the flexibility to distribute data where you need by replicating data across multiple data centers.
- Transaction support
Cassandra supports properties like Atomicity, Consistency, Isolation, and Durability (ACID).
- Fast writes
Cassandra was designed to run on cheap commodity hardware. It performs blazingly fast writes and can store hundreds of terabytes of data, without sacrificing the read efficiency.
Cassandra ArchitectureCassandra was designed to handle big data workloads across multiple nodes without a single point of failure. It has a peer-to-peer distributed system across its nodes, and data is distributed among all the nodes in a cluster.
- In Cassandra, each node is independent and at the same time interconnected to other nodes. All the nodes in a cluster play the same role.
- Every node in a cluster can accept read and write requests, regardless of where the data is actually located in the cluster.
- In the case of failure of one node, Read/Write requests can be served from other nodes in the network.
In Cassandra, nodes in a cluster act as replicas for a given piece of data. If some of the nodes are responded with an out-of-date value, Cassandra will return the most recent value to the client. After returning the most recent value, Cassandra performs a read repair in the background to update the stale values.
See the following image to understand the schematic view of how Cassandra uses data replication among the nodes in a cluster to ensure no single point of failure.
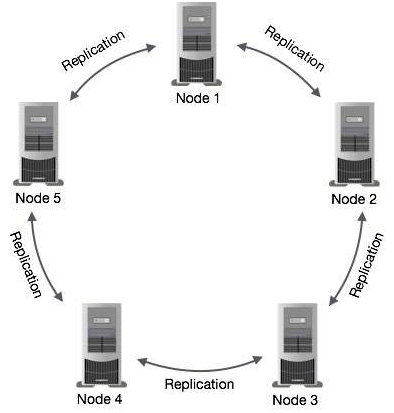
The main components of Cassandra are:
- Node:
A Cassandra node is a place where data is stored.
- Data center:
Data center is a collection of related nodes.
- Cluster:
A cluster is a component which contains one or more data centers.
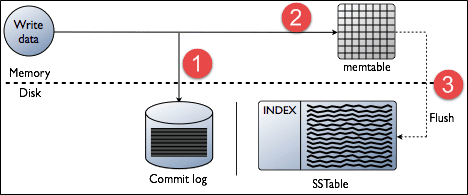
- Commit log:
In Cassandra, the commit log is a crash-recovery mechanism. Every write operation is written to the commit log.
- Mem-table:
A mem-table is a memory-resident data structure. After commit log, the data will be written to the mem-table. Sometimes, for a single-column family, there will be multiple mem-tables.
- SSTable:
It is a disk file to which the data is flushed from the mem-table when its contents reach a threshold value.
- Bloom filter:
These are nothing but quick, nondeterministic, algorithms for testing whether an element is a member of a set. It is a special kind of cache. Bloom filters are accessed after every query.

Take Your Career to Next Level with Appache Cassandra Certification Course
Weekday / Weekend BatchesSee Batch DetailsCassandra Query Language (CQL) is used to access Cassandra through its nodes. CQL treats the database (Keyspace) as a container of tables. Programmers use cqlsh: a prompt to work with CQL or separate application language drivers.
The client can approach any of the nodes for their read-write operations. That node (coordinator) plays a proxy between the client and the nodes holding the data.
Write OperationsEvery write activity of nodes is captured by the commit logs written in the nodes. Later the data will be captured and stored in the mem-table. Whenever the mem-table is full, data will be written into the SStable data file. All writes are automatically partitioned and replicated throughout the cluster. Cassandra periodically consolidates the SSTables, discarding unnecessary data.
Read OperationsIn Read operations, Cassandra gets values from the mem-table and checks the bloom filter to find the appropriate SSTable which contains the required data.
There are three types of read request that is sent to replicas by coordinators.
- Direct request
- Digest request
- Read repair request
The coordinator sends direct request to one of the replicas. After that, the coordinator sends the digest request to the number of replicas specified by the consistency level and checks if the returned data is an updated data.
After that, the coordinator sends digest request to all the remaining replicas. If any node gives out of date value, a background read repair request will update that data. This process is called read repair mechanism.
Cassandra Use Cases/Application
Cassandra is a non-relational database that can be used for different types of applications. Here are some use cases where Cassandra should be preferred.
- Messaging
Cassandra is a great database for the companies that provides Mobile phones and messaging services. These companies have a huge amount of data, so Cassandra is best for them. - Internet of things Application
Cassandra is a great database for the applications where data is coming at very high speed from different devices or sensors. - Product Catalogs and retail apps
Cassandra is used by many retailers for durable shopping cart protection and fast product catalog input and output. - Social Media Analytics and recommendation engine
Cassandra is a great database for many online companies and social media providers for analysis and recommendation to their customers.
Cassandra Architecture
There are following components in the Cassandra;
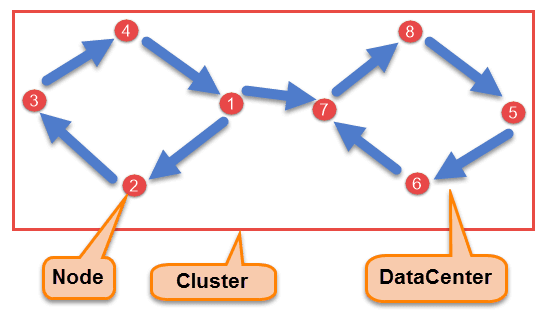
- Node
Node is the place where data is stored. It is the basic component of Cassandra. - Data Center
A collection of nodes are called data center. Many nodes are categorized as a data center. - Cluster
The cluster is the collection of many data centers. - Commit Log
Every write operation is written to Commit Log. Commit log is used for crash recovery. - Mem-table
After data written in Commit log, data is written in Mem-table. Data is written in Mem-table temporarily. - SSTable
When Mem-table reaches a certain threshold, data is flushed to an SSTable disk file.
As hardware problem can occur or link can be down at any time during data process, a solution is required to provide a backup when the problem has occurred. So data is replicated for assuring no single point of failure.
Cassandra places replicas of data on different nodes based on these two factors.
- Where to place next replica is determined by the Replication Strategy.
- While the total number of replicas placed on different nodes is determined by the Replication Factor.
One Replication factor means that there is only a single copy of data while three replication factor means that there are three copies of the data on three different nodes.
For ensuring there is no single point of failure, replication factor must be three.
There are two kinds of replication strategies in Cassandra.
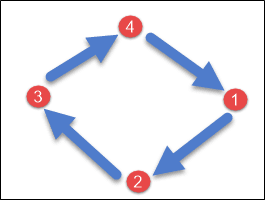
SimpleStrategySimpleStrategy is used when you have just one data center. SimpleStrategy places the first replica on the node selected by the partitioner. After that, remaining replicas are placed in clockwise direction in the Node ring.
Here is the pictorial representation of the SimpleStrategy.
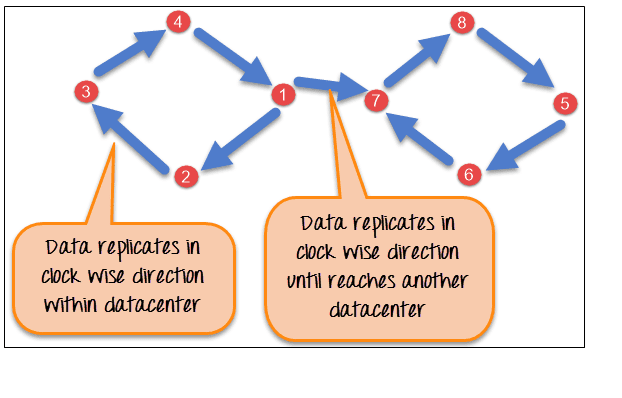
NetworkTopologyStrategy is used when you have more than two data centers.
In NetworkTopologyStrategy, replicas are set for each data center separately. NetworkTopologyStrategy places replicas in the clockwise direction in the ring until reaches the first node in another rack.
This strategy tries to place replicas on different racks in the same data center. This is due to the reason that sometimes failure or problem can occur in the rack. Then replicas on other nodes can provide data.
Here is the pictorial representation of the Network topology strategy
The coordinator sends a write request to replicas. If all the replicas are up, they will receive write request regardless of their consistency level.
Consistency level determines how many nodes will respond back with the success acknowledgment.
The node will respond back with the success acknowledgment if data is written successfully to the commit log and memTable.
For example, in a single data center with replication factor equals to three, three replicas will receive write request. If consistency level is one, only one replica will respond back with the success acknowledgment, and the remaining two will remain dormant.
Suppose if remaining two replicas lose data due to node downs or some other problem, Cassandra will make the row consistent by the built-in repair mechanism in Cassandra.
Here it is explained, how write process occurs in Cassandra,
- When write request comes to the node, first of all, it logs in the commit log.
- Then Cassandra writes the data in the mem-table. Data written in the mem-table on each write request also writes in commit log separately. Mem-table is a temporarily stored data in the memory while Commit log logs the transaction records for back up purposes.
- When mem-table is full, data is flushed to the SSTable data file.
There are three types of read requests that a coordinator sends to replicas.
- Direct request
- Digest request
- Read repair request
The coordinator sends direct request to one of the replicas. After that, the coordinator sends the digest request to the number of replicas specified by the consistency level and checks whether the returned data is an updated data.
After that, the coordinator sends digest request to all the remaining replicas. If any node gives out of date value, a background read repair request will update that data. This process is called read repair mechanism.
Cassandra Data Model RulesIn Cassandra, writes are not expensive. Cassandra does not support joins, group by, OR clause, aggregations, etc. So you have to store your data in such a way that it should be completely retrievable. So these rules must be kept in mind while modelling data in Cassandra.
- Maximize the number of writes
In Cassandra, writes are very cheap. Cassandra is optimized for high write performance. So try to maximize your writes for better read performance and data availability. There is a tradeoff between data write and data read. So, optimize you data read performance by maximizing the number of data writes. - Maximize Data Duplication
Data denormalization and data duplication are defacto of Cassandra. Disk space is not more expensive than memory, CPU processing and IOs operation. As Cassandra is a distributed database, so data duplication provides instant data availability and no single point of failure.
You should have the following goals while modelling data in Cassandra.
- Spread Data Evenly Around the Cluster
You want an equal amount of data on each node of the Cassandra cluster. Data is spread to different nodes based on partition keys that is the first part of the primary key. So, try to choose integers as a primary key for spreading data evenly around the cluster. - Minimize number of partitions read while querying data
Partitions are a group of records with the same partition key. When the read query is issued, it collects data from different nodes from different partitions.
If there will be many partitions, then all these partitions need to be visited for collecting the query data. It does not mean that partitions should not be created. If your data is very large, you can’t keep that huge amount of data on the single partition. The single partition will be slowed down.
Conclusion
Apache Cassandra is used for community purposes. This tutorial shows the Apache Cassandra installation step by step. Also discussed what are the pre -requisites to access Cassandra. Cassandra is designed to handle big data. Cassandra’s main feature is to store data on multiple nodes with no single point of failure.
The reason for this kind of Cassandra’s architecture was that the hardware failure can occur at any time. Any node can be down. In case of failure data stored in another node can be used. Hence, Cassandra is designed with its distributed architecture.




