
Last updated on 09th Jul 2020| 2983
Apache Kafka is a software platform which is based on a distributed streaming process. It is a publish-subscribe messaging system which lets exchanging of data between applications, servers, and processors as well. Apache Kafka was originally developed by LinkedIn, and later it was donated to the Apache Software Foundation. Currently, it is maintained by Confluent under Apache Software Foundation. Apache Kafka has resolved the lethargic trouble of data communication between a sender and a receiver.
Apache Kafka Architecture
We have already learned the basic concepts of Apache Kafka. These basic concepts, such as Topics, partitions, producers, consumers, etc., together forms the Kafka architecture.
As different applications design the architecture of Kafka accordingly, there are the following essential parts required to design Apache Kafka architecture.
o Data Ecosystem:
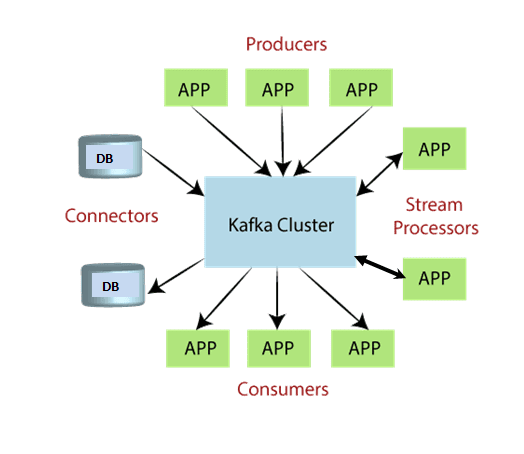
Several applications that use Apache Kafka forms an ecosystem. This ecosystem is built for data processing. It takes inputs in the form of applications that create data, and outputs are defined in the form of metrics, reports, etc. The below diagram represents a circulatory data ecosystem for Kafka.
o Kafka Cluster:
A Kafka cluster is a system that comprises of different brokers, topics, and their respective partitions. Data is written to the topic within the cluster and read by the cluster itself.
o Producers:
A producer sends or writes data/messages to the topic within the cluster. In order to store a huge amount of data, different producers within an application send data to the Kafka cluster.
o Consumers:
A consumer is the one that reads or consumes messages from the Kafka cluster. There can be several consumers consuming different types of data form the cluster. The beauty of Kafka is that each consumer knows from where it needs to consume the data.
o Brokers:
A Kafka server is known as a broker. A broker is a bridge between producers and consumers. If a producer wishes to write data to the cluster, it is sent to the Kafka server. All brokers lie within a Kafka cluster itself. Also, there can be multiple brokers.
o Topics:
It is a common name or a heading given to represent a similar type of data. In Apache Kafka, there can be multiple topics in a cluster. Each topic specifies different types of messages.
o Partitions:
The data or message is divided into small subparts, known as partitions. Each partition carries data within it having an offset value. The data is always written in a sequential manner. We can have an infinite number of partitions with infinite offset values. However, it is not guaranteed to which partition the message will be written.
o ZooKeeper:
A ZooKeeper is used to store information about the Kafka cluster and details of the consumer clients. It manages brokers by maintaining a list of them. Also, a ZooKeeper is responsible for choosing a leader for the partitions. If any changes like a broker die, new topics, etc., occurs, the ZooKeeper sends notifications to Apache Kafka. A ZooKeeper is designed to operate with an odd number of Kafka servers. Zookeeper has a leader server that handles all the writes, and rest of the servers are the followers who handle all the reads. However, a user does not directly interact with the Zookeeper, but via brokers. No Kafka server can run without a zookeeper server. It is mandatory to run the zookeeper server.
In the above figure, there are three zookeeper servers where server 2 is the leader, and the other two are chosen as its followers. The five brokers are connected to these servers. Automatically, the Kafka cluster will come to know when brokers are down, more topics are added, etc..
Hence, on combining all the necessities, a Kafka cluster architecture is designed.
What is a messaging system?
A messaging system is a simple exchange of messages between two or more persons, devices, etc. A publish-subscribe messaging system allows a sender to send/write the message and a receiver to read that message. In Apache Kafka, a sender is known as a producer who publishes messages, and a receiver is known as a consumer who consumes that message by subscribing it.
What is Streaming process?
A streaming process is the processing of data in parallelly connected systems. This process allows different applications to limit the parallel execution of the data, where one record executes without waiting for the output of the previous record. Therefore, a distributed streaming platform enables the user to simplify the task of the streaming process and parallel execution. Therefore, a streaming platform in Kafka has the following key capabilities:
- As soon as the streams of records occur, it processes it.
- It works similar to an enterprise messaging system where it publishes and subscribes streams of records.
- It stores the streams of records in a fault-tolerant durable way.
To learn and understand Apache Kafka, the aspirants should know the following four core APIs :
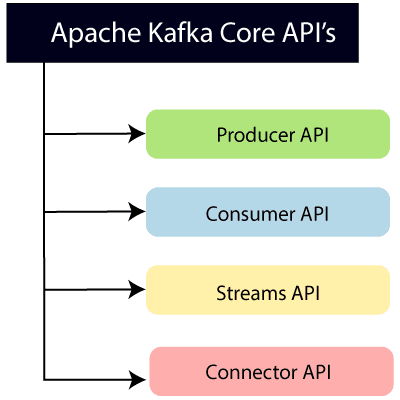
Producer API:
This API allows/permits an application to publish streams of records to one or more topics. (discussed in later section)
Consumer API:
This API allows an application to subscribe one or more topics and process the stream of records produced to them.

Take Your Career to Next Level with Kafka Training to Advance Your Career
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
Streams API:
This API allows an application to effectively transform the input streams to the output streams. It permits an application to act as a stream processor which consumes an input stream from one or more topics, and produce an output stream to one or more output topics.
Connector API:
This API executes the reusable producer and consumer APIs with the existing data systems or applications.
Why Apache Kafka?

Apache Kafka is a software platform that has the following reasons which best describes the need of Apache Kafka.
- Apache Kafka is capable of handling millions of data or messages per second.
- Apache Kafka works as a mediator between the source system and the target system. Thus, the source system (producer) data is sent to the Apache Kafka, where it decouples the data, and the target system (consumer) consumes the data from Kafka.
- Apache Kafka is having extremely high performance, i.e., it has really low latency value less than 10ms which proves it as a well-versed software.
- Apache Kafka has a resilient architecture which has resolved unusual complications in data sharing.
- Organizations such as NETFLIX, UBER, Walmart, etc. and over thousands of such firms make use of Apache Kafka.
- Apache Kafka is able to maintain the fault-tolerance. Fault-tolerance means that sometimes a consumer successfully consumes the message that was delivered by the producer. But, the consumer fails to process the message back due to backend database failure, or due to presence of a bug in the consumer code. In such a situation, the consumer is unable to consume the message again. Consequently, Apache Kafka has resolved the problem by reprocessing the data.
- Learning Kafka is a good source of income. So, those who wish to raise their income in future in IT sector can learn.
Kafka Topics
In the previous section, we have taken a brief introduction about Apache Kafka, messaging system, as well as the streaming process. Here, we will discuss the basic concepts and the role of Kafka.
Topics
Generally, a topic refers to a particular heading or a name given to some specific inter-related ideas. In Kafka, the word topic refers to a category or a common name used to store and publish a particular stream of data. Basically, topics in Kafka are similar to tables in the database, but not containing all constraints. In Kafka, we can create n number of topics as we want. It is identified by its name, which depends on the user’s choice. A producer publishes data to the topics, and a consumer reads that data from the topic by subscribing it.
Partitions
A topic is split into several parts which are known as the partitions of the topic. These partitions are separated in an order. The data content gets stored in the partitions within the topic. Therefore, while creating a topic, we need to specify the number of partitions(the number is arbitrary and can be changed later). Each message gets stored into partitions with an incremental id known as its Offset value. The order of the offset value is guaranteed within the partition only and not across the partition. The offsets for a partition are infinite.
Let’s see an example to understand a topic with its partitions.
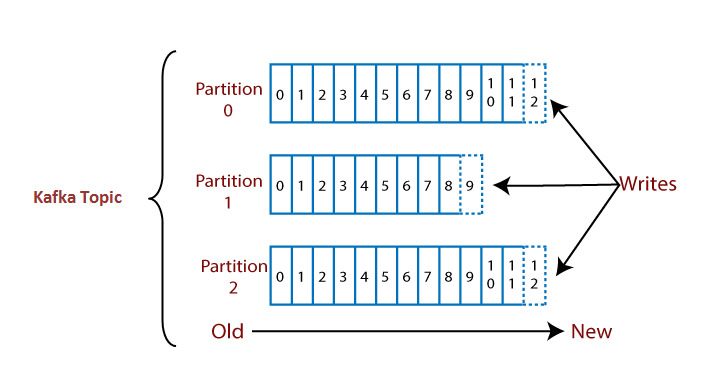
Suppose, a topic containing three partitions 0,1 and 2. Each partition has different offset numbers. The data is distributed among each offset in each partition where data in offset 1 of Partition 0 does not have any relation with the data in offset 1 of Partition1. But, data in offset 1of Partition 0 is inter-related with the data contained in offset 2 of Partition0.
Brokers
Here, comes the role of Apache Kafka.
A Kafka cluster is comprised of one or more servers which are known as brokers or Kafka brokers. A broker is a container that holds several topics with their multiple partitions. The brokers in the cluster are identified by an integer id only. Kafka brokers are also known as Bootstrap brokers because connection with any one broker means connection with the entire cluster. Although a broker does not contain whole data, but each broker in the cluster knows about all other brokers, partitions as well as topics.
Kafka Topics
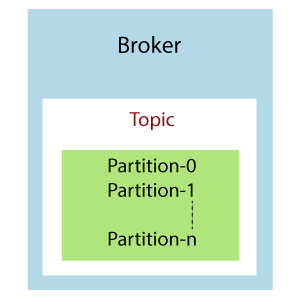
This is how a broker looks like in the figure containing a topic with n number of partitions.
Example: Brokers and Topics
Suppose, a Kafka cluster consisting of three brokers, namely Broker 1, Broker 2, and Broker 3.
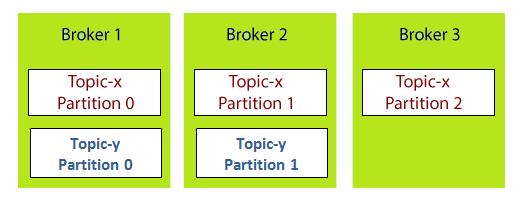
Kafka Topics
Each broker is holding a topic, namely Topic-x with three partitions 0,1 and 2. Remember, all partitions do not belong to one broker only, it is always distributed among each broker (depends on the quantity). Broker 1 and Broker 2 contains another topic-y having two partitions 0 and 1. Thus, Broker 3 does not hold any data from Topic-y. It is also concluded that no relationship ever exists between the broker number and the partition number.
Apache Kafka Applications
The demand for Apache Kafka is increasing at a tremendous speed. Many best enterprises today make use of Kafka to ease and grow their data pipelining requirements.
There are following applications of Apache Kafka:
Let’s discuss each application one by one:
In 2010, LinkedIn developed Apache Kafka. As Kafka is a publish-subscriber messaging system, thus various LinkedIn products such as LinkedIn Today and LinkedIn Newsfeed use it for message consumption.
Uber
Uber use Kafka as a message bus to connect different parts of the ecosystem. Kafka helps both the passengers and drivers to meet to their correct matches. It collects information from the rider’s app as well as from the driver’s app, then makes that information available to a variety of downstream consumers.
Because Kafka has fulfilled the requirements of data replication and durability, twitter has become one of the best applications/users of Apache Kafka. Adopting Kafka led twitter to a vast resource saving, upto 75%, i.e., a good cost reduction.

Best Kafka Certification Course with Industry Standard Topics From Real-Time Experts
Weekday / Weekend BatchesSee Batch DetailsNetflix
Netflix uses Kafka under Keystone Pipeline. A Keystone is a unified collection, event publishing, and routing infrastructure used for stream and batch processing. The Keystone Pipeline uses two sets of Kafka cluster, i.e., Fronting Kafka and Consumer Kafka. Fronting Kafka gets the message from the producers. Consumer Kafka contains topics subsets which are routed by Samza (an Apache framework) for the real-time consumers. Thus, Kafka has maintained the cost by providing a lossless delivery of the data pipeline.
Oracle
Apache Kafka has supported Oracle Database as a Kafka Consumer. It has also supported Oracle for publishing events to Kafka. Apache Kafka provides reliable and scalable data streaming. The oracle user can easily retrieve data from a Kafka topic. Oracle developers are now more capable of implementing staged data pipelines through OSB(Oracle Service Bus).
Mozilla
Mozilla Firefox is an open-source and free web browser to all. It supports Windows, Linux, macOS, and many other operating systems. Mozilla uses Kafka for backing up the data, i.e., used as a backing data store. Soon, Kafka is going to replace Mozilla’s current production system for collecting performance and usage data from the end users for Telemetry, Test Pilot like projects.
Kafka: Advantages and Disadvantages

Advantages of Apache Kafka
Following advantages of Apache Kafka makes it worthy:
Low Latency:
Apache Kafka offers low latency value, i.e., upto 10 milliseconds. It is because it decouples the message which lets the consumer to consume that message anytime.
High Throughput:
Due to low latency, Kafka is able to handle more number of messages of high volume and high velocity. Kafka can support thousands of messages in a second. Many companies such as Uber use Kafka to load a high volume of data.
Fault tolerance:
Kafka has an essential feature to provide resistant to node/machine failure within the cluster.
Durability:
Kafka offers the replication feature, which makes data or messages to persist more on the cluster over a disk. This makes it durable.
Reduces the need for multiple integrations:
All the data that a producer writes go through Kafka. Therefore, we just need to create one integration with Kafka, which automatically integrates us with each producing and consuming system.
Easily accessible:
As all our data gets stored in Kafka, it becomes easily accessible to anyone.
Distributed System:
Apache Kafka contains a distributed architecture which makes it scalable. Partitioning and replication are the two capabilities under the distributed system.
Real-Time handling:
Apache Kafka is able to handle real-time data pipeline. Building a real-time data pipeline includes processors, analytics, storage, etc.
Batch approach:
Kafka uses batch-like use cases. It can also work like an ETL tool because of its data persistence capability.
Scalability:
The quality of Kafka to handle large amount of messages simultaneously make it a scalable software product.
Disadvantages Of Apache Kafka
With the above advantages, there are following limitations/disadvantages of Apache Kafka:
Do not have complete set of monitoring tools:
Apache Kafka does not contain a complete set of monitoring as well as managing tools. Thus, new startups or enterprises fear to work with Kafka.
Message tweaking issues:
The Kafka broker uses system calls to deliver messages to the consumer. In case, the message needs some tweaking, the performance of Kafka gets significantly reduced. So, it works well if the message does not need to change.
Do not support wildcard topic selection:
Apache Kafka does not support wildcard topic selection. Instead, it matches only the exact topic name. It is because selecting wildcard topics make it incapable to address certain use cases.
Reduces Performance:
Brokers and consumers reduce the performance of Kafka by compressing and decompressing the data flow. This not only affects its performance but also affects its throughput.
Clumsy Behaviour:
Apache Kafka most often behaves a bit clumsy when the number of queues increases in the Kafka Cluster.
Lack some message paradigms:
Certain message paradigms such as point-to-point queues, request/reply, etc. are missing in Kafka for some use cases.
Conclusion
The final result of the performance of this Kafka system totally depends on how much accuracy occurs in data delivery. The performance depends on the delivery of every message to its consumer correctly, on time without more lag of time.




